 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePuppeteer: Rig and Animate Your 3D Models
Aug 14, 2025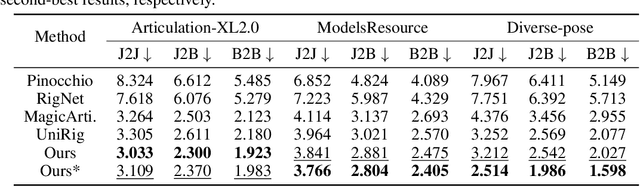


Modern interactive applications increasingly demand dynamic 3D content, yet the transformation of static 3D models into animated assets constitutes a significant bottleneck in content creation pipelines. While recent advances in generative AI have revolutionized static 3D model creation, rigging and animation continue to depend heavily on expert intervention. We present Puppeteer, a comprehensive framework that addresses both automatic rigging and animation for diverse 3D objects. Our system first predicts plausible skeletal structures via an auto-regressive transformer that introduces a joint-based tokenization strategy for compact representation and a hierarchical ordering methodology with stochastic perturbation that enhances bidirectional learning capabilities. It then infers skinning weights via an attention-based architecture incorporating topology-aware joint attention that explicitly encodes inter-joint relationships based on skeletal graph distances. Finally, we complement these rigging advances with a differentiable optimization-based animation pipeline that generates stable, high-fidelity animations while being computationally more efficient than existing approaches. Extensive evaluations across multiple benchmarks demonstrate that our method significantly outperforms state-of-the-art techniques in both skeletal prediction accuracy and skinning quality. The system robustly processes diverse 3D content, ranging from professionally designed game assets to AI-generated shapes, producing temporally coherent animations that eliminate the jittering issues common in existing methods.
Exploring Active Learning for Label-Efficient Training of Semantic Neural Radiance Field
Jul 23, 2025Neural Radiance Field (NeRF) models are implicit neural scene representation methods that offer unprecedented capabilities in novel view synthesis. Semantically-aware NeRFs not only capture the shape and radiance of a scene, but also encode semantic information of the scene. The training of semantically-aware NeRFs typically requires pixel-level class labels, which can be prohibitively expensive to collect. In this work, we explore active learning as a potential solution to alleviate the annotation burden. We investigate various design choices for active learning of semantically-aware NeRF, including selection granularity and selection strategies. We further propose a novel active learning strategy that takes into account 3D geometric constraints in sample selection. Our experiments demonstrate that active learning can effectively reduce the annotation cost of training semantically-aware NeRF, achieving more than 2X reduction in annotation cost compared to random sampling.
OccLE: Label-Efficient 3D Semantic Occupancy Prediction
May 27, 2025
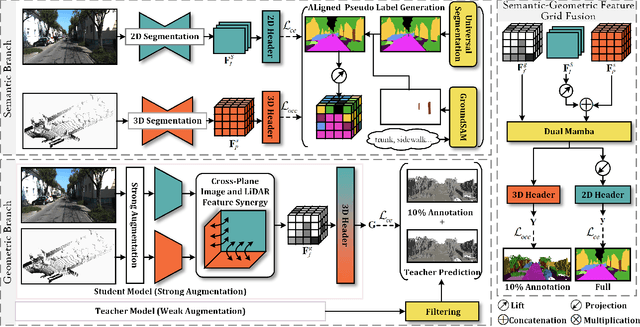
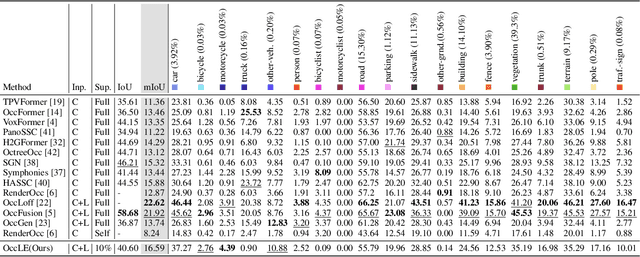
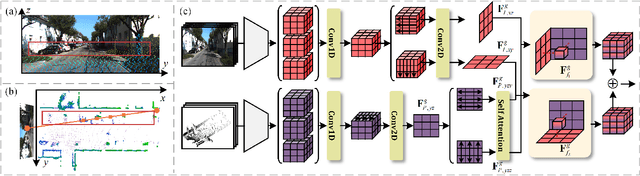
3D semantic occupancy prediction offers an intuitive and efficient scene understanding and has attracted significant interest in autonomous driving perception. Existing approaches either rely on full supervision, which demands costly voxel-level annotations, or on self-supervision, which provides limited guidance and yields suboptimal performance. To address these challenges, we propose OccLE, a Label-Efficient 3D Semantic Occupancy Prediction that takes images and LiDAR as inputs and maintains high performance with limited voxel annotations. Our intuition is to decouple the semantic and geometric learning tasks and then fuse the learned feature grids from both tasks for the final semantic occupancy prediction. Therefore, the semantic branch distills 2D foundation model to provide aligned pseudo labels for 2D and 3D semantic learning. The geometric branch integrates image and LiDAR inputs in cross-plane synergy based on their inherency, employing semi-supervision to enhance geometry learning. We fuse semantic-geometric feature grids through Dual Mamba and incorporate a scatter-accumulated projection to supervise unannotated prediction with aligned pseudo labels. Experiments show that OccLE achieves competitive performance with only 10% of voxel annotations, reaching a mIoU of 16.59% on the SemanticKITTI validation set.
CADCrafter: Generating Computer-Aided Design Models from Unconstrained Images
Apr 10, 2025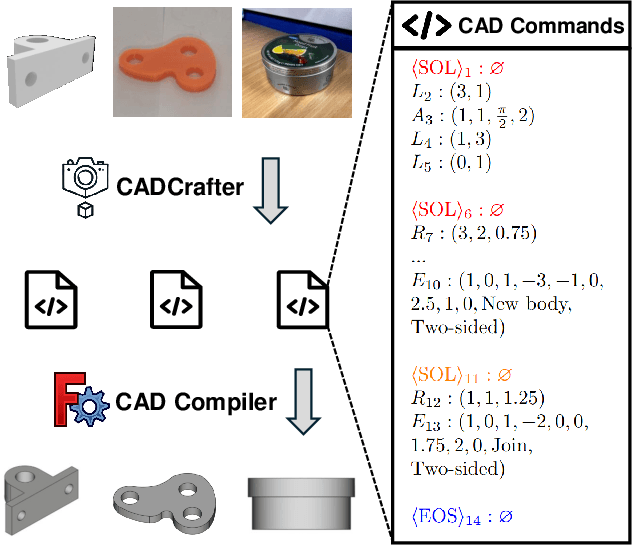
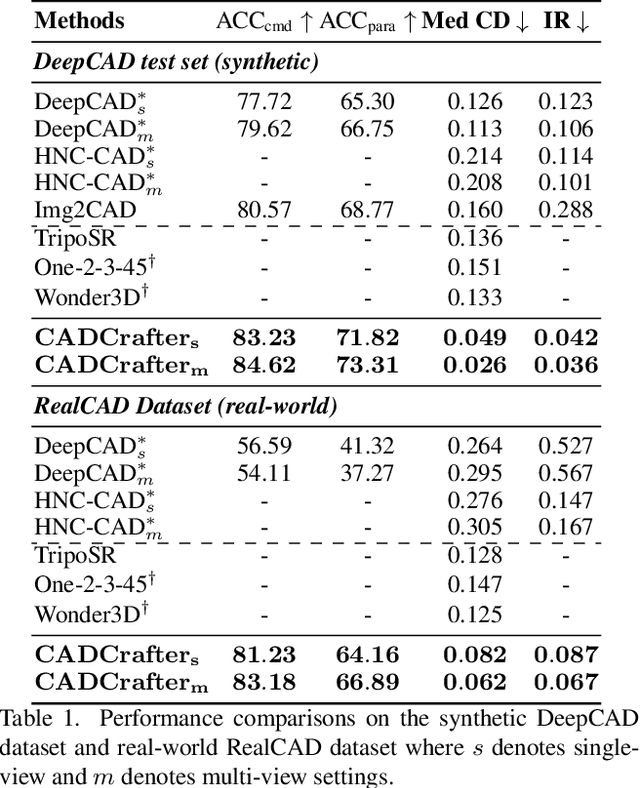
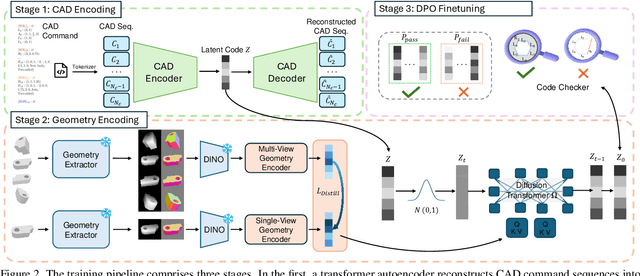
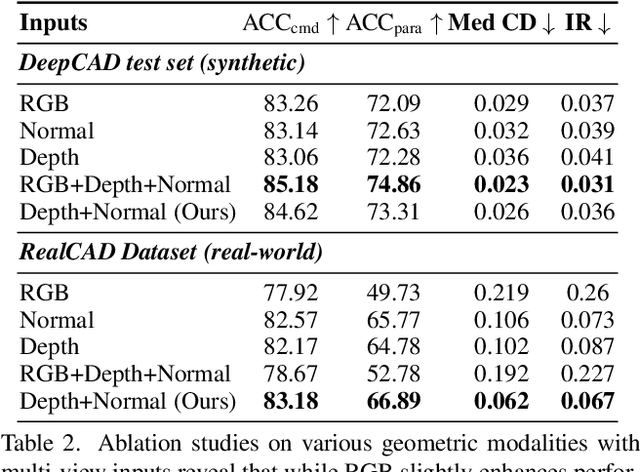
Creating CAD digital twins from the physical world is crucial for manufacturing, design, and simulation. However, current methods typically rely on costly 3D scanning with labor-intensive post-processing. To provide a user-friendly design process, we explore the problem of reverse engineering from unconstrained real-world CAD images that can be easily captured by users of all experiences. However, the scarcity of real-world CAD data poses challenges in directly training such models. To tackle these challenges, we propose CADCrafter, an image-to-parametric CAD model generation framework that trains solely on synthetic textureless CAD data while testing on real-world images. To bridge the significant representation disparity between images and parametric CAD models, we introduce a geometry encoder to accurately capture diverse geometric features. Moreover, the texture-invariant properties of the geometric features can also facilitate the generalization to real-world scenarios. Since compiling CAD parameter sequences into explicit CAD models is a non-differentiable process, the network training inherently lacks explicit geometric supervision. To impose geometric validity constraints, we employ direct preference optimization (DPO) to fine-tune our model with the automatic code checker feedback on CAD sequence quality. Furthermore, we collected a real-world dataset, comprised of multi-view images and corresponding CAD command sequence pairs, to evaluate our method. Experimental results demonstrate that our approach can robustly handle real unconstrained CAD images, and even generalize to unseen general objects.
MagicArticulate: Make Your 3D Models Articulation-Ready
Feb 18, 2025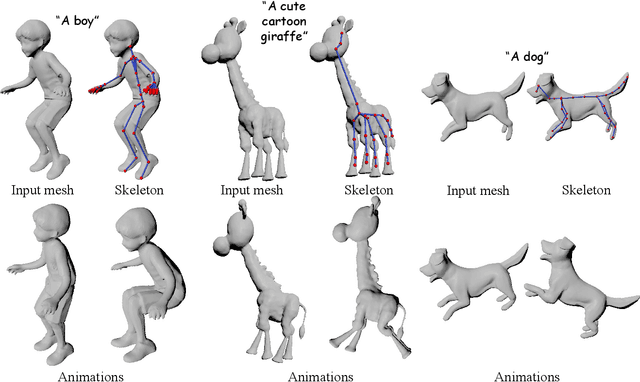
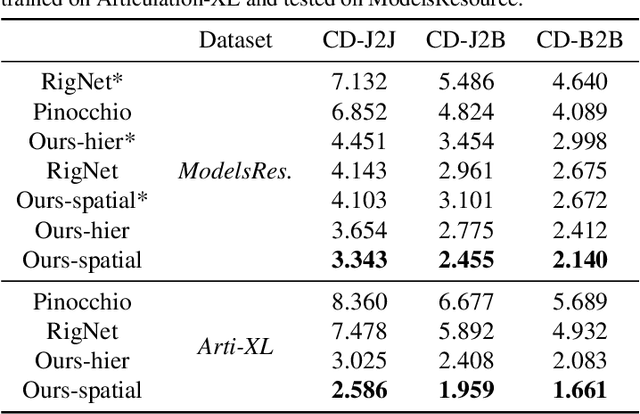
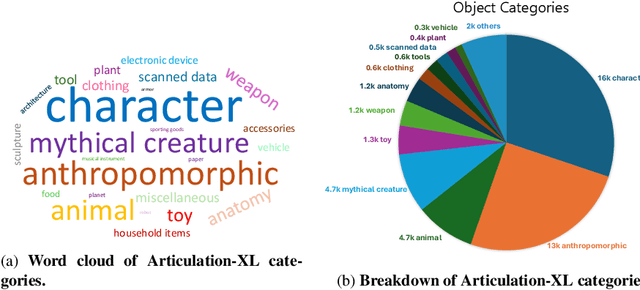
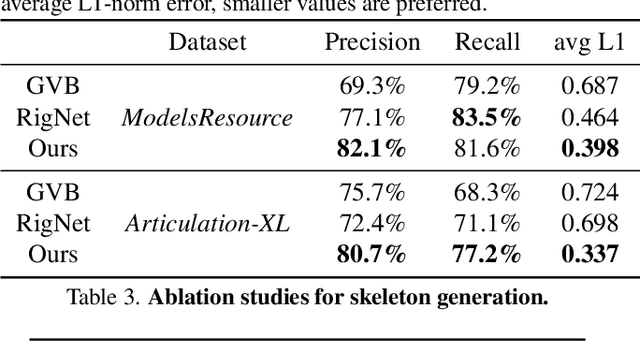
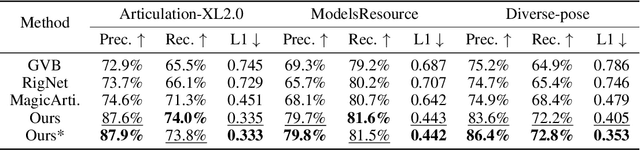
With the explosive growth of 3D content creation, there is an increasing demand for automatically converting static 3D models into articulation-ready versions that support realistic animation. Traditional approaches rely heavily on manual annotation, which is both time-consuming and labor-intensive. Moreover, the lack of large-scale benchmarks has hindered the development of learning-based solutions. In this work, we present MagicArticulate, an effective framework that automatically transforms static 3D models into articulation-ready assets. Our key contributions are threefold. First, we introduce Articulation-XL, a large-scale benchmark containing over 33k 3D models with high-quality articulation annotations, carefully curated from Objaverse-XL. Second, we propose a novel skeleton generation method that formulates the task as a sequence modeling problem, leveraging an auto-regressive transformer to naturally handle varying numbers of bones or joints within skeletons and their inherent dependencies across different 3D models. Third, we predict skinning weights using a functional diffusion process that incorporates volumetric geodesic distance priors between vertices and joints. Extensive experiments demonstrate that MagicArticulate significantly outperforms existing methods across diverse object categories, achieving high-quality articulation that enables realistic animation. Project page: https://chaoyuesong.github.io/MagicArticulate.
Prim2Room: Layout-Controllable Room Mesh Generation from Primitives
Sep 09, 2024We propose Prim2Room, a novel framework for controllable room mesh generation leveraging 2D layout conditions and 3D primitive retrieval to facilitate precise 3D layout specification. Diverging from existing methods that lack control and precision, our approach allows for detailed customization of room-scale environments. To overcome the limitations of previous methods, we introduce an adaptive viewpoint selection algorithm that allows the system to generate the furniture texture and geometry from more favorable views than predefined camera trajectories. Additionally, we employ non-rigid depth registration to ensure alignment between generated objects and their corresponding primitive while allowing for shape variations to maintain diversity. Our method not only enhances the accuracy and aesthetic appeal of generated 3D scenes but also provides a user-friendly platform for detailed room design.
Gaussian Mixture based Evidential Learning for Stereo Matching
Aug 05, 2024



In this paper, we introduce a novel Gaussian mixture based evidential learning solution for robust stereo matching. Diverging from previous evidential deep learning approaches that rely on a single Gaussian distribution, our framework posits that individual image data adheres to a mixture-of-Gaussian distribution in stereo matching. This assumption yields more precise pixel-level predictions and more accurately mirrors the real-world image distribution. By further employing the inverse-Gamma distribution as an intermediary prior for each mixture component, our probabilistic model achieves improved depth estimation compared to its counterpart with the single Gaussian and effectively captures the model uncertainty, which enables a strong cross-domain generation ability. We evaluated our method for stereo matching by training the model using the Scene Flow dataset and testing it on KITTI 2015 and Middlebury 2014. The experiment results consistently show that our method brings improvements over the baseline methods in a trustworthy manner. Notably, our approach achieved new state-of-the-art results on both the in-domain validated data and the cross-domain datasets, demonstrating its effectiveness and robustness in stereo matching tasks.
Text-to-Image Rectified Flow as Plug-and-Play Priors
Jun 05, 2024



Large-scale diffusion models have achieved remarkable performance in generative tasks. Beyond their initial training applications, these models have proven their ability to function as versatile plug-and-play priors. For instance, 2D diffusion models can serve as loss functions to optimize 3D implicit models. Rectified flow, a novel class of generative models, enforces a linear progression from the source to the target distribution and has demonstrated superior performance across various domains. Compared to diffusion-based methods, rectified flow approaches surpass in terms of generation quality and efficiency, requiring fewer inference steps. In this work, we present theoretical and experimental evidence demonstrating that rectified flow based methods offer similar functionalities to diffusion models - they can also serve as effective priors. Besides the generative capabilities of diffusion priors, motivated by the unique time-symmetry properties of rectified flow models, a variant of our method can additionally perform image inversion. Experimentally, our rectified flow-based priors outperform their diffusion counterparts - the SDS and VSD losses - in text-to-3D generation. Our method also displays competitive performance in image inversion and editing.
Sync4D: Video Guided Controllable Dynamics for Physics-Based 4D Generation
May 27, 2024



In this work, we introduce a novel approach for creating controllable dynamics in 3D-generated Gaussians using casually captured reference videos. Our method transfers the motion of objects from reference videos to a variety of generated 3D Gaussians across different categories, ensuring precise and customizable motion transfer. We achieve this by employing blend skinning-based non-parametric shape reconstruction to extract the shape and motion of reference objects. This process involves segmenting the reference objects into motion-related parts based on skinning weights and establishing shape correspondences with generated target shapes. To address shape and temporal inconsistencies prevalent in existing methods, we integrate physical simulation, driving the target shapes with matched motion. This integration is optimized through a displacement loss to ensure reliable and genuine dynamics. Our approach supports diverse reference inputs, including humans, quadrupeds, and articulated objects, and can generate dynamics of arbitrary length, providing enhanced fidelity and applicability. Unlike methods heavily reliant on diffusion video generation models, our technique offers specific and high-quality motion transfer, maintaining both shape integrity and temporal consistency.
REACTO: Reconstructing Articulated Objects from a Single Video
Apr 17, 2024



In this paper, we address the challenge of reconstructing general articulated 3D objects from a single video. Existing works employing dynamic neural radiance fields have advanced the modeling of articulated objects like humans and animals from videos, but face challenges with piece-wise rigid general articulated objects due to limitations in their deformation models. To tackle this, we propose Quasi-Rigid Blend Skinning, a novel deformation model that enhances the rigidity of each part while maintaining flexible deformation of the joints. Our primary insight combines three distinct approaches: 1) an enhanced bone rigging system for improved component modeling, 2) the use of quasi-sparse skinning weights to boost part rigidity and reconstruction fidelity, and 3) the application of geodesic point assignment for precise motion and seamless deformation. Our method outperforms previous works in producing higher-fidelity 3D reconstructions of general articulated objects, as demonstrated on both real and synthetic datasets. Project page: https://chaoyuesong.github.io/REACTO.