 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext Forcing: Causal World Modeling with Multi-Chunk Prediction
Jun 09, 2026Autoregressive video generation has emerged as a powerful paradigm for World Action Models (WAMs). However, existing approaches suffer from slow training convergence and limited converged accuracy, particularly at high frame rates, as the training supervision is confined to the current chunk without explicit signals about future dynamics; they also suffer from slow inference due to iterative video denoising. In this paper, we present Next Forcing, a multi-chunk prediction (MCP) framework for causal world modeling that enables faster training, higher accuracy, and accelerated inference. Inspired by multi-token prediction in large language models, Next Forcing introduces an MCP training objective that augments the main model with lightweight auxiliary MCP modules to simultaneously denoise video chunks at multiple future temporal horizons (next$^1$, next$^2$, next$^3$ chunks). These MCP modules form a causal chain across prediction depths, where intermediate features fused from multiple layers of the main model are leveraged to predict future dynamics, allowing near-future predictions to inform farther-future ones and providing dense multi-scale temporal supervision back to the main model. During training, the MCP modules significantly accelerate convergence and improve converged accuracy, especially at high frame rates: at 50 fps, Next Forcing achieves a 93.1% relative improvement over LingBot-VA at 5k training steps and 2.3x faster convergence, and establishes new state-of-the-art results on the RoboTwin benchmark (94.1/93.5% on Clean/Random). At inference, the MCP modules can be retained to predict the next video chunk in parallel with the current one, achieving 2x inference acceleration. Next Forcing also demonstrates significant improvements on PhyWorld, a benchmark evaluating adherence to physical laws in video generation, and over 50% FVD reduction on general video pretraining.
PointForward: Feedforward Driving Reconstruction through Point-Aligned Representations
May 12, 2026High-fidelity reconstruction of driving scenes is crucial for autonomous driving. While recent feedforward 3D Gaussian Splatting (3DGS) methods enable fast reconstruction, their per-pixel Gaussian prediction paradigm often suffers from multi-view inconsistency and layering artifacts. Moreover, existing methods often model dynamic instances via dense flow prediction, which lacks explicit cross-view correspondence and instance-level consistency. In this paper, we propose PointForward, a feedforward driving reconstruction framework through point-aligned representations. Unlike pixel-aligned methods, we initialize sparse 3D queries in world space and aggregate multi-view image information via spatial-temporal fusion onto these queries, enforcing explicit cross-view consistency in a single feedforward pass. To handle scene dynamics, we introduce scene graphs that explicitly organize moving instances during reconstruction. By leveraging 3D bounding boxes, our method enables instance-level motion propagation and temporally consistent dynamic representations. Extensive experiments demonstrate that PointForward achieves state-of-the-art performance on large-scale driving benchmarks. The code will be available upon the publication of the paper.
PCSTracker: Long-Term Scene Flow Estimation for Point Cloud Sequences
Mar 20, 2026Point cloud scene flow estimation is fundamental to long-term and fine-grained 3D motion analysis. However, existing methods are typically limited to pairwise settings and struggle to maintain temporal consistency over long sequences as geometry evolves, occlusions emerge, and errors accumulate. In this work, we propose PCSTracker, the first end-to-end framework specifically designed for consistent scene flow estimation in point cloud sequences. Specifically, we introduce an iterative geometry motion joint optimization module (IGMO) that explicitly models the temporal evolution of point features to alleviate correspondence inconsistencies caused by dynamic geometric changes. In addition, a spatio-temporal point trajectory update module (STTU) is proposed to leverage broad temporal context to infer plausible positions for occluded points, ensuring coherent motion estimation. To further handle long sequences, we employ an overlapping sliding-window inference strategy that alternates cross-window propagation and in-window refinement, effectively suppressing error accumulation and maintaining stable long-term motion consistency. Extensive experiments on the synthetic PointOdyssey3D and real-world ADT3D datasets show that PCSTracker achieves the best accuracy in long-term scene flow estimation and maintains real-time performance at 32.5 FPS, while demonstrating superior 3D motion understanding compared to RGB-D-based approaches.
PromptStereo: Zero-Shot Stereo Matching via Structure and Motion Prompts
Mar 03, 2026Modern stereo matching methods have leveraged monocular depth foundation models to achieve superior zero-shot generalization performance. However, most existing methods primarily focus on extracting robust features for cost volume construction or disparity initialization. At the same time, the iterative refinement stage, which is also crucial for zero-shot generalization, remains underexplored. Some methods treat monocular depth priors as guidance for iteration, but conventional GRU-based architectures struggle to exploit them due to the limited representation capacity. In this paper, we propose Prompt Recurrent Unit (PRU), a novel iterative refinement module based on the decoder of monocular depth foundation models. By integrating monocular structure and stereo motion cues as prompts into the decoder, PRU enriches the latent representations of monocular depth foundation models with absolute stereo-scale information while preserving their inherent monocular depth priors. Experiments demonstrate that our PromptStereo achieves state-of-the-art zero-shot generalization performance across multiple datasets, while maintaining comparable or faster inference speed. Our findings highlight prompt-guided iterative refinement as a promising direction for zero-shot stereo matching.
Pixel-Perfect Depth with Semantics-Prompted Diffusion Transformers
Oct 08, 2025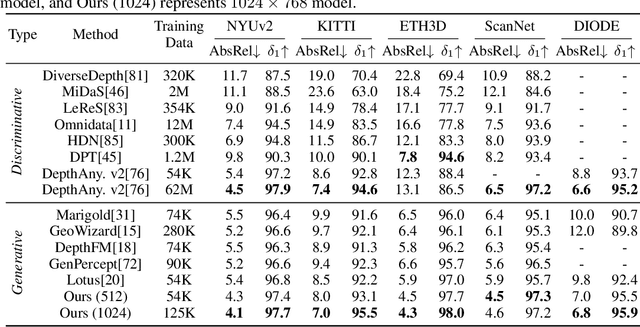

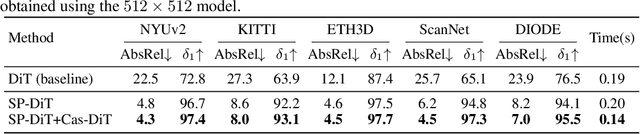
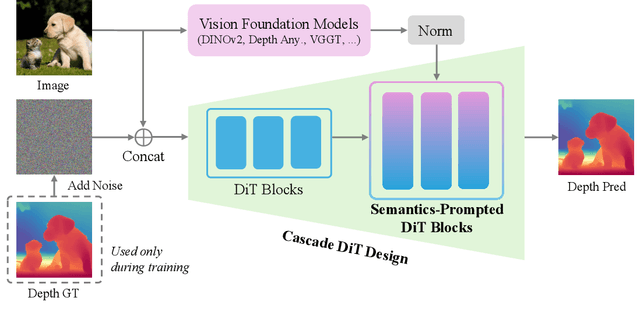
This paper presents Pixel-Perfect Depth, a monocular depth estimation model based on pixel-space diffusion generation that produces high-quality, flying-pixel-free point clouds from estimated depth maps. Current generative depth estimation models fine-tune Stable Diffusion and achieve impressive performance. However, they require a VAE to compress depth maps into latent space, which inevitably introduces \textit{flying pixels} at edges and details. Our model addresses this challenge by directly performing diffusion generation in the pixel space, avoiding VAE-induced artifacts. To overcome the high complexity associated with pixel-space generation, we introduce two novel designs: 1) Semantics-Prompted Diffusion Transformers (SP-DiT), which incorporate semantic representations from vision foundation models into DiT to prompt the diffusion process, thereby preserving global semantic consistency while enhancing fine-grained visual details; and 2) Cascade DiT Design that progressively increases the number of tokens to further enhance efficiency and accuracy. Our model achieves the best performance among all published generative models across five benchmarks, and significantly outperforms all other models in edge-aware point cloud evaluation.
ReCogDrive: A Reinforced Cognitive Framework for End-to-End Autonomous Driving
Jun 09, 2025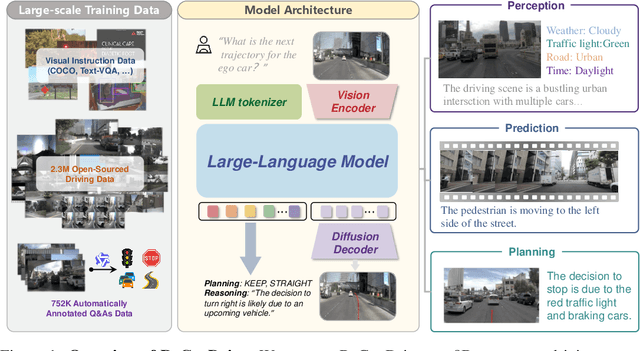
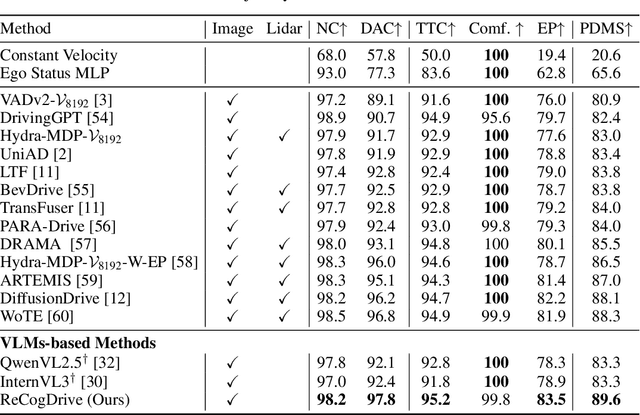
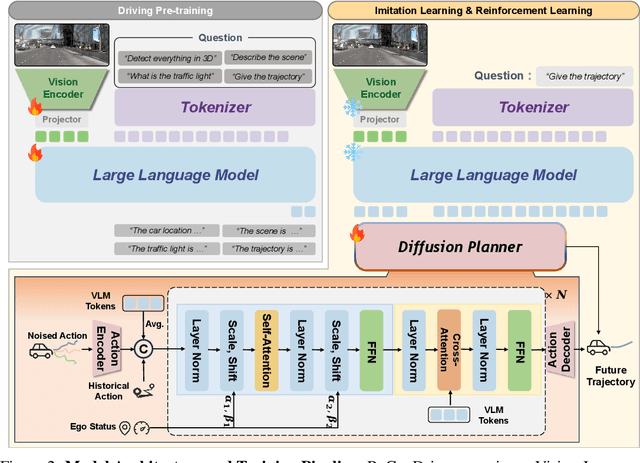
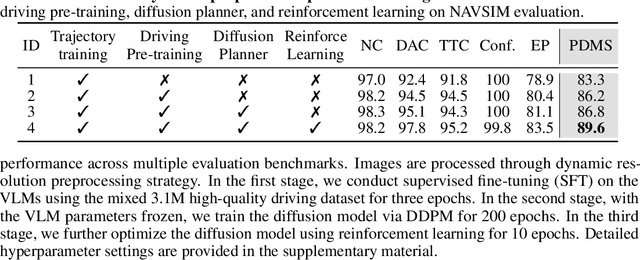
Although end-to-end autonomous driving has made remarkable progress, its performance degrades significantly in rare and long-tail scenarios. Recent approaches attempt to address this challenge by leveraging the rich world knowledge of Vision-Language Models (VLMs), but these methods suffer from several limitations: (1) a significant domain gap between the pre-training data of VLMs and real-world driving data, (2) a dimensionality mismatch between the discrete language space and the continuous action space, and (3) imitation learning tends to capture the average behavior present in the dataset, which may be suboptimal even dangerous. In this paper, we propose ReCogDrive, an autonomous driving system that integrates VLMs with diffusion planner, which adopts a three-stage paradigm for training. In the first stage, we use a large-scale driving question-answering datasets to train the VLMs, mitigating the domain discrepancy between generic content and real-world driving scenarios. In the second stage, we employ a diffusion-based planner to perform imitation learning, mapping representations from the latent language space to continuous driving actions. Finally, we fine-tune the diffusion planner using reinforcement learning with NAVSIM non-reactive simulator, enabling the model to generate safer, more human-like driving trajectories. We evaluate our approach on the planning-oriented NAVSIM benchmark, achieving a PDMS of 89.6 and setting a new state-of-the-art that surpasses the previous vision-only SOTA by 5.6 PDMS.
Genesis: Multimodal Driving Scene Generation with Spatio-Temporal and Cross-Modal Consistency
Jun 09, 2025We present Genesis, a unified framework for joint generation of multi-view driving videos and LiDAR sequences with spatio-temporal and cross-modal consistency. Genesis employs a two-stage architecture that integrates a DiT-based video diffusion model with 3D-VAE encoding, and a BEV-aware LiDAR generator with NeRF-based rendering and adaptive sampling. Both modalities are directly coupled through a shared latent space, enabling coherent evolution across visual and geometric domains. To guide the generation with structured semantics, we introduce DataCrafter, a captioning module built on vision-language models that provides scene-level and instance-level supervision. Extensive experiments on the nuScenes benchmark demonstrate that Genesis achieves state-of-the-art performance across video and LiDAR metrics (FVD 16.95, FID 4.24, Chamfer 0.611), and benefits downstream tasks including segmentation and 3D detection, validating the semantic fidelity and practical utility of the generated data.
BANet: Bilateral Aggregation Network for Mobile Stereo Matching
Mar 05, 2025State-of-the-art stereo matching methods typically use costly 3D convolutions to aggregate a full cost volume, but their computational demands make mobile deployment challenging. Directly applying 2D convolutions for cost aggregation often results in edge blurring, detail loss, and mismatches in textureless regions. Some complex operations, like deformable convolutions and iterative warping, can partially alleviate this issue; however, they are not mobile-friendly, limiting their deployment on mobile devices. In this paper, we present a novel bilateral aggregation network (BANet) for mobile stereo matching that produces high-quality results with sharp edges and fine details using only 2D convolutions. Specifically, we first separate the full cost volume into detailed and smooth volumes using a spatial attention map, then perform detailed and smooth aggregations accordingly, ultimately fusing both to obtain the final disparity map. Additionally, to accurately identify high-frequency detailed regions and low-frequency smooth/textureless regions, we propose a new scale-aware spatial attention module. Experimental results demonstrate that our BANet-2D significantly outperforms other mobile-friendly methods, achieving 35.3\% higher accuracy on the KITTI 2015 leaderboard than MobileStereoNet-2D, with faster runtime on mobile devices. The extended 3D version, BANet-3D, achieves the highest accuracy among all real-time methods on high-end GPUs. Code: \textcolor{magenta}{https://github.com/gangweiX/BANet}.
BAT: Learning Event-based Optical Flow with Bidirectional Adaptive Temporal Correlation
Mar 05, 2025Event cameras deliver visual information characterized by a high dynamic range and high temporal resolution, offering significant advantages in estimating optical flow for complex lighting conditions and fast-moving objects. Current advanced optical flow methods for event cameras largely adopt established image-based frameworks. However, the spatial sparsity of event data limits their performance. In this paper, we present BAT, an innovative framework that estimates event-based optical flow using bidirectional adaptive temporal correlation. BAT includes three novel designs: 1) a bidirectional temporal correlation that transforms bidirectional temporally dense motion cues into spatially dense ones, enabling accurate and spatially dense optical flow estimation; 2) an adaptive temporal sampling strategy for maintaining temporal consistency in correlation; 3) spatially adaptive temporal motion aggregation to efficiently and adaptively aggregate consistent target motion features into adjacent motion features while suppressing inconsistent ones. Our results rank $1^{st}$ on the DSEC-Flow benchmark, outperforming existing state-of-the-art methods by a large margin while also exhibiting sharp edges and high-quality details. Notably, our BAT can accurately predict future optical flow using only past events, significantly outperforming E-RAFT's warm-start approach. Code: \textcolor{magenta}{https://github.com/gangweiX/BAT}.
StereoGen: High-quality Stereo Image Generation from a Single Image
Jan 15, 2025State-of-the-art supervised stereo matching methods have achieved amazing results on various benchmarks. However, these data-driven methods suffer from generalization to real-world scenarios due to the lack of real-world annotated data. In this paper, we propose StereoGen, a novel pipeline for high-quality stereo image generation. This pipeline utilizes arbitrary single images as left images and pseudo disparities generated by a monocular depth estimation model to synthesize high-quality corresponding right images. Unlike previous methods that fill the occluded area in warped right images using random backgrounds or using convolutions to take nearby pixels selectively, we fine-tune a diffusion inpainting model to recover the background. Images generated by our model possess better details and undamaged semantic structures. Besides, we propose Training-free Confidence Generation and Adaptive Disparity Selection. The former suppresses the negative effect of harmful pseudo ground truth during stereo training, while the latter helps generate a wider disparity distribution and better synthetic images. Experiments show that models trained under our pipeline achieve state-of-the-art zero-shot generalization results among all published methods. The code will be available upon publication of the paper.