 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIGEV++: Iterative Multi-range Geometry Encoding Volumes for Stereo Matching
Sep 01, 2024Stereo matching is a core component in many computer vision and robotics systems. Despite significant advances over the last decade, handling matching ambiguities in ill-posed regions and large disparities remains an open challenge. In this paper, we propose a new deep network architecture, called IGEV++, for stereo matching. The proposed IGEV++ builds Multi-range Geometry Encoding Volumes (MGEV) that encode coarse-grained geometry information for ill-posed regions and large disparities and fine-grained geometry information for details and small disparities. To construct MGEV, we introduce an adaptive patch matching module that efficiently and effectively computes matching costs for large disparity ranges and/or ill-posed regions. We further propose a selective geometry feature fusion module to adaptively fuse multi-range and multi-granularity geometry features in MGEV. We then index the fused geometry features and input them to ConvGRUs to iteratively update the disparity map. MGEV allows to efficiently handle large disparities and ill-posed regions, such as occlusions and textureless regions, and enjoys rapid convergence during iterations. Our IGEV++ achieves the best performance on the Scene Flow test set across all disparity ranges, up to 768px. Our IGEV++ also achieves state-of-the-art accuracy on the Middlebury, ETH3D, KITTI 2012, and 2015 benchmarks. Specifically, IGEV++ achieves a 3.23% 2-pixel outlier rate (Bad 2.0) on the large disparity benchmark, Middlebury, representing error reductions of 31.9% and 54.8% compared to RAFT-Stereo and GMStereo, respectively. We also present a real-time version of IGEV++ that achieves the best performance among all published real-time methods on the KITTI benchmarks. The code is publicly available at https://github.com/gangweiX/IGEV-plusplus
LaSOT: A High-quality Large-scale Single Object Tracking Benchmark
Sep 12, 2020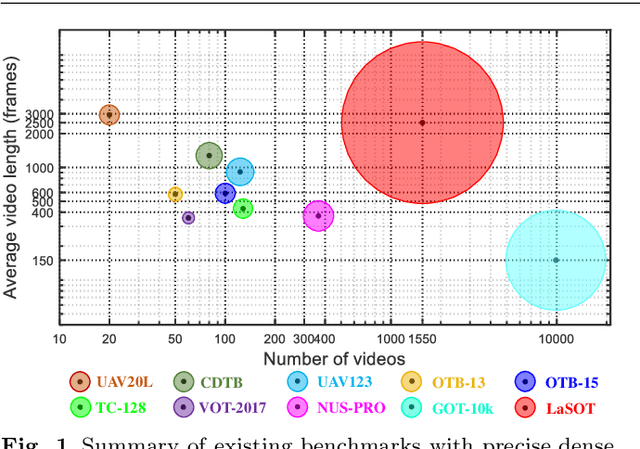
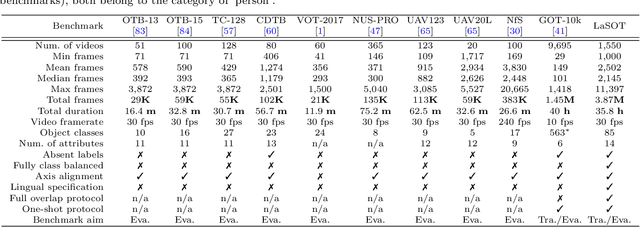
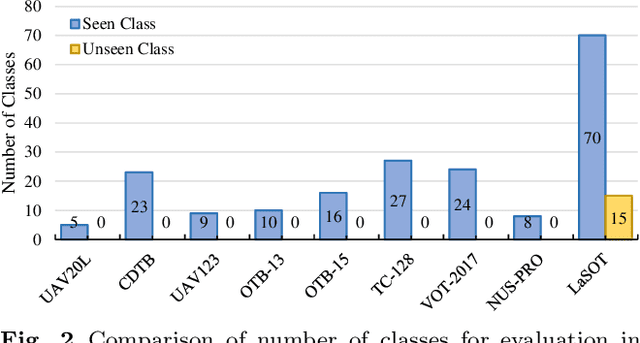

Despite great recent advances in visual tracking, its further development, including both algorithm design and evaluation, is limited due to lack of dedicated large-scale benchmarks. To address this problem, we present LaSOT, a high-quality Large-scale Single Object Tracking benchmark. LaSOT contains a diverse selection of 85 object classes, and offers 1,550 totaling more than 3.87 million frames. Each video frame is carefully and manually annotated with a bounding box. This makes LaSOT, to our knowledge, the largest densely annotated tracking benchmark. Our goal in releasing LaSOT is to provide a dedicated high quality platform for both training and evaluation of trackers. The average video length of LaSOT is around 2,500 frames, where each video contains various challenge factors that exist in real world video footage,such as the targets disappearing and re-appearing. These longer video lengths allow for the assessment of long-term trackers. To take advantage of the close connection between visual appearance and natural language, we provide language specification for each video in LaSOT. We believe such additions will allow for future research to use linguistic features to improve tracking. Two protocols, full-overlap and one-shot, are designated for flexible assessment of trackers. We extensively evaluate 48 baseline trackers on LaSOT with in-depth analysis, and results reveal that there still exists significant room for improvement. The complete benchmark, tracking results as well as analysis are available at http://vision.cs.stonybrook.edu/~lasot/.
A Single-shot-per-pose Camera-Projector Calibration System For Imperfect Planar Targets
Oct 17, 2018



Existing camera-projector calibration methods typically warp feature points from a camera image to a projector image using estimated homographies, and often suffer from errors in camera parameters and noise due to imperfect planarity of the calibration target. In this paper we propose a simple yet robust solution that explicitly deals with these challenges. Following the structured light (SL) camera-project calibration framework, a carefully designed correspondence algorithm is built on top of the De Bruijn patterns. Such correspondence is then used for initial camera-projector calibration. Then, to gain more robustness against noises, especially those from an imperfect planar calibration board, a bundle adjustment algorithm is developed to jointly optimize the estimated camera and projector models. Aside from the robustness, our solution requires only one shot of SL pattern for each calibration board pose, which is much more convenient than multi-shot solutions in practice. Data validations are conducted on both synthetic and real datasets, and our method shows clear advantages over existing methods in all experiments.
LaSOT: A High-quality Benchmark for Large-scale Single Object Tracking
Sep 20, 2018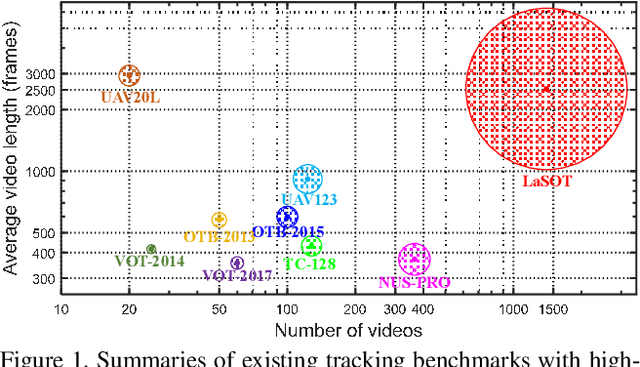
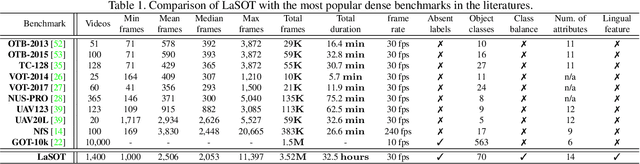


In this paper, we present LaSOT, a high-quality benchmark for Large-scale Single Object Tracking. LaSOT consists of 1,400 sequences with more than 3.5M frames in total. Each frame in these sequences is carefully and manually annotated with a bounding box, making LaSOT the largest, to the best of our knowledge, densely annotated tracking benchmark. The average sequence length of LaSOT is more than 2,500 frames, and each sequence comprises various challenges deriving from the wild where target objects may disappear and re-appear again in the view. By releasing LaSOT, we expect to provide the community a large-scale dedicated benchmark with high-quality for both the training of deep trackers and the veritable evaluation of tracking algorithms. Moreover, considering the close connections of visual appearance and natural language, we enrich LaSOT by providing additional language specification, aiming at encouraging the exploration of natural linguistic feature for tracking. A thorough experimental evaluation of 35 tracking algorithms on LaSOT is presented with detailed analysis, and the results demonstrate that there is still a big room to improvements. The benchmark and evaluation results are made publicly available at https://cis.temple.edu/lasot/.
Planar Object Tracking in the Wild: A Benchmark
May 22, 2018



Planar object tracking is an actively studied problem in vision-based robotic applications. While several benchmarks have been constructed for evaluating state-of-the-art algorithms, there is a lack of video sequences captured in the wild rather than in constrained laboratory environment. In this paper, we present a carefully designed planar object tracking benchmark containing 210 videos of 30 planar objects sampled in the natural environment. In particular, for each object, we shoot seven videos involving various challenging factors, namely scale change, rotation, perspective distortion, motion blur, occlusion, out-of-view, and unconstrained. The ground truth is carefully annotated semi-manually to ensure the quality. Moreover, eleven state-of-the-art algorithms are evaluated on the benchmark using two evaluation metrics, with detailed analysis provided for the evaluation results. We expect the proposed benchmark to benefit future studies on planar object tracking.
Adaptive Objectness for Object Tracking
Jan 05, 2015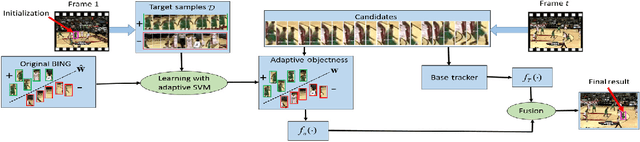

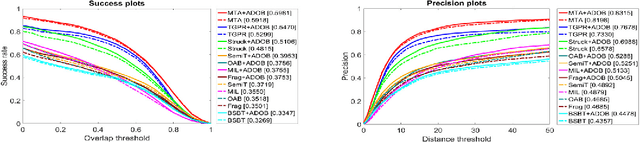

Object tracking is a long standing problem in vision. While great efforts have been spent to improve tracking performance, a simple yet reliable prior knowledge is left unexploited: the target object in tracking must be an object other than non-object. The recently proposed and popularized objectness measure provides a natural way to model such prior in visual tracking. Thus motivated, in this paper we propose to adapt objectness for visual object tracking. Instead of directly applying an existing objectness measure that is generic and handles various objects and environments, we adapt it to be compatible to the specific tracking sequence and object. More specifically, we use the newly proposed BING objectness as the base, and then train an object-adaptive objectness for each tracking task. The training is implemented by using an adaptive support vector machine that integrates information from the specific tracking target into the BING measure. We emphasize that the benefit of the proposed adaptive objectness, named ADOBING, is generic. To show this, we combine ADOBING with seven top performed trackers in recent evaluations. We run the ADOBING-enhanced trackers with their base trackers on two popular benchmarks, the CVPR2013 benchmark (50 sequences) and the Princeton Tracking Benchmark (100 sequences). On both benchmarks, our methods not only consistently improve the base trackers, but also achieve the best known performances. Noting that the way we integrate objectness in visual tracking is generic and straightforward, we expect even more improvement by using tracker-specific objectness.