 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Signal Adaptive KV-Cache Optimization for Long-Form Video Understanding in Vision-Language Models
Feb 15, 2026Vision-Language Models (VLMs) face a critical memory bottleneck when processing long-form video content due to the linear growth of the Key-Value (KV) cache with sequence length. Existing solutions predominantly employ reactive eviction strategies that compute full attention matrices before discarding tokens, resulting in substantial computational waste. We propose Sali-Cache, a novel a priori optimization framework that implements dual-signal adaptive caching through proactive memory management. By integrating a temporal filter based on optical flow analysis for detecting inter-frame redundancy and a spatial filter leveraging saliency detection for identifying visually significant regions, Sali-Cache intelligently manages memory allocation before entering computationally expensive attention operations. Experimental evaluation on the LLaVA 1.6 architecture demonstrates that our method achieves a 2.20x compression ratio in effective memory usage while maintaining 100% accuracy across BLEU, ROUGE-L, and Exact Match metrics. Furthermore, under identical memory budget constraints, Sali-Cache preserves context-rich features over extended temporal durations without degrading model performance, enabling efficient processing of long-form video content on consumer-grade hardware.
Distributed Perceptron under Bounded Staleness, Partial Participation, and Noisy Communication
Jan 15, 2026We study a semi-asynchronous client-server perceptron trained via iterative parameter mixing (IPM-style averaging): clients run local perceptron updates and a server forms a global model by aggregating the updates that arrive in each communication round. The setting captures three system effects in federated and distributed deployments: (i) stale updates due to delayed model delivery and delayed application of client computations (two-sided version lag), (ii) partial participation (intermittent client availability), and (iii) imperfect communication on both downlink and uplink, modeled as effective zero-mean additive noise with bounded second moment. We introduce a server-side aggregation rule called staleness-bucket aggregation with padding that deterministically enforces a prescribed staleness profile over update ages without assuming any stochastic model for delays or participation. Under margin separability and bounded data radius, we prove a finite-horizon expected bound on the cumulative weighted number of perceptron mistakes over a given number of server rounds: the impact of delay appears only through the mean enforced staleness, whereas communication noise contributes an additional term that grows on the order of the square root of the horizon with the total noise energy. In the noiseless case, we show how a finite expected mistake budget yields an explicit finite-round stabilization bound under a mild fresh-participation condition.
Parallel Backpropagation for Inverse of a Convolution with Application to Normalizing Flows
Oct 18, 2024
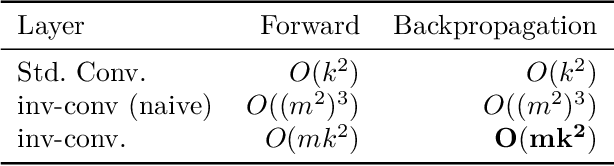
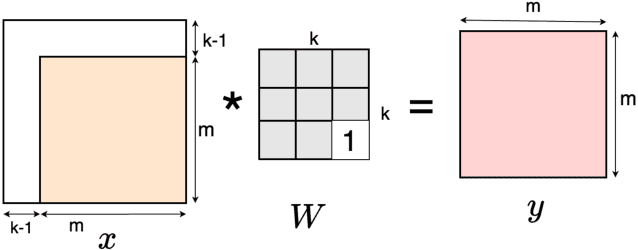
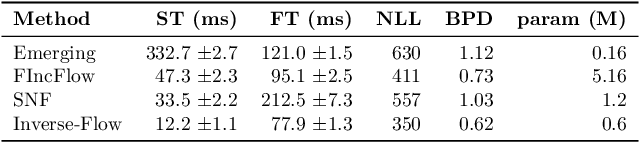
Inverse of an invertible convolution is an important operation that comes up in Normalizing Flows, Image Deblurring, etc. The naive algorithm for backpropagation of this operation using Gaussian elimination has running time $O(n^3)$ where $n$ is the number of pixels in the image. We give a fast parallel backpropagation algorithm with running time $O(\sqrt{n})$ for a square image and provide a GPU implementation of the same. Inverse Convolutions are usually used in Normalizing Flows in the sampling pass, making them slow. We propose to use Inverse Convolutions in the forward (image to latent vector) pass of the Normalizing flow. Since the sampling pass is the inverse of the forward pass, it will use convolutions only, resulting in efficient sampling times. We use our parallel backpropagation algorithm for optimizing the inverse convolution layer resulting in fast training times also. We implement this approach in various Normalizing Flow backbones, resulting in our Inverse-Flow models. We benchmark Inverse-Flow on standard datasets and show significantly improved sampling times with similar bits per dimension compared to previous models.
ICPR 2024 Competition on Safe Segmentation of Drive Scenes in Unstructured Traffic and Adverse Weather Conditions
Sep 09, 2024
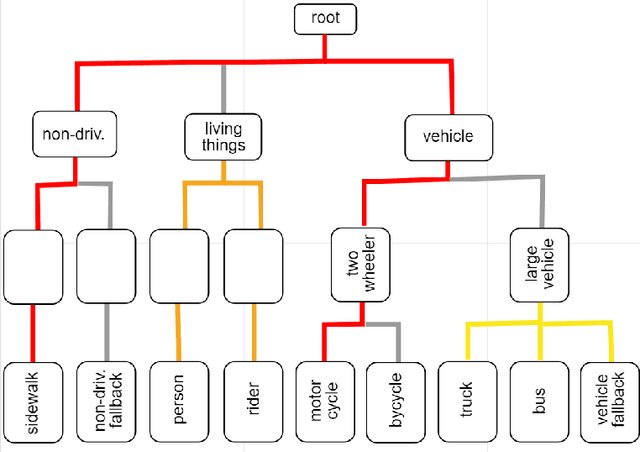
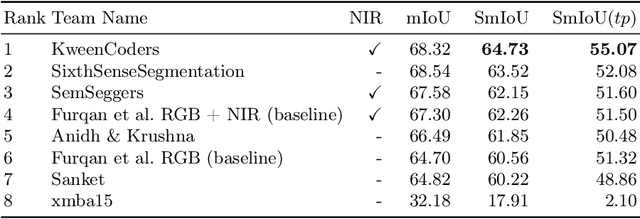
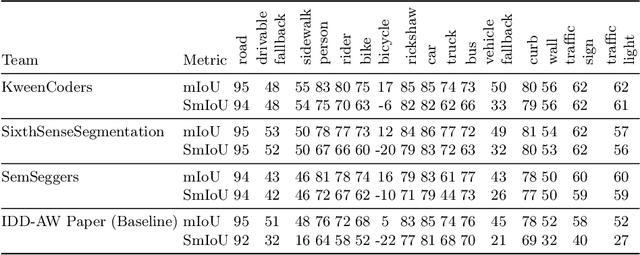
The ICPR 2024 Competition on Safe Segmentation of Drive Scenes in Unstructured Traffic and Adverse Weather Conditions served as a rigorous platform to evaluate and benchmark state-of-the-art semantic segmentation models under challenging conditions for autonomous driving. Over several months, participants were provided with the IDD-AW dataset, consisting of 5000 high-quality RGB-NIR image pairs, each annotated at the pixel level and captured under adverse weather conditions such as rain, fog, low light, and snow. A key aspect of the competition was the use and improvement of the Safe mean Intersection over Union (Safe mIoU) metric, designed to penalize unsafe incorrect predictions that could be overlooked by traditional mIoU. This innovative metric emphasized the importance of safety in developing autonomous driving systems. The competition showed significant advancements in the field, with participants demonstrating models that excelled in semantic segmentation and prioritized safety and robustness in unstructured and adverse conditions. The results of the competition set new benchmarks in the domain, highlighting the critical role of safety in deploying autonomous vehicles in real-world scenarios. The contributions from this competition are expected to drive further innovation in autonomous driving technology, addressing the critical challenges of operating in diverse and unpredictable environments.
IDD-AW: A Benchmark for Safe and Robust Segmentation of Drive Scenes in Unstructured Traffic and Adverse Weather
Nov 24, 2023



Large-scale deployment of fully autonomous vehicles requires a very high degree of robustness to unstructured traffic, and weather conditions, and should prevent unsafe mispredictions. While there are several datasets and benchmarks focusing on segmentation for drive scenes, they are not specifically focused on safety and robustness issues. We introduce the IDD-AW dataset, which provides 5000 pairs of high-quality images with pixel-level annotations, captured under rain, fog, low light, and snow in unstructured driving conditions. As compared to other adverse weather datasets, we provide i.) more annotated images, ii.) paired Near-Infrared (NIR) image for each frame, iii.) larger label set with a 4-level label hierarchy to capture unstructured traffic conditions. We benchmark state-of-the-art models for semantic segmentation in IDD-AW. We also propose a new metric called ''Safe mean Intersection over Union (Safe mIoU)'' for hierarchical datasets which penalizes dangerous mispredictions that are not captured in the traditional definition of mean Intersection over Union (mIoU). The results show that IDD-AW is one of the most challenging datasets to date for these tasks. The dataset and code will be available here: http://iddaw.github.io.
City-scale Pollution Aware Traffic Routing by Sampling Max Flows using MCMC
Feb 28, 2023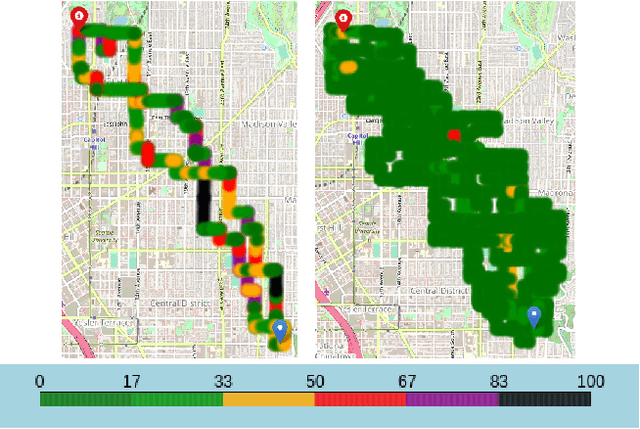
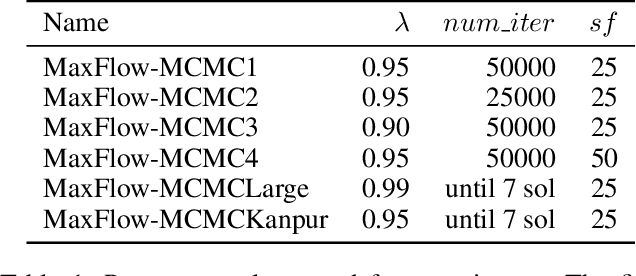
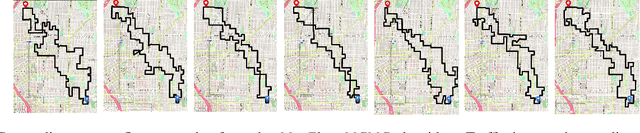
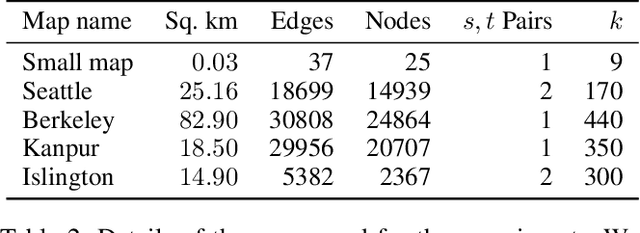
A significant cause of air pollution in urban areas worldwide is the high volume of road traffic. Long-term exposure to severe pollution can cause serious health issues. One approach towards tackling this problem is to design a pollution-aware traffic routing policy that balances multiple objectives of i) avoiding extreme pollution in any area ii) enabling short transit times, and iii) making effective use of the road capacities. We propose a novel sampling-based approach for this problem. We provide the first construction of a Markov Chain that can sample integer max flow solutions of a planar graph, with theoretical guarantees that the probabilities depend on the aggregate transit length. We designed a traffic policy using diverse samples and simulated traffic on real-world road maps using the SUMO traffic simulator. We observe a considerable decrease in areas with severe pollution when experimented with maps of large cities across the world compared to other approaches.
FInC Flow: Fast and Invertible $k \times k$ Convolutions for Normalizing Flows
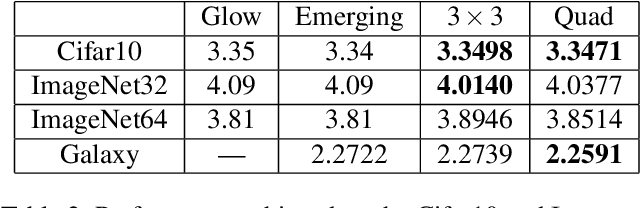
Jan 23, 2023Invertible convolutions have been an essential element for building expressive normalizing flow-based generative models since their introduction in Glow. Several attempts have been made to design invertible $k \times k$ convolutions that are efficient in training and sampling passes. Though these attempts have improved the expressivity and sampling efficiency, they severely lagged behind Glow which used only $1 \times 1$ convolutions in terms of sampling time. Also, many of the approaches mask a large number of parameters of the underlying convolution, resulting in lower expressivity on a fixed run-time budget. We propose a $k \times k$ convolutional layer and Deep Normalizing Flow architecture which i.) has a fast parallel inversion algorithm with running time O$(n k^2)$ ($n$ is height and width of the input image and k is kernel size), ii.) masks the minimal amount of learnable parameters in a layer. iii.) gives better forward pass and sampling times comparable to other $k \times k$ convolution-based models on real-world benchmarks. We provide an implementation of the proposed parallel algorithm for sampling using our invertible convolutions on GPUs. Benchmarks on CIFAR-10, ImageNet, and CelebA datasets show comparable performance to previous works regarding bits per dimension while significantly improving the sampling time.
* accepted: VISAPP'23
Automated Seed Quality Testing System using GAN & Active Learning
Oct 02, 2021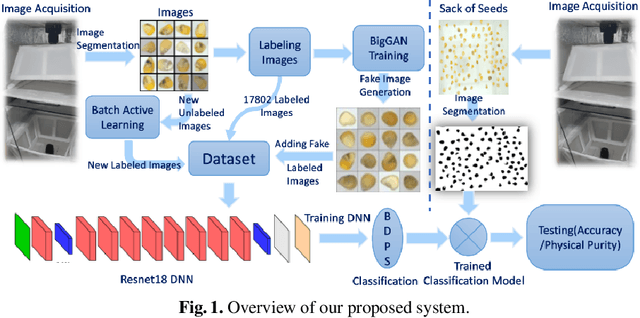
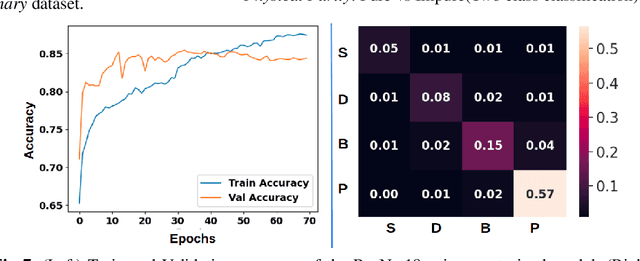


Quality assessment of agricultural produce is a crucial step in minimizing food stock wastage. However, this is currently done manually and often requires expert supervision, especially in smaller seeds like corn. We propose a novel computer vision-based system for automating this process. We build a novel seed image acquisition setup, which captures both the top and bottom views. Dataset collection for this problem has challenges of data annotation costs/time and class imbalance. We address these challenges by i.) using a Conditional Generative Adversarial Network (CGAN) to generate real-looking images for the classes with lesser images and ii.) annotate a large dataset with minimal expert human intervention by using a Batch Active Learning (BAL) based annotation tool. We benchmark different image classification models on the dataset obtained. We are able to get accuracies of up to 91.6% for testing the physical purity of seed samples.
CInC Flow: Characterizable Invertible 3x3 Convolution
Jul 03, 2021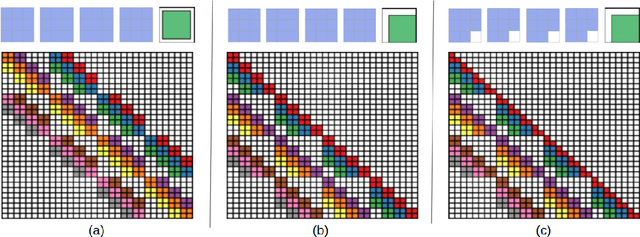

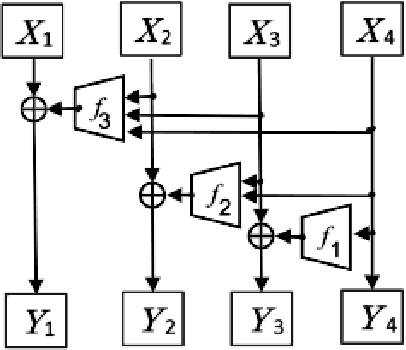
Normalizing flows are an essential alternative to GANs for generative modelling, which can be optimized directly on the maximum likelihood of the dataset. They also allow computation of the exact latent vector corresponding to an image since they are composed of invertible transformations. However, the requirement of invertibility of the transformation prevents standard and expressive neural network models such as CNNs from being directly used. Emergent convolutions were proposed to construct an invertible 3$\times$3 CNN layer using a pair of masked CNN layers, making them inefficient. We study conditions such that 3$\times$3 CNNs are invertible, allowing them to construct expressive normalizing flows. We derive necessary and sufficient conditions on a padded CNN for it to be invertible. Our conditions for invertibility are simple, can easily be maintained during the training process. Since we require only a single CNN layer for every effective invertible CNN layer, our approach is more efficient than emerging convolutions. We also proposed a coupling method, Quad-coupling. We benchmark our approach and show similar performance results to emergent convolutions while improving the model's efficiency.
Ramanujan Bipartite Graph Products for Efficient Block Sparse Neural Networks
Jul 02, 2020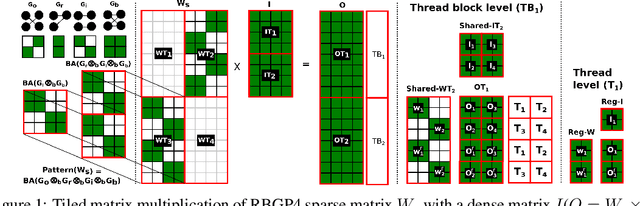
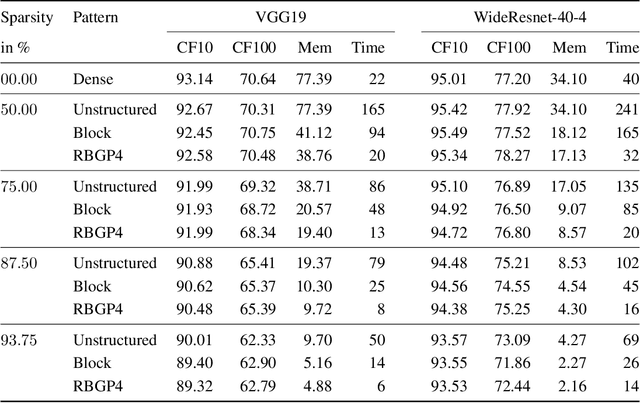
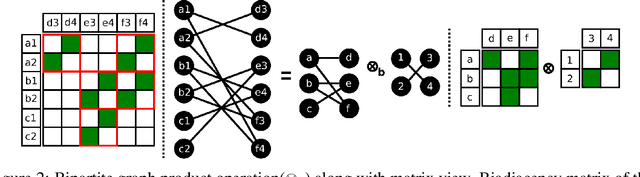
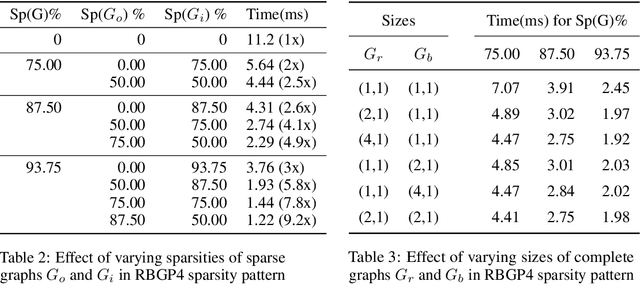
Sparse neural networks are shown to give accurate predictions competitive to denser versions, while also minimizing the number of arithmetic operations performed. However current hardware like GPU's can only exploit structured sparsity patterns for better efficiency. Hence the run time of a sparse neural network may not correspond to the arithmetic operations required. In this work, we propose RBGP( Ramanujan Bipartite Graph Product) framework for generating structured multi level block sparse neural networks by using the theory of Graph products. We also propose to use products of Ramanujan graphs which gives the best connectivity for a given level of sparsity. This essentially ensures that the i.) the networks has the structured block sparsity for which runtime efficient algorithms exists ii.) the model gives high prediction accuracy, due to the better expressive power derived from the connectivity of the graph iii.) the graph data structure has a succinct representation that can be stored efficiently in memory. We use our framework to design a specific connectivity pattern called RBGP4 which makes efficient use of the memory hierarchy available on GPU. We benchmark our approach by experimenting on image classification task over CIFAR dataset using VGG19 and WideResnet-40-4 networks and achieve 5-9x and 2-5x runtime gains over unstructured and block sparsity patterns respectively, while achieving the same level of accuracy.