 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecasting Future Videos from Novel Views via Disentangled 3D Scene Representation
Jul 31, 2024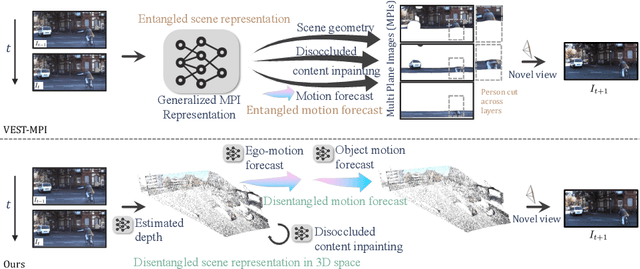



Video extrapolation in space and time (VEST) enables viewers to forecast a 3D scene into the future and view it from novel viewpoints. Recent methods propose to learn an entangled representation, aiming to model layered scene geometry, motion forecasting and novel view synthesis together, while assuming simplified affine motion and homography-based warping at each scene layer, leading to inaccurate video extrapolation. Instead of entangled scene representation and rendering, our approach chooses to disentangle scene geometry from scene motion, via lifting the 2D scene to 3D point clouds, which enables high quality rendering of future videos from novel views. To model future 3D scene motion, we propose a disentangled two-stage approach that initially forecasts ego-motion and subsequently the residual motion of dynamic objects (e.g., cars, people). This approach ensures more precise motion predictions by reducing inaccuracies from entanglement of ego-motion with dynamic object motion, where better ego-motion forecasting could significantly enhance the visual outcomes. Extensive experimental analysis on two urban scene datasets demonstrate superior performance of our proposed method in comparison to strong baselines.
Deformable VisTR: Spatio temporal deformable attention for video instance segmentation
Mar 12, 2022


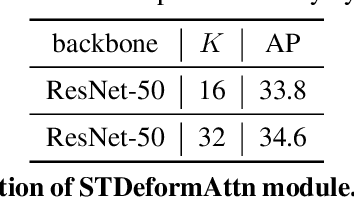
Video instance segmentation (VIS) task requires classifying, segmenting, and tracking object instances over all frames in a video clip. Recently, VisTR has been proposed as end-to-end transformer-based VIS framework, while demonstrating state-of-the-art performance. However, VisTR is slow to converge during training, requiring around 1000 GPU hours due to the high computational cost of its transformer attention module. To improve the training efficiency, we propose Deformable VisTR, leveraging spatio-temporal deformable attention module that only attends to a small fixed set of key spatio-temporal sampling points around a reference point. This enables Deformable VisTR to achieve linear computation in the size of spatio-temporal feature maps. Moreover, it can achieve on par performance as the original VisTR with 10$\times$ less GPU training hours. We validate the effectiveness of our method on the Youtube-VIS benchmark. Code is available at https://github.com/skrya/DefVIS.
Efficient Video Instance Segmentation via Tracklet Query and Proposal
Mar 03, 2022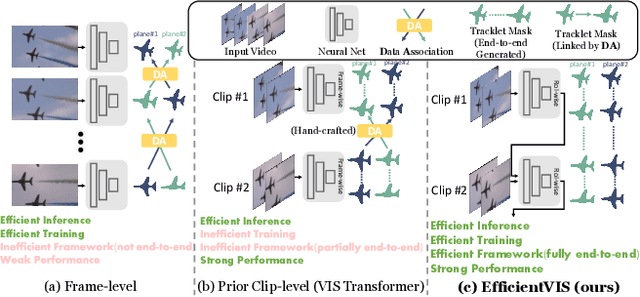
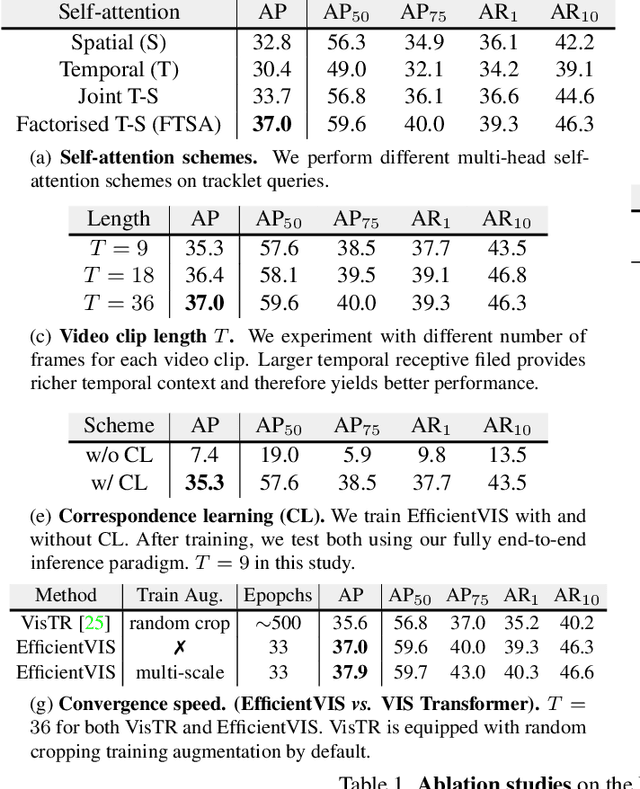
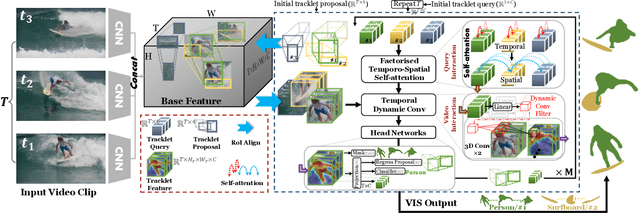
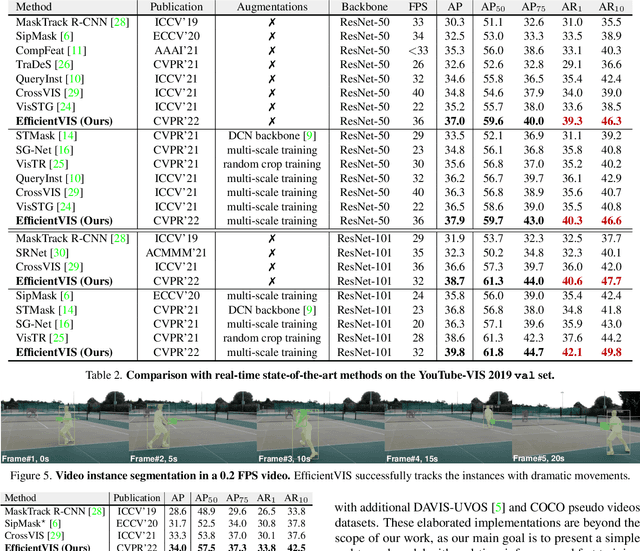
Video Instance Segmentation (VIS) aims to simultaneously classify, segment, and track multiple object instances in videos. Recent clip-level VIS takes a short video clip as input each time showing stronger performance than frame-level VIS (tracking-by-segmentation), as more temporal context from multiple frames is utilized. Yet, most clip-level methods are neither end-to-end learnable nor real-time. These limitations are addressed by the recent VIS transformer (VisTR) which performs VIS end-to-end within a clip. However, VisTR suffers from long training time due to its frame-wise dense attention. In addition, VisTR is not fully end-to-end learnable in multiple video clips as it requires a hand-crafted data association to link instance tracklets between successive clips. This paper proposes EfficientVIS, a fully end-to-end framework with efficient training and inference. At the core are tracklet query and tracklet proposal that associate and segment regions-of-interest (RoIs) across space and time by an iterative query-video interaction. We further propose a correspondence learning that makes tracklets linking between clips end-to-end learnable. Compared to VisTR, EfficientVIS requires 15x fewer training epochs while achieving state-of-the-art accuracy on the YouTube-VIS benchmark. Meanwhile, our method enables whole video instance segmentation in a single end-to-end pass without data association at all.
City-Scale Road Audit System using Deep Learning
Nov 26, 2018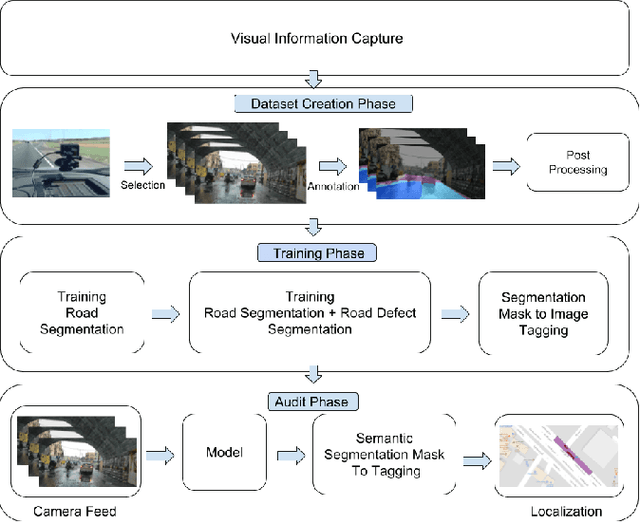
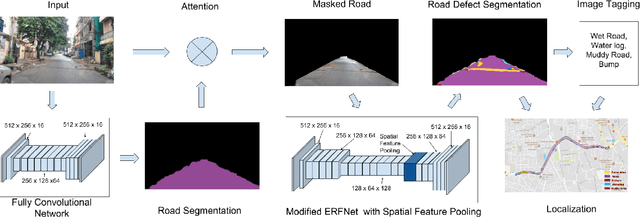

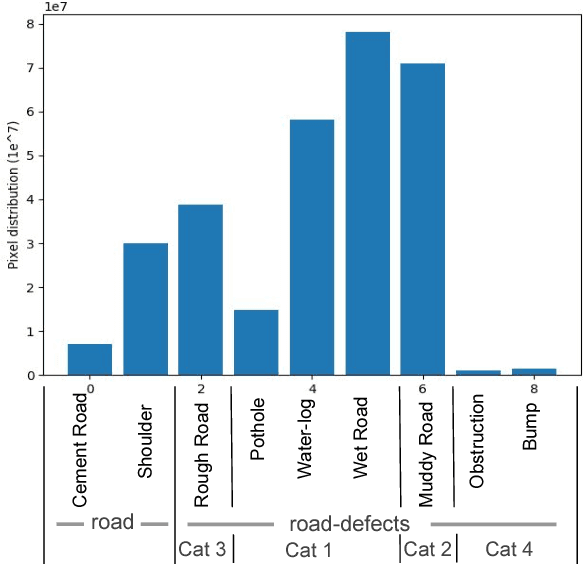
Road networks in cities are massive and is a critical component of mobility. Fast response to defects, that can occur not only due to regular wear and tear but also because of extreme events like storms, is essential. Hence there is a need for an automated system that is quick, scalable and cost-effective for gathering information about defects. We propose a system for city-scale road audit, using some of the most recent developments in deep learning and semantic segmentation. For building and benchmarking the system, we curated a dataset which has annotations required for road defects. However, many of the labels required for road audit have high ambiguity which we overcome by proposing a label hierarchy. We also propose a multi-step deep learning model that segments the road, subdivide the road further into defects, tags the frame for each defect and finally localizes the defects on a map gathered using GPS. We analyze and evaluate the models on image tagging as well as segmentation at different levels of the label hierarchy.