 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Causal Importance from Emergent Structure in Multi-Expert Orchestration
Feb 04, 2026Multi-expert systems, where multiple Large Language Models (LLMs) collaborate to solve complex tasks, are increasingly adopted for high-performance reasoning and generation. However, the orchestration policies governing expert interaction and sequencing remain largely opaque. We introduce INFORM, an interpretability analysis that treats orchestration as an explicit, analyzable computation, enabling the decoupling of expert interaction structure, execution order, and causal attribution. We use INFORM to evaluate an orchestrator on GSM8K, HumanEval, and MMLU using a homogeneous consortium of ten instruction-tuned experts drawn from LLaMA-3.1 8B, Qwen-3 8B, and DeepSeek-R1 8B, with controlled decoding-temperature variation, and a secondary heterogeneous consortium spanning 1B-7B parameter models. Across tasks, routing dominance is a poor proxy for functional necessity. We reveal a divergence between relational importance, captured by routing mass and interaction topology, and intrinsic importance, measured via gradient-based causal attribution: frequently selected experts often act as interaction hubs with limited causal influence, while sparsely routed experts can be structurally critical. Orchestration behaviors emerge asynchronously, with expert centralization preceding stable routing confidence and expert ordering remaining non-deterministic. Targeted ablations show that masking intrinsically important experts induces disproportionate collapse in interaction structure compared to masking frequent peers, confirming that INFORM exposes causal and structural dependencies beyond accuracy metrics alone.
ICPR 2024 Competition on Safe Segmentation of Drive Scenes in Unstructured Traffic and Adverse Weather Conditions
Sep 09, 2024
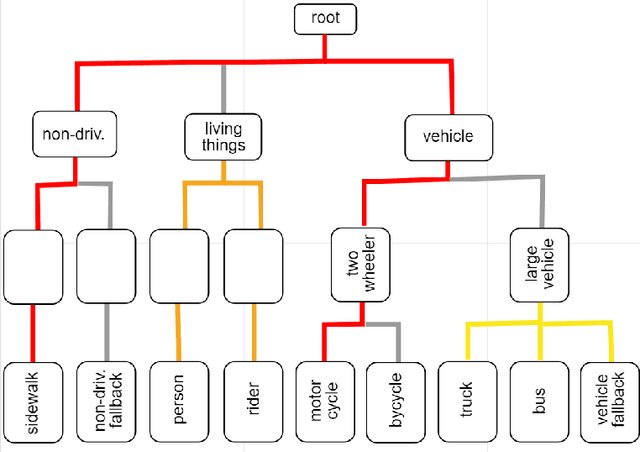
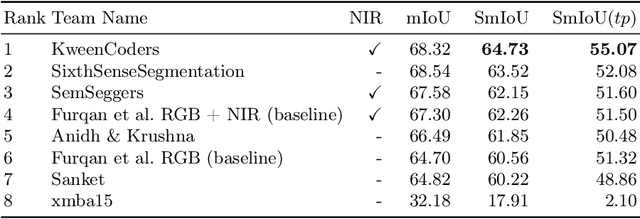
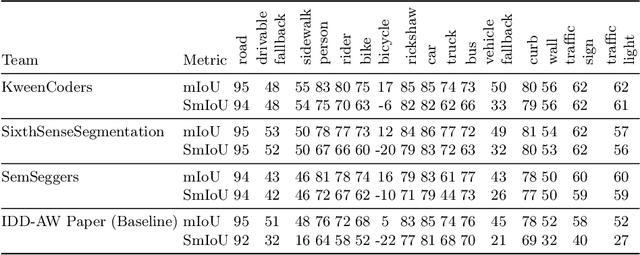
The ICPR 2024 Competition on Safe Segmentation of Drive Scenes in Unstructured Traffic and Adverse Weather Conditions served as a rigorous platform to evaluate and benchmark state-of-the-art semantic segmentation models under challenging conditions for autonomous driving. Over several months, participants were provided with the IDD-AW dataset, consisting of 5000 high-quality RGB-NIR image pairs, each annotated at the pixel level and captured under adverse weather conditions such as rain, fog, low light, and snow. A key aspect of the competition was the use and improvement of the Safe mean Intersection over Union (Safe mIoU) metric, designed to penalize unsafe incorrect predictions that could be overlooked by traditional mIoU. This innovative metric emphasized the importance of safety in developing autonomous driving systems. The competition showed significant advancements in the field, with participants demonstrating models that excelled in semantic segmentation and prioritized safety and robustness in unstructured and adverse conditions. The results of the competition set new benchmarks in the domain, highlighting the critical role of safety in deploying autonomous vehicles in real-world scenarios. The contributions from this competition are expected to drive further innovation in autonomous driving technology, addressing the critical challenges of operating in diverse and unpredictable environments.
Frugal LMs Trained to Invoke Symbolic Solvers Achieve Parameter-Efficient Arithmetic Reasoning
Dec 19, 2023



Large Language Models (LLM) exhibit zero-shot mathematical reasoning capacity as a behavior emergent with scale, commonly manifesting as chain-of-thoughts (CoT) reasoning. However, multiple empirical findings suggest that this prowess is exclusive to LLMs with exorbitant sizes (beyond 50 billion parameters). Meanwhile, educational neuroscientists suggest that symbolic algebraic manipulation be introduced around the same time as arithmetic word problems to modularize language-to-formulation, symbolic manipulation of the formulation, and endgame arithmetic. In this paper, we start with the hypothesis that much smaller LMs, which are weak at multi-step reasoning, can achieve reasonable arithmetic reasoning if arithmetic word problems are posed as a formalize-then-solve task. In our architecture, which we call SYRELM, the LM serves the role of a translator to map natural language arithmetic questions into a formal language (FL) description. A symbolic solver then evaluates the FL expression to obtain the answer. A small frozen LM, equipped with an efficient low-rank adapter, is capable of generating FL expressions that incorporate natural language descriptions of the arithmetic problem (e.g., variable names and their purposes, formal expressions combining variables, etc.). We adopt policy-gradient reinforcement learning to train the adapted LM, informed by the non-differentiable symbolic solver. This marks a sharp departure from the recent development in tool-augmented LLMs, in which the external tools (e.g., calculator, Web search, etc.) are essentially detached from the learning phase of the LM. SYRELM shows massive improvements (e.g., +30.65 absolute point improvement in accuracy on the SVAMP dataset using GPT-J 6B model) over base LMs, while keeping our testbed easy to diagnose, interpret and within reach of most researchers.
IDD-AW: A Benchmark for Safe and Robust Segmentation of Drive Scenes in Unstructured Traffic and Adverse Weather
Nov 24, 2023



Large-scale deployment of fully autonomous vehicles requires a very high degree of robustness to unstructured traffic, and weather conditions, and should prevent unsafe mispredictions. While there are several datasets and benchmarks focusing on segmentation for drive scenes, they are not specifically focused on safety and robustness issues. We introduce the IDD-AW dataset, which provides 5000 pairs of high-quality images with pixel-level annotations, captured under rain, fog, low light, and snow in unstructured driving conditions. As compared to other adverse weather datasets, we provide i.) more annotated images, ii.) paired Near-Infrared (NIR) image for each frame, iii.) larger label set with a 4-level label hierarchy to capture unstructured traffic conditions. We benchmark state-of-the-art models for semantic segmentation in IDD-AW. We also propose a new metric called ''Safe mean Intersection over Union (Safe mIoU)'' for hierarchical datasets which penalizes dangerous mispredictions that are not captured in the traditional definition of mean Intersection over Union (mIoU). The results show that IDD-AW is one of the most challenging datasets to date for these tasks. The dataset and code will be available here: http://iddaw.github.io.
Small Language Models Fine-tuned to Coordinate Larger Language Models improve Complex Reasoning
Oct 21, 2023



Large Language Models (LLMs) prompted to generate chain-of-thought (CoT) exhibit impressive reasoning capabilities. Recent attempts at prompt decomposition toward solving complex, multi-step reasoning problems depend on the ability of the LLM to simultaneously decompose and solve the problem. A significant disadvantage is that foundational LLMs are typically not available for fine-tuning, making adaptation computationally prohibitive. We believe (and demonstrate) that problem decomposition and solution generation are distinct capabilites, better addressed in separate modules, than by one monolithic LLM. We introduce DaSLaM, which uses a decomposition generator to decompose complex problems into subproblems that require fewer reasoning steps. These subproblems are answered by a solver. We use a relatively small (13B parameters) LM as the decomposition generator, which we train using policy gradient optimization to interact with a solver LM (regarded as black-box) and guide it through subproblems, thereby rendering our method solver-agnostic. Evaluation on multiple different reasoning datasets reveal that with our method, a 175 billion parameter LM (text-davinci-003) can produce competitive or even better performance, compared to its orders-of-magnitude larger successor, GPT-4. Additionally, we show that DaSLaM is not limited by the solver's capabilities as a function of scale; e.g., solver LMs with diverse sizes give significant performance improvement with our solver-agnostic decomposition technique. Exhaustive ablation studies evince the superiority of our modular finetuning technique over exorbitantly large decomposer LLMs, based on prompting alone.
Semantic Map Injected GAN Training for Image-to-Image Translation
Dec 03, 2021
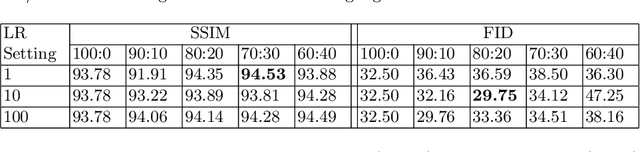

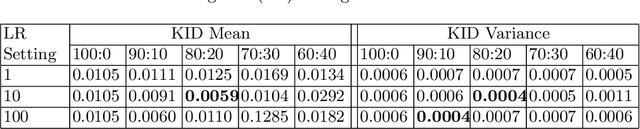
Image-to-image translation is the recent trend to transform images from one domain to another domain using generative adversarial network (GAN). The existing GAN models perform the training by only utilizing the input and output modalities of transformation. In this paper, we perform the semantic injected training of GAN models. Specifically, we train with original input and output modalities and inject a few epochs of training for translation from input to semantic map. Lets refer the original training as the training for the translation of input image into target domain. The injection of semantic training in the original training improves the generalization capability of the trained GAN model. Moreover, it also preserves the categorical information in a better way in the generated image. The semantic map is only utilized at the training time and is not required at the test time. The experiments are performed using state-of-the-art GAN models over CityScapes and RGB-NIR stereo datasets. We observe the improved performance in terms of the SSIM, FID and KID scores after injecting semantic training as compared to original training.