 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASR: Self-Reflective Reasoning through Multimodal Hierarchical Attention Focusing for Agent-based Video Understanding
Apr 28, 2025



Even in the era of rapid advances in large models, video understanding remains a highly challenging task. Compared to texts or images, videos commonly contain more information with redundancy, requiring large models to properly allocate attention at a global level for comprehensive and accurate understanding. To address this, we propose a Multimodal hierarchical Attention focusing Self-reflective Reasoning (MASR) framework for agent-based video understanding. The key innovation lies in its ability to detect and prioritize segments of videos that are highly relevant to the query. Firstly, MASR realizes Multimodal Coarse-to-fine Relevance Sensing (MCRS) which enhances the correlation between the acquired contextual information and the query. Secondly, MASR employs Dilated Temporal Expansion (DTE) to mitigate the risk of missing crucial details when extracting semantic information from the focused frames selected through MCRS. By iteratively applying MCRS and DTE in the self-reflective reasoning process, MASR is able to adaptively adjust the attention to extract highly query-relevant context and therefore improve the response accuracy. In the EgoSchema dataset, MASR achieves a remarkable 5% performance gain over previous leading approaches. In the Next-QA and IntentQA datasets, it outperforms the state-of-the-art standards by 0.2% and 0.3% respectively. In the Video-MME dataset that contains long-term videos, MASR also performs better than other agent-based methods.
MCAF: Efficient Agent-based Video Understanding Framework through Multimodal Coarse-to-Fine Attention Focusing
Apr 24, 2025Even in the era of rapid advances in large models, video understanding, particularly long videos, remains highly challenging. Compared with textual or image-based information, videos commonly contain more information with redundancy, requiring large models to strategically allocate attention at a global level for accurate comprehension. To address this, we propose MCAF, an agent-based, training-free framework perform video understanding through Multimodal Coarse-to-fine Attention Focusing. The key innovation lies in its ability to sense and prioritize segments of the video that are highly relevant to the understanding task. First, MCAF hierarchically concentrates on highly relevant frames through multimodal information, enhancing the correlation between the acquired contextual information and the query. Second, it employs a dilated temporal expansion mechanism to mitigate the risk of missing crucial details when extracting information from these concentrated frames. In addition, our framework incorporates a self-reflection mechanism utilizing the confidence level of the model's responses as feedback. By iteratively applying these two creative focusing strategies, it adaptively adjusts attention to capture highly query-connected context and thus improves response accuracy. MCAF outperforms comparable state-of-the-art methods on average. On the EgoSchema dataset, it achieves a remarkable 5% performance gain over the leading approach. Meanwhile, on Next-QA and IntentQA datasets, it outperforms the current state-of-the-art standard by 0.2% and 0.3% respectively. On the Video-MME dataset, which features videos averaging nearly an hour in length, MCAF also outperforms other agent-based methods.
BAT: Learning Event-based Optical Flow with Bidirectional Adaptive Temporal Correlation
Mar 05, 2025Event cameras deliver visual information characterized by a high dynamic range and high temporal resolution, offering significant advantages in estimating optical flow for complex lighting conditions and fast-moving objects. Current advanced optical flow methods for event cameras largely adopt established image-based frameworks. However, the spatial sparsity of event data limits their performance. In this paper, we present BAT, an innovative framework that estimates event-based optical flow using bidirectional adaptive temporal correlation. BAT includes three novel designs: 1) a bidirectional temporal correlation that transforms bidirectional temporally dense motion cues into spatially dense ones, enabling accurate and spatially dense optical flow estimation; 2) an adaptive temporal sampling strategy for maintaining temporal consistency in correlation; 3) spatially adaptive temporal motion aggregation to efficiently and adaptively aggregate consistent target motion features into adjacent motion features while suppressing inconsistent ones. Our results rank $1^{st}$ on the DSEC-Flow benchmark, outperforming existing state-of-the-art methods by a large margin while also exhibiting sharp edges and high-quality details. Notably, our BAT can accurately predict future optical flow using only past events, significantly outperforming E-RAFT's warm-start approach. Code: \textcolor{magenta}{https://github.com/gangweiX/BAT}.
MonSter: Marry Monodepth to Stereo Unleashes Power
Jan 15, 2025Stereo matching recovers depth from image correspondences. Existing methods struggle to handle ill-posed regions with limited matching cues, such as occlusions and textureless areas. To address this, we propose MonSter, a novel method that leverages the complementary strengths of monocular depth estimation and stereo matching. MonSter integrates monocular depth and stereo matching into a dual-branch architecture to iteratively improve each other. Confidence-based guidance adaptively selects reliable stereo cues for monodepth scale-shift recovery. The refined monodepth is in turn guides stereo effectively at ill-posed regions. Such iterative mutual enhancement enables MonSter to evolve monodepth priors from coarse object-level structures to pixel-level geometry, fully unlocking the potential of stereo matching. As shown in Fig.1, MonSter ranks 1st across five most commonly used leaderboards -- SceneFlow, KITTI 2012, KITTI 2015, Middlebury, and ETH3D. Achieving up to 49.5% improvements (Bad 1.0 on ETH3D) over the previous best method. Comprehensive analysis verifies the effectiveness of MonSter in ill-posed regions. In terms of zero-shot generalization, MonSter significantly and consistently outperforms state-of-the-art across the board. The code is publicly available at: https://github.com/Junda24/MonSter.
Leveraging Consistent Spatio-Temporal Correspondence for Robust Visual Odometry
Dec 22, 2024



Recent approaches to VO have significantly improved performance by using deep networks to predict optical flow between video frames. However, existing methods still suffer from noisy and inconsistent flow matching, making it difficult to handle challenging scenarios and long-sequence estimation. To overcome these challenges, we introduce Spatio-Temporal Visual Odometry (STVO), a novel deep network architecture that effectively leverages inherent spatio-temporal cues to enhance the accuracy and consistency of multi-frame flow matching. With more accurate and consistent flow matching, STVO can achieve better pose estimation through the bundle adjustment (BA). Specifically, STVO introduces two innovative components: 1) the Temporal Propagation Module that utilizes multi-frame information to extract and propagate temporal cues across adjacent frames, maintaining temporal consistency; 2) the Spatial Activation Module that utilizes geometric priors from the depth maps to enhance spatial consistency while filtering out excessive noise and incorrect matches. Our STVO achieves state-of-the-art performance on TUM-RGBD, EuRoc MAV, ETH3D and KITTI Odometry benchmarks. Notably, it improves accuracy by 77.8% on ETH3D benchmark and 38.9% on KITTI Odometry benchmark over the previous best methods.
RoMeO: Robust Metric Visual Odometry
Dec 16, 2024



Visual odometry (VO) aims to estimate camera poses from visual inputs -- a fundamental building block for many applications such as VR/AR and robotics. This work focuses on monocular RGB VO where the input is a monocular RGB video without IMU or 3D sensors. Existing approaches lack robustness under this challenging scenario and fail to generalize to unseen data (especially outdoors); they also cannot recover metric-scale poses. We propose Robust Metric Visual Odometry (RoMeO), a novel method that resolves these issues leveraging priors from pre-trained depth models. RoMeO incorporates both monocular metric depth and multi-view stereo (MVS) models to recover metric-scale, simplify correspondence search, provide better initialization and regularize optimization. Effective strategies are proposed to inject noise during training and adaptively filter noisy depth priors, which ensure the robustness of RoMeO on in-the-wild data. As shown in Fig.1, RoMeO advances the state-of-the-art (SOTA) by a large margin across 6 diverse datasets covering both indoor and outdoor scenes. Compared to the current SOTA DPVO, RoMeO reduces the relative (align the trajectory scale with GT) and absolute trajectory errors both by >50%. The performance gain also transfers to the full SLAM pipeline (with global BA & loop closure). Code will be released upon acceptance.
3D Multi-Object Tracking with Semi-Supervised GRU-Kalman Filter
Nov 13, 2024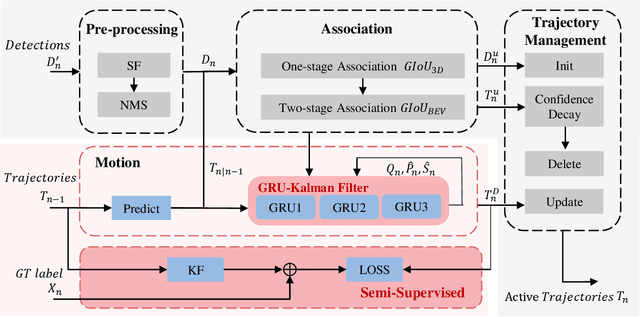
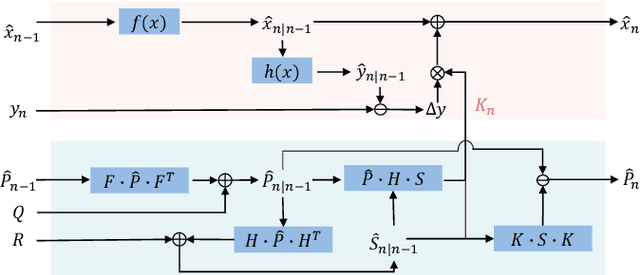
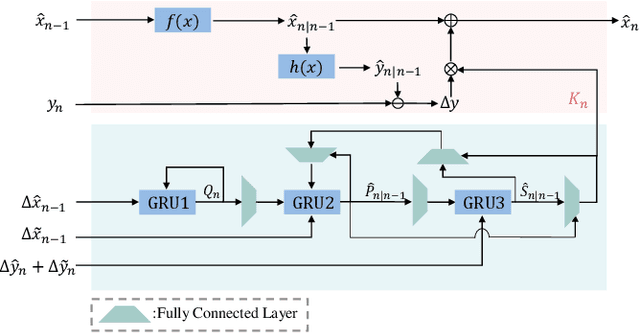
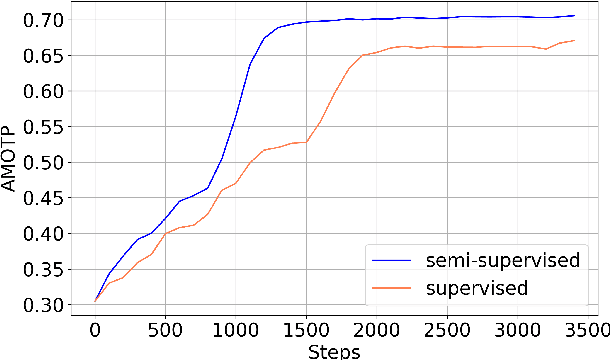
3D Multi-Object Tracking (MOT), a fundamental component of environmental perception, is essential for intelligent systems like autonomous driving and robotic sensing. Although Tracking-by-Detection frameworks have demonstrated excellent performance in recent years, their application in real-world scenarios faces significant challenges. Object movement in complex environments is often highly nonlinear, while existing methods typically rely on linear approximations of motion. Furthermore, system noise is frequently modeled as a Gaussian distribution, which fails to capture the true complexity of the noise dynamics. These oversimplified modeling assumptions can lead to significant reductions in tracking precision. To address this, we propose a GRU-based MOT method, which introduces a learnable Kalman filter into the motion module. This approach is able to learn object motion characteristics through data-driven learning, thereby avoiding the need for manual model design and model error. At the same time, to avoid abnormal supervision caused by the wrong association between annotations and trajectories, we design a semi-supervised learning strategy to accelerate the convergence speed and improve the robustness of the model. Evaluation experiment on the nuScenes and Argoverse2 datasets demonstrates that our system exhibits superior performance and significant potential compared to traditional TBD methods.
IGEV++: Iterative Multi-range Geometry Encoding Volumes for Stereo Matching
Sep 01, 2024



Stereo matching is a core component in many computer vision and robotics systems. Despite significant advances over the last decade, handling matching ambiguities in ill-posed regions and large disparities remains an open challenge. In this paper, we propose a new deep network architecture, called IGEV++, for stereo matching. The proposed IGEV++ builds Multi-range Geometry Encoding Volumes (MGEV) that encode coarse-grained geometry information for ill-posed regions and large disparities and fine-grained geometry information for details and small disparities. To construct MGEV, we introduce an adaptive patch matching module that efficiently and effectively computes matching costs for large disparity ranges and/or ill-posed regions. We further propose a selective geometry feature fusion module to adaptively fuse multi-range and multi-granularity geometry features in MGEV. We then index the fused geometry features and input them to ConvGRUs to iteratively update the disparity map. MGEV allows to efficiently handle large disparities and ill-posed regions, such as occlusions and textureless regions, and enjoys rapid convergence during iterations. Our IGEV++ achieves the best performance on the Scene Flow test set across all disparity ranges, up to 768px. Our IGEV++ also achieves state-of-the-art accuracy on the Middlebury, ETH3D, KITTI 2012, and 2015 benchmarks. Specifically, IGEV++ achieves a 3.23% 2-pixel outlier rate (Bad 2.0) on the large disparity benchmark, Middlebury, representing error reductions of 31.9% and 54.8% compared to RAFT-Stereo and GMStereo, respectively. We also present a real-time version of IGEV++ that achieves the best performance among all published real-time methods on the KITTI benchmarks. The code is publicly available at https://github.com/gangweiX/IGEV-plusplus