 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNanoSD: Edge Efficient Foundation Model for Real Time Image Restoration
Jan 16, 2026Latent diffusion models such as Stable Diffusion 1.5 offer strong generative priors that are highly valuable for image restoration, yet their full pipelines remain too computationally heavy for deployment on edge devices. Existing lightweight variants predominantly compress the denoising U-Net or reduce the diffusion trajectory, which disrupts the underlying latent manifold and limits generalization beyond a single task. We introduce NanoSD, a family of Pareto-optimal diffusion foundation models distilled from Stable Diffusion 1.5 through network surgery, feature-wise generative distillation, and structured architectural scaling jointly applied to the U-Net and the VAE encoder-decoder. This full-pipeline co-design preserves the generative prior while producing models that occupy distinct operating points along the accuracy-latency-size frontier (e.g., 130M-315M parameters, achieving real-time inference down to 20ms on mobile-class NPUs). We show that parameter reduction alone does not correlate with hardware efficiency, and we provide an analysis revealing how architectural balance, feature routing, and latent-space preservation jointly shape true on-device latency. When used as a drop-in backbone, NanoSD enables state-of-the-art performance across image super-resolution, image deblurring, face restoration, and monocular depth estimation, outperforming prior lightweight diffusion models in both perceptual quality and practical deployability. NanoSD establishes a general-purpose diffusion foundation model family suitable for real-time visual generation and restoration on edge devices.
MoECollab: Democratizing LLM Development Through Collaborative Mixture of Experts
Mar 16, 2025


Large Language Model (LLM) development has become increasingly centralized, limiting participation to well-resourced organizations. This paper introduces MoECollab, a novel framework leveraging Mixture of Experts (MoE) architecture to enable distributed, collaborative LLM development. By decomposing monolithic models into specialized expert modules coordinated by a trainable gating network, our framework allows diverse contributors to participate regardless of computational resources. We provide a complete technical implementation with mathematical foundations for expert dynamics, gating mechanisms, and integration strategies. Experiments on multiple datasets demonstrate that our approach achieves accuracy improvements of 3-7% over baseline models while reducing computational requirements by 34%. Expert specialization yields significant domain-specific gains, with improvements from 51% to 88% F1 score in general classification and from 23% to 44% accuracy in news categorization. We formalize the routing entropy optimization problem and demonstrate how proper regularization techniques lead to 14% higher expert utilization rates. These results validate MoECollab as an effective approach for democratizing LLM development through architecturally-supported collaboration.
VISTA: A Visual and Textual Attention Dataset for Interpreting Multimodal Models
Oct 06, 2024The recent developments in deep learning led to the integration of natural language processing (NLP) with computer vision, resulting in powerful integrated Vision and Language Models (VLMs). Despite their remarkable capabilities, these models are frequently regarded as black boxes within the machine learning research community. This raises a critical question: which parts of an image correspond to specific segments of text, and how can we decipher these associations? Understanding these connections is essential for enhancing model transparency, interpretability, and trustworthiness. To answer this question, we present an image-text aligned human visual attention dataset that maps specific associations between image regions and corresponding text segments. We then compare the internal heatmaps generated by VL models with this dataset, allowing us to analyze and better understand the model's decision-making process. This approach aims to enhance model transparency, interpretability, and trustworthiness by providing insights into how these models align visual and linguistic information. We conducted a comprehensive study on text-guided visual saliency detection in these VL models. This study aims to understand how different models prioritize and focus on specific visual elements in response to corresponding text segments, providing deeper insights into their internal mechanisms and improving our ability to interpret their outputs.
Transparent Object Tracking Benchmark
Nov 21, 2020
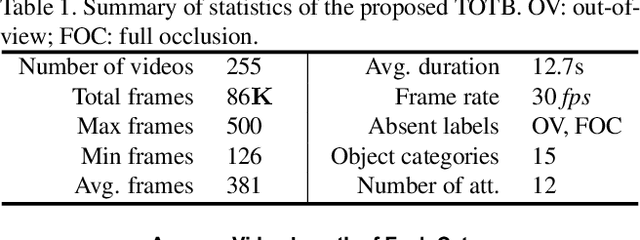
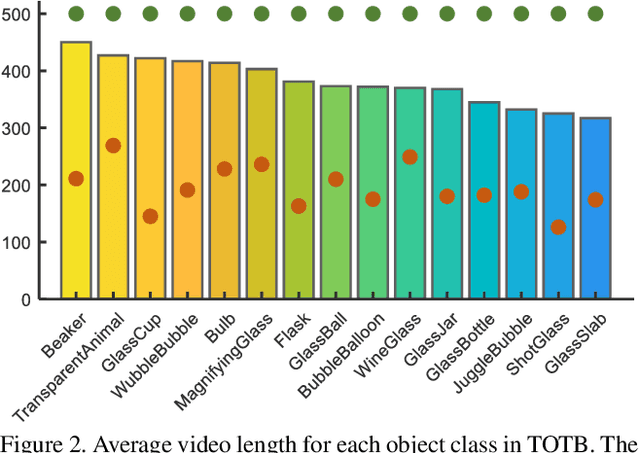
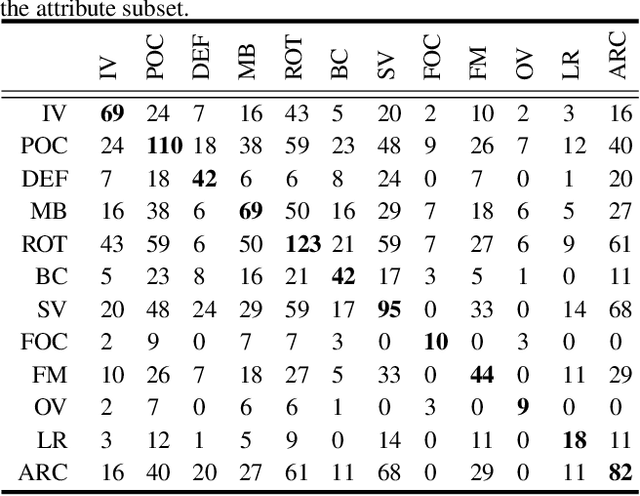
Visual tracking has achieved considerable progress in recent years. However, current research in the field mainly focuses on tracking of opaque objects, while little attention is paid to transparent object tracking. In this paper, we make the first attempt in exploring this problem by proposing a Transparent Object Tracking Benchmark (TOTB). Specifically, TOTB consists of 225 videos (86K frames) from 15 diverse transparent object categories. Each sequence is manually labeled with axis-aligned bounding boxes. To the best of our knowledge, TOTB is the first benchmark dedicated to transparent object tracking. In order to understand how existing trackers perform and to provide comparison for future research on TOTB, we extensively evaluate 25 state-of-the-art tracking algorithms. The evaluation results exhibit that more efforts are needed to improve transparent object tracking. Besides, we observe some nontrivial findings from the evaluation that are discrepant with some common beliefs in opaque object tracking. For example, we find that deep(er) features are not always good for improvements. Moreover, to encourage future research, we introduce a novel tracker, named TransATOM, which leverages transparency features for tracking and surpasses all 25 evaluated approaches by a large margin. By releasing TOTB, we expect to facilitate future research and application of transparent object tracking in both the academia and industry. The TOTB and evaluation results as well as TransATOM will be made available at https://hengfan2010.github.io/projects/TOTB.
LaSOT: A High-quality Large-scale Single Object Tracking Benchmark
Sep 12, 2020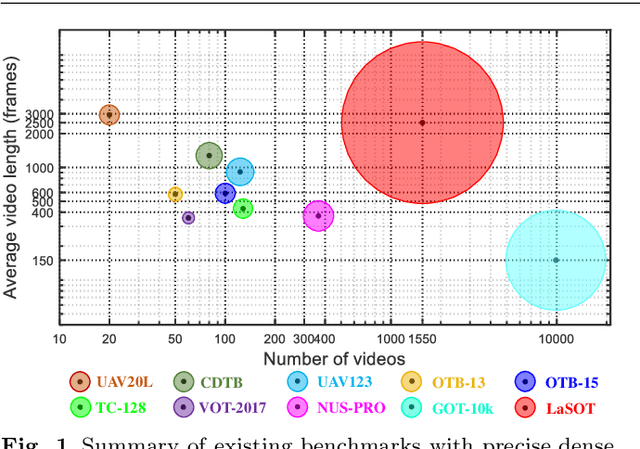
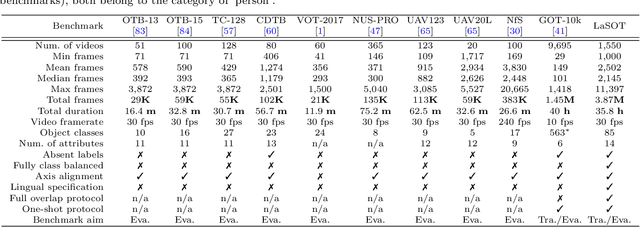
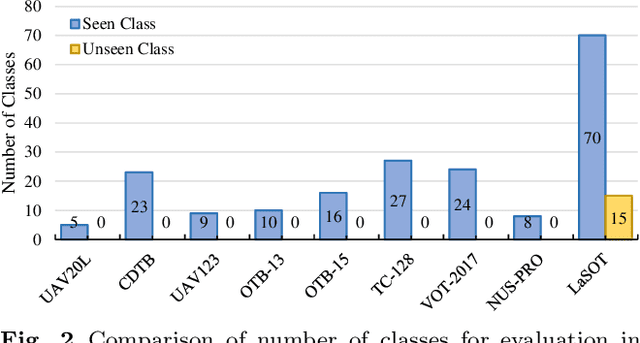

Despite great recent advances in visual tracking, its further development, including both algorithm design and evaluation, is limited due to lack of dedicated large-scale benchmarks. To address this problem, we present LaSOT, a high-quality Large-scale Single Object Tracking benchmark. LaSOT contains a diverse selection of 85 object classes, and offers 1,550 totaling more than 3.87 million frames. Each video frame is carefully and manually annotated with a bounding box. This makes LaSOT, to our knowledge, the largest densely annotated tracking benchmark. Our goal in releasing LaSOT is to provide a dedicated high quality platform for both training and evaluation of trackers. The average video length of LaSOT is around 2,500 frames, where each video contains various challenge factors that exist in real world video footage,such as the targets disappearing and re-appearing. These longer video lengths allow for the assessment of long-term trackers. To take advantage of the close connection between visual appearance and natural language, we provide language specification for each video in LaSOT. We believe such additions will allow for future research to use linguistic features to improve tracking. Two protocols, full-overlap and one-shot, are designated for flexible assessment of trackers. We extensively evaluate 48 baseline trackers on LaSOT with in-depth analysis, and results reveal that there still exists significant room for improvement. The complete benchmark, tracking results as well as analysis are available at http://vision.cs.stonybrook.edu/~lasot/.