 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCADCrafter: Generating Computer-Aided Design Models from Unconstrained Images
Apr 10, 2025Creating CAD digital twins from the physical world is crucial for manufacturing, design, and simulation. However, current methods typically rely on costly 3D scanning with labor-intensive post-processing. To provide a user-friendly design process, we explore the problem of reverse engineering from unconstrained real-world CAD images that can be easily captured by users of all experiences. However, the scarcity of real-world CAD data poses challenges in directly training such models. To tackle these challenges, we propose CADCrafter, an image-to-parametric CAD model generation framework that trains solely on synthetic textureless CAD data while testing on real-world images. To bridge the significant representation disparity between images and parametric CAD models, we introduce a geometry encoder to accurately capture diverse geometric features. Moreover, the texture-invariant properties of the geometric features can also facilitate the generalization to real-world scenarios. Since compiling CAD parameter sequences into explicit CAD models is a non-differentiable process, the network training inherently lacks explicit geometric supervision. To impose geometric validity constraints, we employ direct preference optimization (DPO) to fine-tune our model with the automatic code checker feedback on CAD sequence quality. Furthermore, we collected a real-world dataset, comprised of multi-view images and corresponding CAD command sequence pairs, to evaluate our method. Experimental results demonstrate that our approach can robustly handle real unconstrained CAD images, and even generalize to unseen general objects.
FLARE: Feed-forward Geometry, Appearance and Camera Estimation from Uncalibrated Sparse Views
Feb 19, 2025We present FLARE, a feed-forward model designed to infer high-quality camera poses and 3D geometry from uncalibrated sparse-view images (i.e., as few as 2-8 inputs), which is a challenging yet practical setting in real-world applications. Our solution features a cascaded learning paradigm with camera pose serving as the critical bridge, recognizing its essential role in mapping 3D structures onto 2D image planes. Concretely, FLARE starts with camera pose estimation, whose results condition the subsequent learning of geometric structure and appearance, optimized through the objectives of geometry reconstruction and novel-view synthesis. Utilizing large-scale public datasets for training, our method delivers state-of-the-art performance in the tasks of pose estimation, geometry reconstruction, and novel view synthesis, while maintaining the inference efficiency (i.e., less than 0.5 seconds). The project page and code can be found at: https://zhanghe3z.github.io/FLARE/
RelightVid: Temporal-Consistent Diffusion Model for Video Relighting
Jan 27, 2025Diffusion models have demonstrated remarkable success in image generation and editing, with recent advancements enabling albedo-preserving image relighting. However, applying these models to video relighting remains challenging due to the lack of paired video relighting datasets and the high demands for output fidelity and temporal consistency, further complicated by the inherent randomness of diffusion models. To address these challenges, we introduce RelightVid, a flexible framework for video relighting that can accept background video, text prompts, or environment maps as relighting conditions. Trained on in-the-wild videos with carefully designed illumination augmentations and rendered videos under extreme dynamic lighting, RelightVid achieves arbitrary video relighting with high temporal consistency without intrinsic decomposition while preserving the illumination priors of its image backbone.
UrbanCAD: Towards Highly Controllable and Photorealistic 3D Vehicles for Urban Scene Simulation
Nov 28, 2024Photorealistic 3D vehicle models with high controllability are essential for autonomous driving simulation and data augmentation. While handcrafted CAD models provide flexible controllability, free CAD libraries often lack the high-quality materials necessary for photorealistic rendering. Conversely, reconstructed 3D models offer high-fidelity rendering but lack controllability. In this work, we introduce UrbanCAD, a framework that pushes the frontier of the photorealism-controllability trade-off by generating highly controllable and photorealistic 3D vehicle digital twins from a single urban image and a collection of free 3D CAD models and handcrafted materials. These digital twins enable realistic 360-degree rendering, vehicle insertion, material transfer, relighting, and component manipulation such as opening doors and rolling down windows, supporting the construction of long-tail scenarios. To achieve this, we propose a novel pipeline that operates in a retrieval-optimization manner, adapting to observational data while preserving flexible controllability and fine-grained handcrafted details. Furthermore, given multi-view background perspective and fisheye images, we approximate environment lighting using fisheye images and reconstruct the background with 3DGS, enabling the photorealistic insertion of optimized CAD models into rendered novel view backgrounds. Experimental results demonstrate that UrbanCAD outperforms baselines based on reconstruction and retrieval in terms of photorealism. Additionally, we show that various perception models maintain their accuracy when evaluated on UrbanCAD with in-distribution configurations but degrade when applied to realistic out-of-distribution data generated by our method. This suggests that UrbanCAD is a significant advancement in creating photorealistic, safety-critical driving scenarios for downstream applications.
MaPa: Text-driven Photorealistic Material Painting for 3D Shapes
Apr 26, 2024

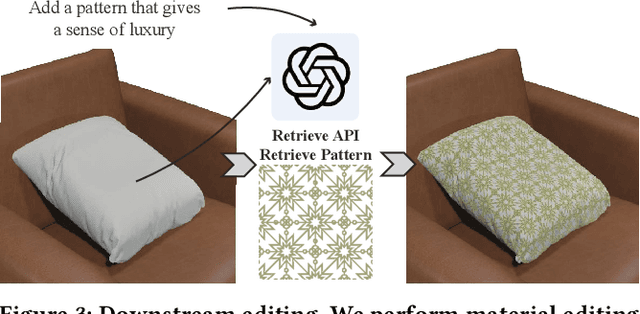

This paper aims to generate materials for 3D meshes from text descriptions. Unlike existing methods that synthesize texture maps, we propose to generate segment-wise procedural material graphs as the appearance representation, which supports high-quality rendering and provides substantial flexibility in editing. Instead of relying on extensive paired data, i.e., 3D meshes with material graphs and corresponding text descriptions, to train a material graph generative model, we propose to leverage the pre-trained 2D diffusion model as a bridge to connect the text and material graphs. Specifically, our approach decomposes a shape into a set of segments and designs a segment-controlled diffusion model to synthesize 2D images that are aligned with mesh parts. Based on generated images, we initialize parameters of material graphs and fine-tune them through the differentiable rendering module to produce materials in accordance with the textual description. Extensive experiments demonstrate the superior performance of our framework in photorealism, resolution, and editability over existing methods. Project page: https://zhanghe3z.github.io/MaPa/
Learning 3D-Aware GANs from Unposed Images with Template Feature Field
Apr 08, 2024Collecting accurate camera poses of training images has been shown to well serve the learning of 3D-aware generative adversarial networks (GANs) yet can be quite expensive in practice. This work targets learning 3D-aware GANs from unposed images, for which we propose to perform on-the-fly pose estimation of training images with a learned template feature field (TeFF). Concretely, in addition to a generative radiance field as in previous approaches, we ask the generator to also learn a field from 2D semantic features while sharing the density from the radiance field. Such a framework allows us to acquire a canonical 3D feature template leveraging the dataset mean discovered by the generative model, and further efficiently estimate the pose parameters on real data. Experimental results on various challenging datasets demonstrate the superiority of our approach over state-of-the-art alternatives from both the qualitative and the quantitative perspectives.
SpatialTracker: Tracking Any 2D Pixels in 3D Space
Apr 05, 2024



Recovering dense and long-range pixel motion in videos is a challenging problem. Part of the difficulty arises from the 3D-to-2D projection process, leading to occlusions and discontinuities in the 2D motion domain. While 2D motion can be intricate, we posit that the underlying 3D motion can often be simple and low-dimensional. In this work, we propose to estimate point trajectories in 3D space to mitigate the issues caused by image projection. Our method, named SpatialTracker, lifts 2D pixels to 3D using monocular depth estimators, represents the 3D content of each frame efficiently using a triplane representation, and performs iterative updates using a transformer to estimate 3D trajectories. Tracking in 3D allows us to leverage as-rigid-as-possible (ARAP) constraints while simultaneously learning a rigidity embedding that clusters pixels into different rigid parts. Extensive evaluation shows that our approach achieves state-of-the-art tracking performance both qualitatively and quantitatively, particularly in challenging scenarios such as out-of-plane rotation.
PanopticNeRF-360: Panoramic 3D-to-2D Label Transfer in Urban Scenes
Sep 19, 2023Training perception systems for self-driving cars requires substantial annotations. However, manual labeling in 2D images is highly labor-intensive. While existing datasets provide rich annotations for pre-recorded sequences, they fall short in labeling rarely encountered viewpoints, potentially hampering the generalization ability for perception models. In this paper, we present PanopticNeRF-360, a novel approach that combines coarse 3D annotations with noisy 2D semantic cues to generate consistent panoptic labels and high-quality images from any viewpoint. Our key insight lies in exploiting the complementarity of 3D and 2D priors to mutually enhance geometry and semantics. Specifically, we propose to leverage noisy semantic and instance labels in both 3D and 2D spaces to guide geometry optimization. Simultaneously, the improved geometry assists in filtering noise present in the 3D and 2D annotations by merging them in 3D space via a learned semantic field. To further enhance appearance, we combine MLP and hash grids to yield hybrid scene features, striking a balance between high-frequency appearance and predominantly contiguous semantics. Our experiments demonstrate PanopticNeRF-360's state-of-the-art performance over existing label transfer methods on the challenging urban scenes of the KITTI-360 dataset. Moreover, PanopticNeRF-360 enables omnidirectional rendering of high-fidelity, multi-view and spatiotemporally consistent appearance, semantic and instance labels. We make our code and data available at https://github.com/fuxiao0719/PanopticNeRF
Dyn-E: Local Appearance Editing of Dynamic Neural Radiance Fields
Jul 24, 2023Recently, the editing of neural radiance fields (NeRFs) has gained considerable attention, but most prior works focus on static scenes while research on the appearance editing of dynamic scenes is relatively lacking. In this paper, we propose a novel framework to edit the local appearance of dynamic NeRFs by manipulating pixels in a single frame of training video. Specifically, to locally edit the appearance of dynamic NeRFs while preserving unedited regions, we introduce a local surface representation of the edited region, which can be inserted into and rendered along with the original NeRF and warped to arbitrary other frames through a learned invertible motion representation network. By employing our method, users without professional expertise can easily add desired content to the appearance of a dynamic scene. We extensively evaluate our approach on various scenes and show that our approach achieves spatially and temporally consistent editing results. Notably, our approach is versatile and applicable to different variants of dynamic NeRF representations.
Painting 3D Nature in 2D: View Synthesis of Natural Scenes from a Single Semantic Mask
Feb 14, 2023We introduce a novel approach that takes a single semantic mask as input to synthesize multi-view consistent color images of natural scenes, trained with a collection of single images from the Internet. Prior works on 3D-aware image synthesis either require multi-view supervision or learning category-level prior for specific classes of objects, which can hardly work for natural scenes. Our key idea to solve this challenging problem is to use a semantic field as the intermediate representation, which is easier to reconstruct from an input semantic mask and then translate to a radiance field with the assistance of off-the-shelf semantic image synthesis models. Experiments show that our method outperforms baseline methods and produces photorealistic, multi-view consistent videos of a variety of natural scenes.