 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBachVid: Training-Free Video Generation with Consistent Background and Character
Oct 24, 2025Diffusion Transformers (DiTs) have recently driven significant progress in text-to-video (T2V) generation. However, generating multiple videos with consistent characters and backgrounds remains a significant challenge. Existing methods typically rely on reference images or extensive training, and often only address character consistency, leaving background consistency to image-to-video models. We introduce BachVid, the first training-free method that achieves consistent video generation without needing any reference images. Our approach is based on a systematic analysis of DiT's attention mechanism and intermediate features, revealing its ability to extract foreground masks and identify matching points during the denoising process. Our method leverages this finding by first generating an identity video and caching the intermediate variables, and then inject these cached variables into corresponding positions in newly generated videos, ensuring both foreground and background consistency across multiple videos. Experimental results demonstrate that BachVid achieves robust consistency in generated videos without requiring additional training, offering a novel and efficient solution for consistent video generation without relying on reference images or additional training.
Deep LG-Track: An Enhanced Localization-Confidence-Guided Multi-Object Tracker
Apr 02, 2025Multi-object tracking plays a crucial role in various applications, such as autonomous driving and security surveillance. This study introduces Deep LG-Track, a novel multi-object tracker that incorporates three key enhancements to improve the tracking accuracy and robustness. First, an adaptive Kalman filter is developed to dynamically update the covariance of measurement noise based on detection confidence and trajectory disappearance. Second, a novel cost matrix is formulated to adaptively fuse motion and appearance information, leveraging localization confidence and detection confidence as weighting factors. Third, a dynamic appearance feature updating strategy is introduced, adjusting the relative weighting of historical and current appearance features based on appearance clarity and localization accuracy. Comprehensive evaluations on the MOT17 and MOT20 datasets demonstrate that the proposed Deep LG-Track consistently outperforms state-of-the-art trackers across multiple performance metrics, highlighting its effectiveness in multi-object tracking tasks.
CDI3D: Cross-guided Dense-view Interpolation for 3D Reconstruction
Mar 11, 20253D object reconstruction from single-view image is a fundamental task in computer vision with wide-ranging applications. Recent advancements in Large Reconstruction Models (LRMs) have shown great promise in leveraging multi-view images generated by 2D diffusion models to extract 3D content. However, challenges remain as 2D diffusion models often struggle to produce dense images with strong multi-view consistency, and LRMs tend to amplify these inconsistencies during the 3D reconstruction process. Addressing these issues is critical for achieving high-quality and efficient 3D reconstruction. In this paper, we present CDI3D, a feed-forward framework designed for efficient, high-quality image-to-3D generation with view interpolation. To tackle the aforementioned challenges, we propose to integrate 2D diffusion-based view interpolation into the LRM pipeline to enhance the quality and consistency of the generated mesh. Specifically, our approach introduces a Dense View Interpolation (DVI) module, which synthesizes interpolated images between main views generated by the 2D diffusion model, effectively densifying the input views with better multi-view consistency. We also design a tilt camera pose trajectory to capture views with different elevations and perspectives. Subsequently, we employ a tri-plane-based mesh reconstruction strategy to extract robust tokens from these interpolated and original views, enabling the generation of high-quality 3D meshes with superior texture and geometry. Extensive experiments demonstrate that our method significantly outperforms previous state-of-the-art approaches across various benchmarks, producing 3D content with enhanced texture fidelity and geometric accuracy.
Pandora3D: A Comprehensive Framework for High-Quality 3D Shape and Texture Generation
Feb 21, 2025This report presents a comprehensive framework for generating high-quality 3D shapes and textures from diverse input prompts, including single images, multi-view images, and text descriptions. The framework consists of 3D shape generation and texture generation. (1). The 3D shape generation pipeline employs a Variational Autoencoder (VAE) to encode implicit 3D geometries into a latent space and a diffusion network to generate latents conditioned on input prompts, with modifications to enhance model capacity. An alternative Artist-Created Mesh (AM) generation approach is also explored, yielding promising results for simpler geometries. (2). Texture generation involves a multi-stage process starting with frontal images generation followed by multi-view images generation, RGB-to-PBR texture conversion, and high-resolution multi-view texture refinement. A consistency scheduler is plugged into every stage, to enforce pixel-wise consistency among multi-view textures during inference, ensuring seamless integration. The pipeline demonstrates effective handling of diverse input formats, leveraging advanced neural architectures and novel methodologies to produce high-quality 3D content. This report details the system architecture, experimental results, and potential future directions to improve and expand the framework. The source code and pretrained weights are released at: https://github.com/Tencent/Tencent-XR-3DGen.
MARS: Mesh AutoRegressive Model for 3D Shape Detailization
Feb 17, 2025

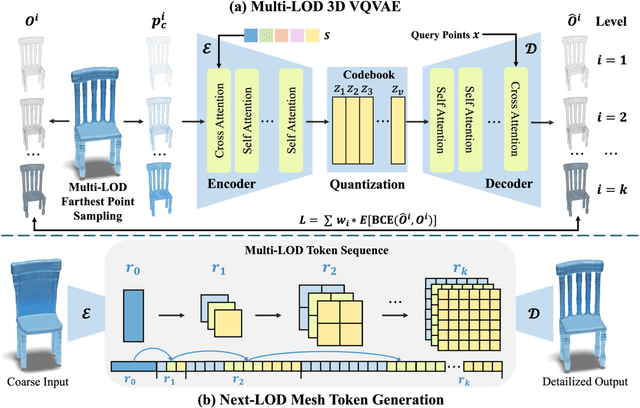

State-of-the-art methods for mesh detailization predominantly utilize Generative Adversarial Networks (GANs) to generate detailed meshes from coarse ones. These methods typically learn a specific style code for each category or similar categories without enforcing geometry supervision across different Levels of Detail (LODs). Consequently, such methods often fail to generalize across a broader range of categories and cannot ensure shape consistency throughout the detailization process. In this paper, we introduce MARS, a novel approach for 3D shape detailization. Our method capitalizes on a novel multi-LOD, multi-category mesh representation to learn shape-consistent mesh representations in latent space across different LODs. We further propose a mesh autoregressive model capable of generating such latent representations through next-LOD token prediction. This approach significantly enhances the realism of the generated shapes. Extensive experiments conducted on the challenging 3D Shape Detailization benchmark demonstrate that our proposed MARS model achieves state-of-the-art performance, surpassing existing methods in both qualitative and quantitative assessments. Notably, the model's capability to generate fine-grained details while preserving the overall shape integrity is particularly commendable.
BAG: Body-Aligned 3D Wearable Asset Generation
Jan 27, 2025



While recent advancements have shown remarkable progress in general 3D shape generation models, the challenge of leveraging these approaches to automatically generate wearable 3D assets remains unexplored. To this end, we present BAG, a Body-aligned Asset Generation method to output 3D wearable asset that can be automatically dressed on given 3D human bodies. This is achived by controlling the 3D generation process using human body shape and pose information. Specifically, we first build a general single-image to consistent multiview image diffusion model, and train it on the large Objaverse dataset to achieve diversity and generalizability. Then we train a Controlnet to guide the multiview generator to produce body-aligned multiview images. The control signal utilizes the multiview 2D projections of the target human body, where pixel values represent the XYZ coordinates of the body surface in a canonical space. The body-conditioned multiview diffusion generates body-aligned multiview images, which are then fed into a native 3D diffusion model to produce the 3D shape of the asset. Finally, by recovering the similarity transformation using multiview silhouette supervision and addressing asset-body penetration with physics simulators, the 3D asset can be accurately fitted onto the target human body. Experimental results demonstrate significant advantages over existing methods in terms of image prompt-following capability, shape diversity, and shape quality. Our project page is available at https://bag-3d.github.io/.
DoubleDiffusion: Combining Heat Diffusion with Denoising Diffusion for Generative Learning on 3D Meshes
Jan 06, 2025

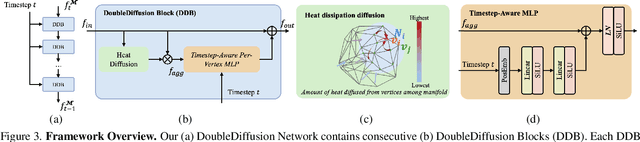

This paper proposes DoubleDiffusion, a novel framework that combines heat dissipation diffusion and denoising diffusion for direct generative learning on 3D mesh surfaces. Our approach addresses the challenges of generating continuous signal distributions residing on a curve manifold surface. Unlike previous methods that rely on unrolling 3D meshes into 2D or adopting field representations, DoubleDiffusion leverages the Laplacian-Beltrami operator to process features respecting the mesh structure. This combination enables effective geometry-aware signal diffusion across the underlying geometry. As shown in Fig.~\ref{fig:teaser}, we demonstrate that DoubleDiffusion has the ability to generate RGB signal distributions on complex 3D mesh surfaces and achieves per-category shape-conditioned texture generation across different shape geometry. Our work contributes a new direction in diffusion-based generative modeling on 3D surfaces, with potential applications in the field of 3D asset generation.
T$^3$-S2S: Training-free Triplet Tuning for Sketch to Scene Generation
Dec 18, 2024Scene generation is crucial to many computer graphics applications. Recent advances in generative AI have streamlined sketch-to-image workflows, easing the workload for artists and designers in creating scene concept art. However, these methods often struggle for complex scenes with multiple detailed objects, sometimes missing small or uncommon instances. In this paper, we propose a Training-free Triplet Tuning for Sketch-to-Scene (T3-S2S) generation after reviewing the entire cross-attention mechanism. This scheme revitalizes the existing ControlNet model, enabling effective handling of multi-instance generations, involving prompt balance, characteristics prominence, and dense tuning. Specifically, this approach enhances keyword representation via the prompt balance module, reducing the risk of missing critical instances. It also includes a characteristics prominence module that highlights TopK indices in each channel, ensuring essential features are better represented based on token sketches. Additionally, it employs dense tuning to refine contour details in the attention map, compensating for instance-related regions. Experiments validate that our triplet tuning approach substantially improves the performance of existing sketch-to-image models. It consistently generates detailed, multi-instance 2D images, closely adhering to the input prompts and enhancing visual quality in complex multi-instance scenes. Code is available at https://github.com/chaos-sun/t3s2s.git.
PhyCAGE: Physically Plausible Compositional 3D Asset Generation from a Single Image
Nov 27, 2024



We present PhyCAGE, the first approach for physically plausible compositional 3D asset generation from a single image. Given an input image, we first generate consistent multi-view images for components of the assets. These images are then fitted with 3D Gaussian Splatting representations. To ensure that the Gaussians representing objects are physically compatible with each other, we introduce a Physical Simulation-Enhanced Score Distillation Sampling (PSE-SDS) technique to further optimize the positions of the Gaussians. It is achieved by setting the gradient of the SDS loss as the initial velocity of the physical simulation, allowing the simulator to act as a physics-guided optimizer that progressively corrects the Gaussians' positions to a physically compatible state. Experimental results demonstrate that the proposed method can generate physically plausible compositional 3D assets given a single image.
OpenScholar: Synthesizing Scientific Literature with Retrieval-augmented LMs
Nov 21, 2024



Scientific progress depends on researchers' ability to synthesize the growing body of literature. Can large language models (LMs) assist scientists in this task? We introduce OpenScholar, a specialized retrieval-augmented LM that answers scientific queries by identifying relevant passages from 45 million open-access papers and synthesizing citation-backed responses. To evaluate OpenScholar, we develop ScholarQABench, the first large-scale multi-domain benchmark for literature search, comprising 2,967 expert-written queries and 208 long-form answers across computer science, physics, neuroscience, and biomedicine. On ScholarQABench, OpenScholar-8B outperforms GPT-4o by 5% and PaperQA2 by 7% in correctness, despite being a smaller, open model. While GPT4o hallucinates citations 78 to 90% of the time, OpenScholar achieves citation accuracy on par with human experts. OpenScholar's datastore, retriever, and self-feedback inference loop also improves off-the-shelf LMs: for instance, OpenScholar-GPT4o improves GPT-4o's correctness by 12%. In human evaluations, experts preferred OpenScholar-8B and OpenScholar-GPT4o responses over expert-written ones 51% and 70% of the time, respectively, compared to GPT4o's 32%. We open-source all of our code, models, datastore, data and a public demo.