 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfiniDepth: Arbitrary-Resolution and Fine-Grained Depth Estimation with Neural Implicit Fields
Jan 06, 2026Existing depth estimation methods are fundamentally limited to predicting depth on discrete image grids. Such representations restrict their scalability to arbitrary output resolutions and hinder the geometric detail recovery. This paper introduces InfiniDepth, which represents depth as neural implicit fields. Through a simple yet effective local implicit decoder, we can query depth at continuous 2D coordinates, enabling arbitrary-resolution and fine-grained depth estimation. To better assess our method's capabilities, we curate a high-quality 4K synthetic benchmark from five different games, spanning diverse scenes with rich geometric and appearance details. Extensive experiments demonstrate that InfiniDepth achieves state-of-the-art performance on both synthetic and real-world benchmarks across relative and metric depth estimation tasks, particularly excelling in fine-detail regions. It also benefits the task of novel view synthesis under large viewpoint shifts, producing high-quality results with fewer holes and artifacts.
Split4D: Decomposed 4D Scene Reconstruction Without Video Segmentation
Dec 28, 2025This paper addresses the problem of decomposed 4D scene reconstruction from multi-view videos. Recent methods achieve this by lifting video segmentation results to a 4D representation through differentiable rendering techniques. Therefore, they heavily rely on the quality of video segmentation maps, which are often unstable, leading to unreliable reconstruction results. To overcome this challenge, our key idea is to represent the decomposed 4D scene with the Freetime FeatureGS and design a streaming feature learning strategy to accurately recover it from per-image segmentation maps, eliminating the need for video segmentation. Freetime FeatureGS models the dynamic scene as a set of Gaussian primitives with learnable features and linear motion ability, allowing them to move to neighboring regions over time. We apply a contrastive loss to Freetime FeatureGS, forcing primitive features to be close or far apart based on whether their projections belong to the same instance in the 2D segmentation map. As our Gaussian primitives can move across time, it naturally extends the feature learning to the temporal dimension, achieving 4D segmentation. Furthermore, we sample observations for training in a temporally ordered manner, enabling the streaming propagation of features over time and effectively avoiding local minima during the optimization process. Experimental results on several datasets show that the reconstruction quality of our method outperforms recent methods by a large margin.
Depth Anything 3: Recovering the Visual Space from Any Views
Nov 13, 2025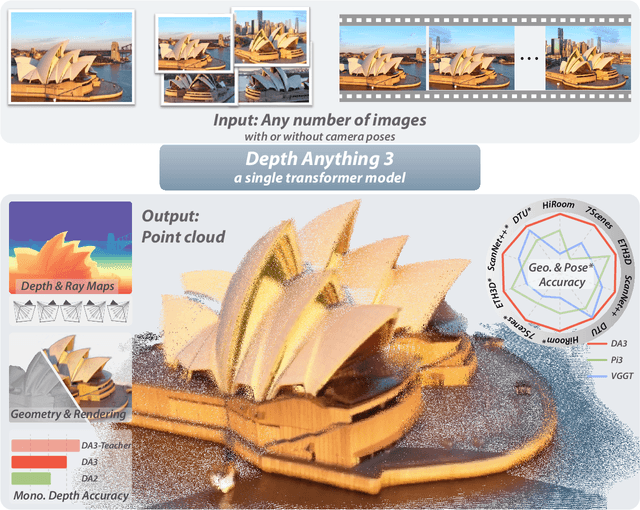
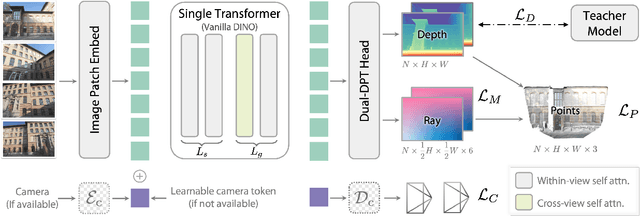
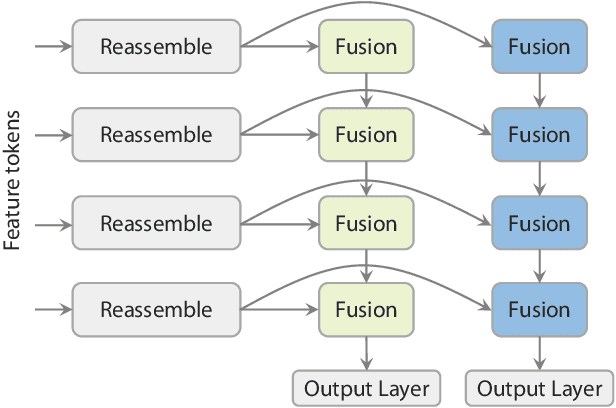
We present Depth Anything 3 (DA3), a model that predicts spatially consistent geometry from an arbitrary number of visual inputs, with or without known camera poses. In pursuit of minimal modeling, DA3 yields two key insights: a single plain transformer (e.g., vanilla DINO encoder) is sufficient as a backbone without architectural specialization, and a singular depth-ray prediction target obviates the need for complex multi-task learning. Through our teacher-student training paradigm, the model achieves a level of detail and generalization on par with Depth Anything 2 (DA2). We establish a new visual geometry benchmark covering camera pose estimation, any-view geometry and visual rendering. On this benchmark, DA3 sets a new state-of-the-art across all tasks, surpassing prior SOTA VGGT by an average of 44.3% in camera pose accuracy and 25.1% in geometric accuracy. Moreover, it outperforms DA2 in monocular depth estimation. All models are trained exclusively on public academic datasets.
Pixel-Perfect Depth with Semantics-Prompted Diffusion Transformers
Oct 08, 2025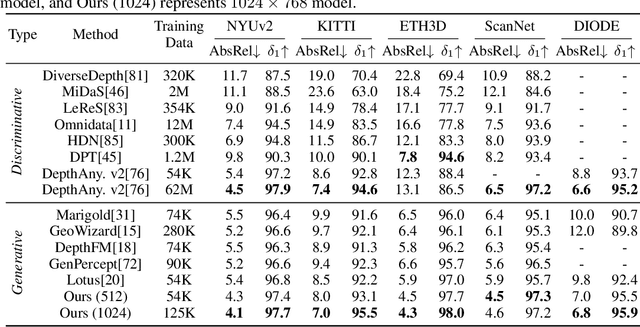

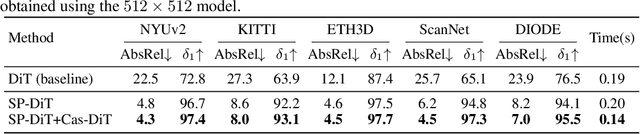
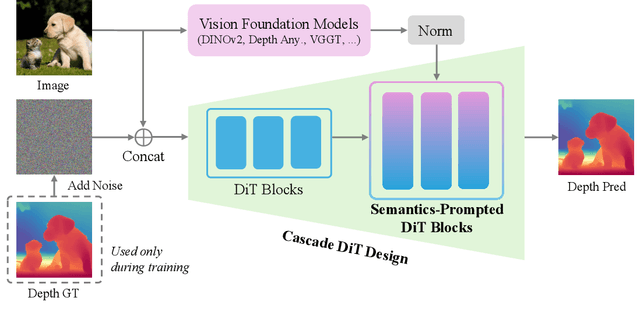
This paper presents Pixel-Perfect Depth, a monocular depth estimation model based on pixel-space diffusion generation that produces high-quality, flying-pixel-free point clouds from estimated depth maps. Current generative depth estimation models fine-tune Stable Diffusion and achieve impressive performance. However, they require a VAE to compress depth maps into latent space, which inevitably introduces \textit{flying pixels} at edges and details. Our model addresses this challenge by directly performing diffusion generation in the pixel space, avoiding VAE-induced artifacts. To overcome the high complexity associated with pixel-space generation, we introduce two novel designs: 1) Semantics-Prompted Diffusion Transformers (SP-DiT), which incorporate semantic representations from vision foundation models into DiT to prompt the diffusion process, thereby preserving global semantic consistency while enhancing fine-grained visual details; and 2) Cascade DiT Design that progressively increases the number of tokens to further enhance efficiency and accuracy. Our model achieves the best performance among all published generative models across five benchmarks, and significantly outperforms all other models in edge-aware point cloud evaluation.
Towards Depth Foundation Model: Recent Trends in Vision-Based Depth Estimation
Jul 15, 2025Depth estimation is a fundamental task in 3D computer vision, crucial for applications such as 3D reconstruction, free-viewpoint rendering, robotics, autonomous driving, and AR/VR technologies. Traditional methods relying on hardware sensors like LiDAR are often limited by high costs, low resolution, and environmental sensitivity, limiting their applicability in real-world scenarios. Recent advances in vision-based methods offer a promising alternative, yet they face challenges in generalization and stability due to either the low-capacity model architectures or the reliance on domain-specific and small-scale datasets. The emergence of scaling laws and foundation models in other domains has inspired the development of "depth foundation models": deep neural networks trained on large datasets with strong zero-shot generalization capabilities. This paper surveys the evolution of deep learning architectures and paradigms for depth estimation across the monocular, stereo, multi-view, and monocular video settings. We explore the potential of these models to address existing challenges and provide a comprehensive overview of large-scale datasets that can facilitate their development. By identifying key architectures and training strategies, we aim to highlight the path towards robust depth foundation models, offering insights into their future research and applications.
ADGaussian: Generalizable Gaussian Splatting for Autonomous Driving with Multi-modal Inputs
Apr 01, 2025We present a novel approach, termed ADGaussian, for generalizable street scene reconstruction. The proposed method enables high-quality rendering from single-view input. Unlike prior Gaussian Splatting methods that primarily focus on geometry refinement, we emphasize the importance of joint optimization of image and depth features for accurate Gaussian prediction. To this end, we first incorporate sparse LiDAR depth as an additional input modality, formulating the Gaussian prediction process as a joint learning framework of visual information and geometric clue. Furthermore, we propose a multi-modal feature matching strategy coupled with a multi-scale Gaussian decoding model to enhance the joint refinement of multi-modal features, thereby enabling efficient multi-modal Gaussian learning. Extensive experiments on two large-scale autonomous driving datasets, Waymo and KITTI, demonstrate that our ADGaussian achieves state-of-the-art performance and exhibits superior zero-shot generalization capabilities in novel-view shifting.
Multi-view Reconstruction via SfM-guided Monocular Depth Estimation
Mar 18, 2025In this paper, we present a new method for multi-view geometric reconstruction. In recent years, large vision models have rapidly developed, performing excellently across various tasks and demonstrating remarkable generalization capabilities. Some works use large vision models for monocular depth estimation, which have been applied to facilitate multi-view reconstruction tasks in an indirect manner. Due to the ambiguity of the monocular depth estimation task, the estimated depth values are usually not accurate enough, limiting their utility in aiding multi-view reconstruction. We propose to incorporate SfM information, a strong multi-view prior, into the depth estimation process, thus enhancing the quality of depth prediction and enabling their direct application in multi-view geometric reconstruction. Experimental results on public real-world datasets show that our method significantly improves the quality of depth estimation compared to previous monocular depth estimation works. Additionally, we evaluate the reconstruction quality of our approach in various types of scenes including indoor, streetscape, and aerial views, surpassing state-of-the-art MVS methods. The code and supplementary materials are available at https://zju3dv.github.io/murre/ .
BAT: Learning Event-based Optical Flow with Bidirectional Adaptive Temporal Correlation
Mar 05, 2025Event cameras deliver visual information characterized by a high dynamic range and high temporal resolution, offering significant advantages in estimating optical flow for complex lighting conditions and fast-moving objects. Current advanced optical flow methods for event cameras largely adopt established image-based frameworks. However, the spatial sparsity of event data limits their performance. In this paper, we present BAT, an innovative framework that estimates event-based optical flow using bidirectional adaptive temporal correlation. BAT includes three novel designs: 1) a bidirectional temporal correlation that transforms bidirectional temporally dense motion cues into spatially dense ones, enabling accurate and spatially dense optical flow estimation; 2) an adaptive temporal sampling strategy for maintaining temporal consistency in correlation; 3) spatially adaptive temporal motion aggregation to efficiently and adaptively aggregate consistent target motion features into adjacent motion features while suppressing inconsistent ones. Our results rank $1^{st}$ on the DSEC-Flow benchmark, outperforming existing state-of-the-art methods by a large margin while also exhibiting sharp edges and high-quality details. Notably, our BAT can accurately predict future optical flow using only past events, significantly outperforming E-RAFT's warm-start approach. Code: \textcolor{magenta}{https://github.com/gangweiX/BAT}.
Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation
Dec 18, 2024Prompts play a critical role in unleashing the power of language and vision foundation models for specific tasks. For the first time, we introduce prompting into depth foundation models, creating a new paradigm for metric depth estimation termed Prompt Depth Anything. Specifically, we use a low-cost LiDAR as the prompt to guide the Depth Anything model for accurate metric depth output, achieving up to 4K resolution. Our approach centers on a concise prompt fusion design that integrates the LiDAR at multiple scales within the depth decoder. To address training challenges posed by limited datasets containing both LiDAR depth and precise GT depth, we propose a scalable data pipeline that includes synthetic data LiDAR simulation and real data pseudo GT depth generation. Our approach sets new state-of-the-arts on the ARKitScenes and ScanNet++ datasets and benefits downstream applications, including 3D reconstruction and generalized robotic grasping.
StreetCrafter: Street View Synthesis with Controllable Video Diffusion Models
Dec 17, 2024



This paper aims to tackle the problem of photorealistic view synthesis from vehicle sensor data. Recent advancements in neural scene representation have achieved notable success in rendering high-quality autonomous driving scenes, but the performance significantly degrades as the viewpoint deviates from the training trajectory. To mitigate this problem, we introduce StreetCrafter, a novel controllable video diffusion model that utilizes LiDAR point cloud renderings as pixel-level conditions, which fully exploits the generative prior for novel view synthesis, while preserving precise camera control. Moreover, the utilization of pixel-level LiDAR conditions allows us to make accurate pixel-level edits to target scenes. In addition, the generative prior of StreetCrafter can be effectively incorporated into dynamic scene representations to achieve real-time rendering. Experiments on Waymo Open Dataset and PandaSet demonstrate that our model enables flexible control over viewpoint changes, enlarging the view synthesis regions for satisfying rendering, which outperforms existing methods.