 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Multi-Object Tracking with Semi-Supervised GRU-Kalman Filter
Nov 13, 2024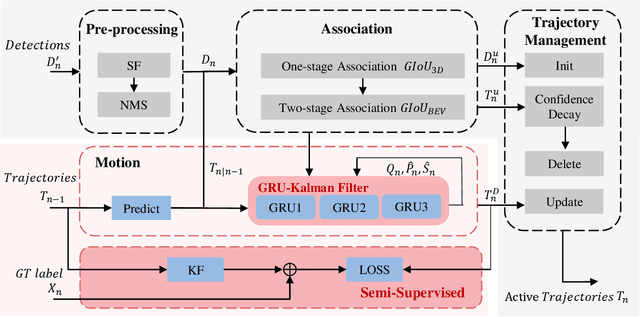
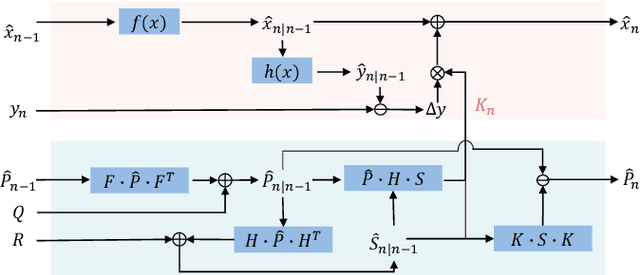
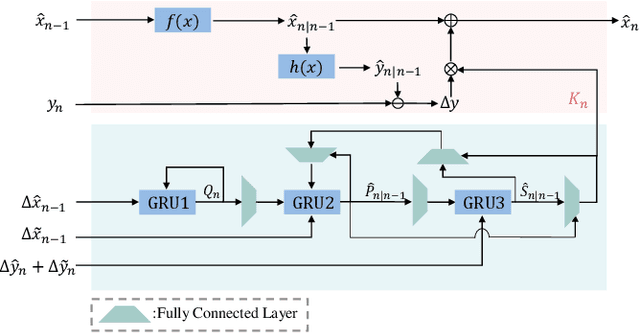
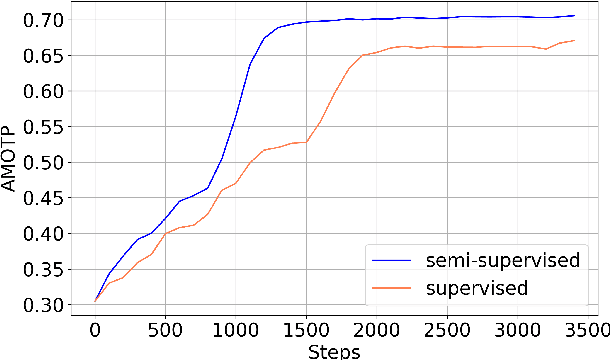
3D Multi-Object Tracking (MOT), a fundamental component of environmental perception, is essential for intelligent systems like autonomous driving and robotic sensing. Although Tracking-by-Detection frameworks have demonstrated excellent performance in recent years, their application in real-world scenarios faces significant challenges. Object movement in complex environments is often highly nonlinear, while existing methods typically rely on linear approximations of motion. Furthermore, system noise is frequently modeled as a Gaussian distribution, which fails to capture the true complexity of the noise dynamics. These oversimplified modeling assumptions can lead to significant reductions in tracking precision. To address this, we propose a GRU-based MOT method, which introduces a learnable Kalman filter into the motion module. This approach is able to learn object motion characteristics through data-driven learning, thereby avoiding the need for manual model design and model error. At the same time, to avoid abnormal supervision caused by the wrong association between annotations and trajectories, we design a semi-supervised learning strategy to accelerate the convergence speed and improve the robustness of the model. Evaluation experiment on the nuScenes and Argoverse2 datasets demonstrates that our system exhibits superior performance and significant potential compared to traditional TBD methods.
FlowDA: Unsupervised Domain Adaptive Framework for Optical Flow Estimation
Dec 28, 2023Collecting real-world optical flow datasets is a formidable challenge due to the high cost of labeling. A shortage of datasets significantly constrains the real-world performance of optical flow models. Building virtual datasets that resemble real scenarios offers a potential solution for performance enhancement, yet a domain gap separates virtual and real datasets. This paper introduces FlowDA, an unsupervised domain adaptive (UDA) framework for optical flow estimation. FlowDA employs a UDA architecture based on mean-teacher and integrates concepts and techniques in unsupervised optical flow estimation. Furthermore, an Adaptive Curriculum Weighting (ACW) module based on curriculum learning is proposed to enhance the training effectiveness. Experimental outcomes demonstrate that our FlowDA outperforms state-of-the-art unsupervised optical flow estimation method SMURF by 21.6%, real optical flow dataset generation method MPI-Flow by 27.8%, and optical flow estimation adaptive method FlowSupervisor by 30.9%, offering novel insights for enhancing the performance of optical flow estimation in real-world scenarios. The code will be open-sourced after the publication of this paper.
Memory-Efficient Optical Flow via Radius-Distribution Orthogonal Cost Volume
Dec 06, 2023



The full 4D cost volume in Recurrent All-Pairs Field Transforms (RAFT) or global matching by Transformer achieves impressive performance for optical flow estimation. However, their memory consumption increases quadratically with input resolution, rendering them impractical for high-resolution images. In this paper, we present MeFlow, a novel memory-efficient method for high-resolution optical flow estimation. The key of MeFlow is a recurrent local orthogonal cost volume representation, which decomposes the 2D search space dynamically into two 1D orthogonal spaces, enabling our method to scale effectively to very high-resolution inputs. To preserve essential information in the orthogonal space, we utilize self attention to propagate feature information from the 2D space to the orthogonal space. We further propose a radius-distribution multi-scale lookup strategy to model the correspondences of large displacements at a negligible cost. We verify the efficiency and effectiveness of our method on the challenging Sintel and KITTI benchmarks, and real-world 4K ($2160\!\times\!3840$) images. Our method achieves competitive performance on both Sintel and KITTI benchmarks, while maintaining the highest memory efficiency on high-resolution inputs.
MC-Stereo: Multi-peak Lookup and Cascade Search Range for Stereo Matching
Nov 04, 2023Stereo matching is a fundamental task in scene comprehension. In recent years, the method based on iterative optimization has shown promise in stereo matching. However, the current iteration framework employs a single-peak lookup, which struggles to handle the multi-peak problem effectively. Additionally, the fixed search range used during the iteration process limits the final convergence effects. To address these issues, we present a novel iterative optimization architecture called MC-Stereo. This architecture mitigates the multi-peak distribution problem in matching through the multi-peak lookup strategy, and integrates the coarse-to-fine concept into the iterative framework via the cascade search range. Furthermore, given that feature representation learning is crucial for successful learnbased stereo matching, we introduce a pre-trained network to serve as the feature extractor, enhancing the front end of the stereo matching pipeline. Based on these improvements, MC-Stereo ranks first among all publicly available methods on the KITTI-2012 and KITTI-2015 benchmarks, and also achieves state-of-the-art performance on ETH3D. The code will be open sourced after the publication of this paper.