 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepSeek-V3 Technical Report
Dec 27, 2024



We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
Leveraging Consistent Spatio-Temporal Correspondence for Robust Visual Odometry
Dec 22, 2024



Recent approaches to VO have significantly improved performance by using deep networks to predict optical flow between video frames. However, existing methods still suffer from noisy and inconsistent flow matching, making it difficult to handle challenging scenarios and long-sequence estimation. To overcome these challenges, we introduce Spatio-Temporal Visual Odometry (STVO), a novel deep network architecture that effectively leverages inherent spatio-temporal cues to enhance the accuracy and consistency of multi-frame flow matching. With more accurate and consistent flow matching, STVO can achieve better pose estimation through the bundle adjustment (BA). Specifically, STVO introduces two innovative components: 1) the Temporal Propagation Module that utilizes multi-frame information to extract and propagate temporal cues across adjacent frames, maintaining temporal consistency; 2) the Spatial Activation Module that utilizes geometric priors from the depth maps to enhance spatial consistency while filtering out excessive noise and incorrect matches. Our STVO achieves state-of-the-art performance on TUM-RGBD, EuRoc MAV, ETH3D and KITTI Odometry benchmarks. Notably, it improves accuracy by 77.8% on ETH3D benchmark and 38.9% on KITTI Odometry benchmark over the previous best methods.
3D Multi-Object Tracking with Semi-Supervised GRU-Kalman Filter
Nov 13, 2024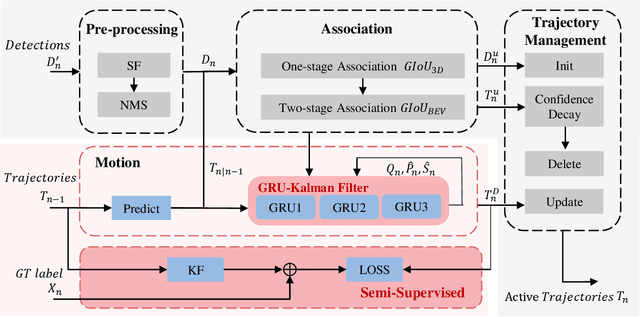
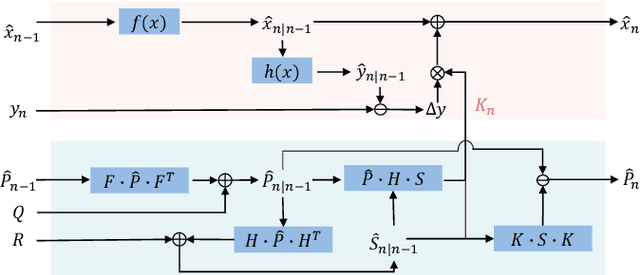
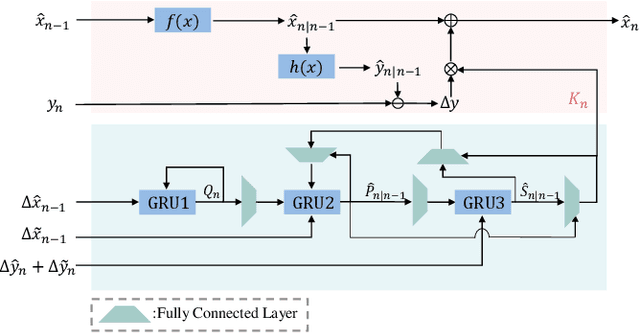
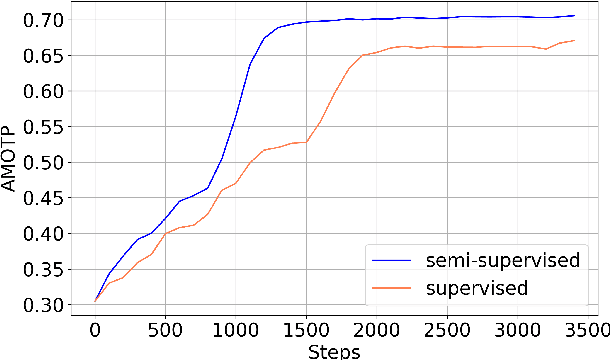
3D Multi-Object Tracking (MOT), a fundamental component of environmental perception, is essential for intelligent systems like autonomous driving and robotic sensing. Although Tracking-by-Detection frameworks have demonstrated excellent performance in recent years, their application in real-world scenarios faces significant challenges. Object movement in complex environments is often highly nonlinear, while existing methods typically rely on linear approximations of motion. Furthermore, system noise is frequently modeled as a Gaussian distribution, which fails to capture the true complexity of the noise dynamics. These oversimplified modeling assumptions can lead to significant reductions in tracking precision. To address this, we propose a GRU-based MOT method, which introduces a learnable Kalman filter into the motion module. This approach is able to learn object motion characteristics through data-driven learning, thereby avoiding the need for manual model design and model error. At the same time, to avoid abnormal supervision caused by the wrong association between annotations and trajectories, we design a semi-supervised learning strategy to accelerate the convergence speed and improve the robustness of the model. Evaluation experiment on the nuScenes and Argoverse2 datasets demonstrates that our system exhibits superior performance and significant potential compared to traditional TBD methods.
Panoramic Direct LiDAR-assisted Visual Odometry
Sep 14, 2024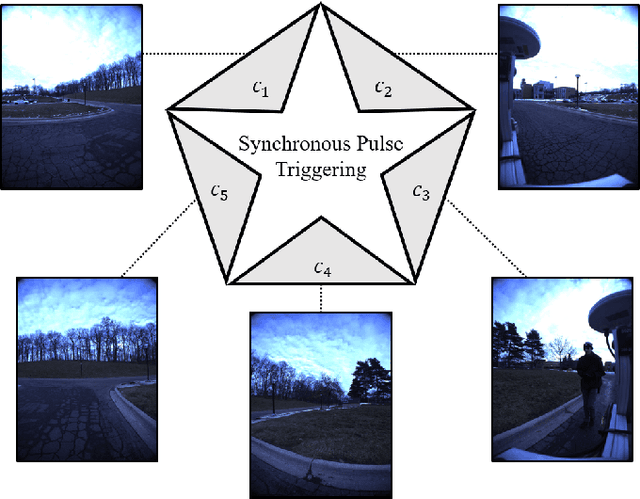
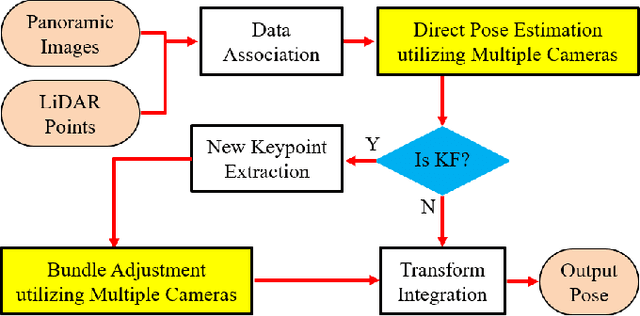
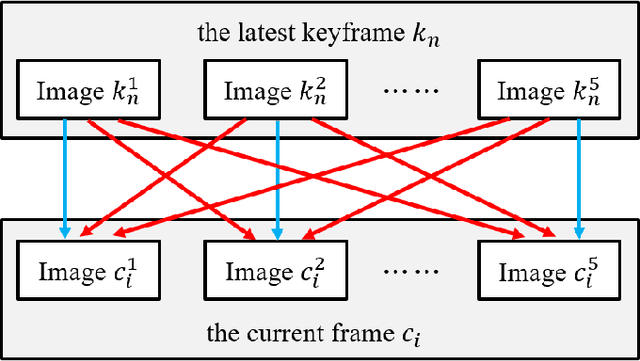
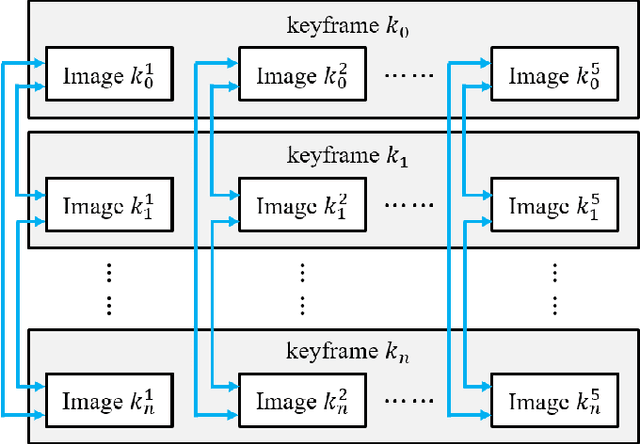
Enhancing visual odometry by exploiting sparse depth measurements from LiDAR is a promising solution for improving tracking accuracy of an odometry. Most existing works utilize a monocular pinhole camera, yet could suffer from poor robustness due to less available information from limited field-of-view (FOV). This paper proposes a panoramic direct LiDAR-assisted visual odometry, which fully associates the 360-degree FOV LiDAR points with the 360-degree FOV panoramic image datas. 360-degree FOV panoramic images can provide more available information, which can compensate inaccurate pose estimation caused by insufficient texture or motion blur from a single view. In addition to constraints between a specific view at different times, constraints can also be built between different views at the same moment. Experimental results on public datasets demonstrate the benefit of large FOV of our panoramic direct LiDAR-assisted visual odometry to state-of-the-art approaches.
* 6 pages, 6 figures
A Fast Dynamic Point Detection Method for LiDAR-Inertial Odometry in Driving Scenarios
Jul 04, 2024
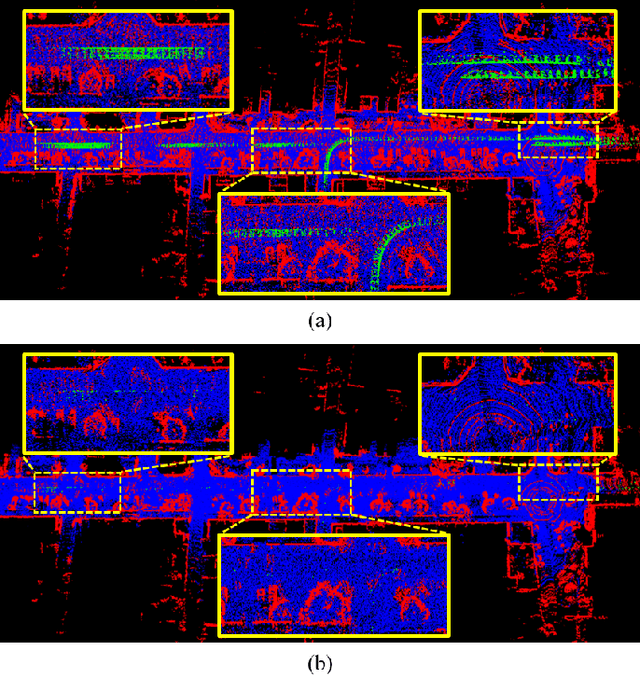


Existing 3D point-based dynamic point detection and removal methods have a significant time overhead, making them difficult to adapt to LiDAR-inertial odometry systems. This paper proposes a label consistency based dynamic point detection and removal method for handling moving vehicles and pedestrians in autonomous driving scenarios, and embeds the proposed dynamic point detection and removal method into a self-designed LiDAR-inertial odometry system. Experimental results on three public datasets demonstrate that our method can accomplish the dynamic point detection and removal with extremely low computational overhead (i.e., 1$\sim$9ms) in LIO systems, meanwhile achieve comparable preservation rate and rejection rate to state-of-the-art methods and significantly enhance the accuracy of pose estimation. We have released the source code of this work for the development of the community.