 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProactiveMobile: A Comprehensive Benchmark for Boosting Proactive Intelligence on Mobile Devices
Feb 26, 2026Multimodal large language models (MLLMs) have made significant progress in mobile agent development, yet their capabilities are predominantly confined to a reactive paradigm, where they merely execute explicit user commands. The emerging paradigm of proactive intelligence, where agents autonomously anticipate needs and initiate actions, represents the next frontier for mobile agents. However, its development is critically bottlenecked by the lack of benchmarks that can address real-world complexity and enable objective, executable evaluation. To overcome these challenges, we introduce ProactiveMobile, a comprehensive benchmark designed to systematically advance research in this domain. ProactiveMobile formalizes the proactive task as inferring latent user intent across four dimensions of on-device contextual signals and generating an executable function sequence from a comprehensive function pool of 63 APIs. The benchmark features over 3,660 instances of 14 scenarios that embrace real-world complexity through multi-answer annotations. To ensure quality, a team of 30 experts conducts a final audit of the benchmark, verifying factual accuracy, logical consistency, and action feasibility, and correcting any non-compliant entries. Extensive experiments demonstrate that our fine-tuned Qwen2.5-VL-7B-Instruct achieves a success rate of 19.15%, outperforming o1 (15.71%) and GPT-5 (7.39%). This result indicates that proactivity is a critical competency widely lacking in current MLLMs, yet it is learnable, emphasizing the importance of the proposed benchmark for proactivity evaluation.
Zephyr quantum-assisted hierarchical Calo4pQVAE for particle-calorimeter interactions
Dec 06, 2024With the approach of the High Luminosity Large Hadron Collider (HL-LHC) era set to begin particle collisions by the end of this decade, it is evident that the computational demands of traditional collision simulation methods are becoming increasingly unsustainable. Existing approaches, which rely heavily on first-principles Monte Carlo simulations for modeling event showers in calorimeters, are projected to require millions of CPU-years annually -- far exceeding current computational capacities. This bottleneck presents an exciting opportunity for advancements in computational physics by integrating deep generative models with quantum simulations. We propose a quantum-assisted hierarchical deep generative surrogate founded on a variational autoencoder (VAE) in combination with an energy conditioned restricted Boltzmann machine (RBM) embedded in the model's latent space as a prior. By mapping the topology of D-Wave's Zephyr quantum annealer (QA) into the nodes and couplings of a 4-partite RBM, we leverage quantum simulation to accelerate our shower generation times significantly. To evaluate our framework, we use Dataset 2 of the CaloChallenge 2022. Through the integration of classical computation and quantum simulation, this hybrid framework paves way for utilizing large-scale quantum simulations as priors in deep generative models.
Conditioned quantum-assisted deep generative surrogate for particle-calorimeter interactions
Oct 30, 2024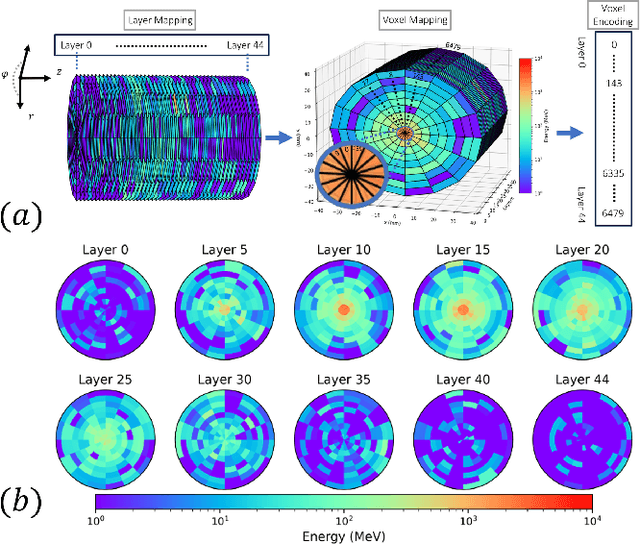
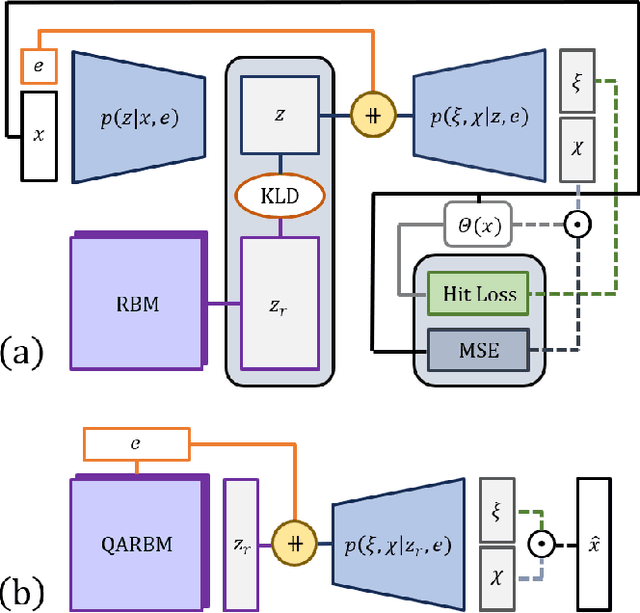
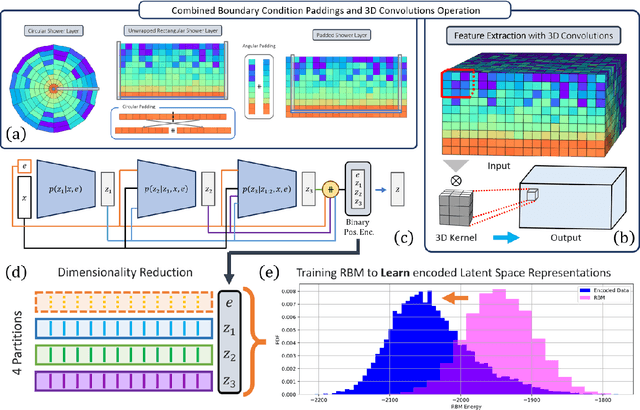
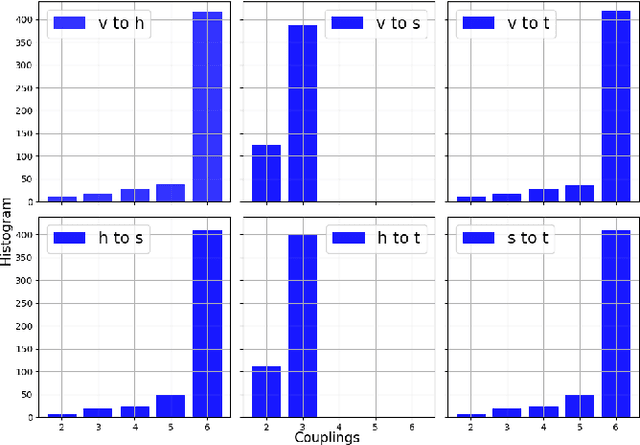
Particle collisions at accelerators such as the Large Hadron Collider, recorded and analyzed by experiments such as ATLAS and CMS, enable exquisite measurements of the Standard Model and searches for new phenomena. Simulations of collision events at these detectors have played a pivotal role in shaping the design of future experiments and analyzing ongoing ones. However, the quest for accuracy in Large Hadron Collider (LHC) collisions comes at an imposing computational cost, with projections estimating the need for millions of CPU-years annually during the High Luminosity LHC (HL-LHC) run \cite{collaboration2022atlas}. Simulating a single LHC event with \textsc{Geant4} currently devours around 1000 CPU seconds, with simulations of the calorimeter subdetectors in particular imposing substantial computational demands \cite{rousseau2023experimental}. To address this challenge, we propose a conditioned quantum-assisted deep generative model. Our model integrates a conditioned variational autoencoder (VAE) on the exterior with a conditioned Restricted Boltzmann Machine (RBM) in the latent space, providing enhanced expressiveness compared to conventional VAEs. The RBM nodes and connections are meticulously engineered to enable the use of qubits and couplers on D-Wave's Pegasus-structured \textit{Advantage} quantum annealer (QA) for sampling. We introduce a novel method for conditioning the quantum-assisted RBM using \textit{flux biases}. We further propose a novel adaptive mapping to estimate the effective inverse temperature in quantum annealers. The effectiveness of our framework is illustrated using Dataset 2 of the CaloChallenge \cite{calochallenge}.
Selective-Stereo: Adaptive Frequency Information Selection for Stereo Matching
Mar 01, 2024Stereo matching methods based on iterative optimization, like RAFT-Stereo and IGEV-Stereo, have evolved into a cornerstone in the field of stereo matching. However, these methods struggle to simultaneously capture high-frequency information in edges and low-frequency information in smooth regions due to the fixed receptive field. As a result, they tend to lose details, blur edges, and produce false matches in textureless areas. In this paper, we propose Selective Recurrent Unit (SRU), a novel iterative update operator for stereo matching. The SRU module can adaptively fuse hidden disparity information at multiple frequencies for edge and smooth regions. To perform adaptive fusion, we introduce a new Contextual Spatial Attention (CSA) module to generate attention maps as fusion weights. The SRU empowers the network to aggregate hidden disparity information across multiple frequencies, mitigating the risk of vital hidden disparity information loss during iterative processes. To verify SRU's universality, we apply it to representative iterative stereo matching methods, collectively referred to as Selective-Stereo. Our Selective-Stereo ranks $1^{st}$ on KITTI 2012, KITTI 2015, ETH3D, and Middlebury leaderboards among all published methods. Code is available at https://github.com/Windsrain/Selective-Stereo.
FlowDA: Unsupervised Domain Adaptive Framework for Optical Flow Estimation
Dec 28, 2023Collecting real-world optical flow datasets is a formidable challenge due to the high cost of labeling. A shortage of datasets significantly constrains the real-world performance of optical flow models. Building virtual datasets that resemble real scenarios offers a potential solution for performance enhancement, yet a domain gap separates virtual and real datasets. This paper introduces FlowDA, an unsupervised domain adaptive (UDA) framework for optical flow estimation. FlowDA employs a UDA architecture based on mean-teacher and integrates concepts and techniques in unsupervised optical flow estimation. Furthermore, an Adaptive Curriculum Weighting (ACW) module based on curriculum learning is proposed to enhance the training effectiveness. Experimental outcomes demonstrate that our FlowDA outperforms state-of-the-art unsupervised optical flow estimation method SMURF by 21.6%, real optical flow dataset generation method MPI-Flow by 27.8%, and optical flow estimation adaptive method FlowSupervisor by 30.9%, offering novel insights for enhancing the performance of optical flow estimation in real-world scenarios. The code will be open-sourced after the publication of this paper.
CaloQVAE : Simulating high-energy particle-calorimeter interactions using hybrid quantum-classical generative models
Dec 15, 2023The Large Hadron Collider's high luminosity era presents major computational challenges in the analysis of collision events. Large amounts of Monte Carlo (MC) simulation will be required to constrain the statistical uncertainties of the simulated datasets below these of the experimental data. Modelling of high-energy particles propagating through the calorimeter section of the detector is the most computationally intensive MC simulation task. We introduce a technique combining recent advancements in generative models and quantum annealing for fast and efficient simulation of high-energy particle-calorimeter interactions.
Memory-Efficient Optical Flow via Radius-Distribution Orthogonal Cost Volume
Dec 06, 2023



The full 4D cost volume in Recurrent All-Pairs Field Transforms (RAFT) or global matching by Transformer achieves impressive performance for optical flow estimation. However, their memory consumption increases quadratically with input resolution, rendering them impractical for high-resolution images. In this paper, we present MeFlow, a novel memory-efficient method for high-resolution optical flow estimation. The key of MeFlow is a recurrent local orthogonal cost volume representation, which decomposes the 2D search space dynamically into two 1D orthogonal spaces, enabling our method to scale effectively to very high-resolution inputs. To preserve essential information in the orthogonal space, we utilize self attention to propagate feature information from the 2D space to the orthogonal space. We further propose a radius-distribution multi-scale lookup strategy to model the correspondences of large displacements at a negligible cost. We verify the efficiency and effectiveness of our method on the challenging Sintel and KITTI benchmarks, and real-world 4K ($2160\!\times\!3840$) images. Our method achieves competitive performance on both Sintel and KITTI benchmarks, while maintaining the highest memory efficiency on high-resolution inputs.
MC-Stereo: Multi-peak Lookup and Cascade Search Range for Stereo Matching
Nov 04, 2023Stereo matching is a fundamental task in scene comprehension. In recent years, the method based on iterative optimization has shown promise in stereo matching. However, the current iteration framework employs a single-peak lookup, which struggles to handle the multi-peak problem effectively. Additionally, the fixed search range used during the iteration process limits the final convergence effects. To address these issues, we present a novel iterative optimization architecture called MC-Stereo. This architecture mitigates the multi-peak distribution problem in matching through the multi-peak lookup strategy, and integrates the coarse-to-fine concept into the iterative framework via the cascade search range. Furthermore, given that feature representation learning is crucial for successful learnbased stereo matching, we introduce a pre-trained network to serve as the feature extractor, enhancing the front end of the stereo matching pipeline. Based on these improvements, MC-Stereo ranks first among all publicly available methods on the KITTI-2012 and KITTI-2015 benchmarks, and also achieves state-of-the-art performance on ETH3D. The code will be open sourced after the publication of this paper.
AdMix: A Mixed Sample Data Augmentation Method for Neural Machine Translation
May 10, 2022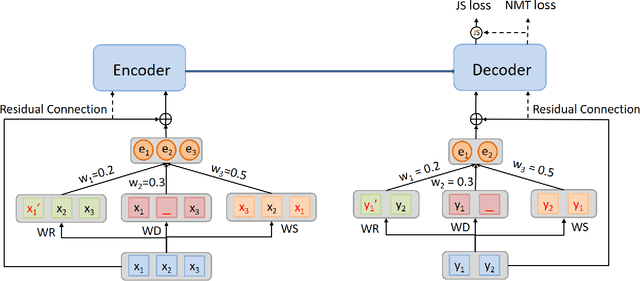
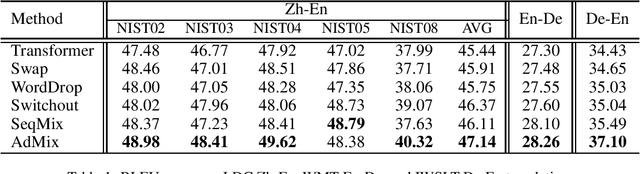
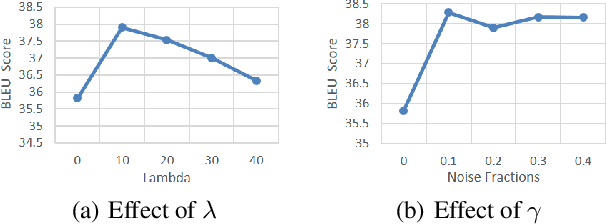
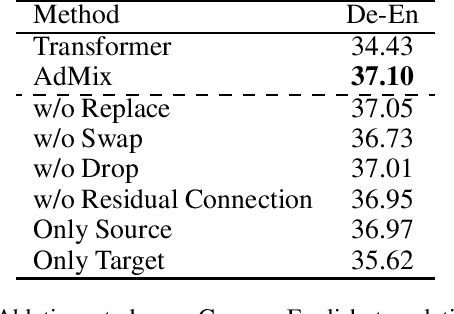
In Neural Machine Translation (NMT), data augmentation methods such as back-translation have proven their effectiveness in improving translation performance. In this paper, we propose a novel data augmentation approach for NMT, which is independent of any additional training data. Our approach, AdMix, consists of two parts: 1) introduce faint discrete noise (word replacement, word dropping, word swapping) into the original sentence pairs to form augmented samples; 2) generate new synthetic training data by softly mixing the augmented samples with their original samples in training corpus. Experiments on three translation datasets of different scales show that AdMix achieves signifi cant improvements (1.0 to 2.7 BLEU points) over strong Transformer baseline. When combined with other data augmentation techniques (e.g., back-translation), our approach can obtain further improvements.
Supervised Contrastive Learning with Structure Inference for Graph Classification
Mar 15, 2022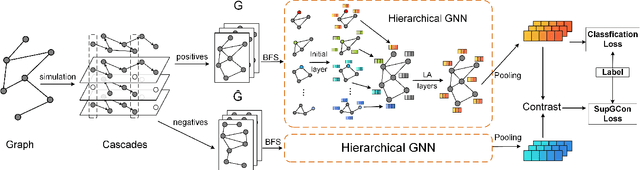
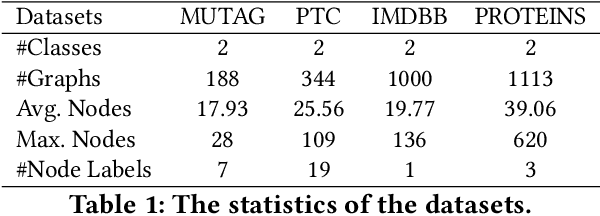
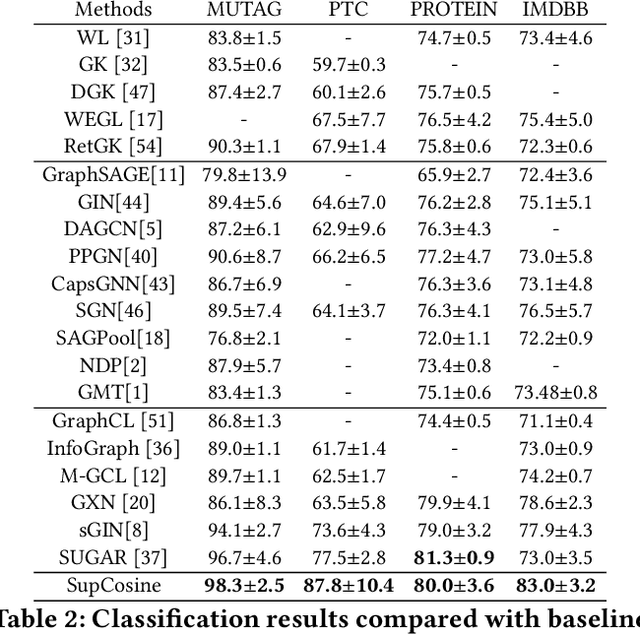
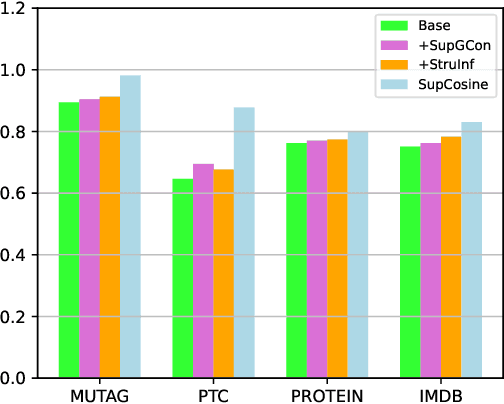
Advanced graph neural networks have shown great potentials in graph classification tasks recently. Different from node classification where node embeddings aggregated from local neighbors can be directly used to learn node labels, graph classification requires a hierarchical accumulation of different levels of topological information to generate discriminative graph embeddings. Still, how to fully explore graph structures and formulate an effective graph classification pipeline remains rudimentary. In this paper, we propose a novel graph neural network based on supervised contrastive learning with structure inference for graph classification. First, we propose a data-driven graph augmentation strategy that can discover additional connections to enhance the existing edge set. Concretely, we resort to a structure inference stage based on diffusion cascades to recover possible connections with high node similarities. Second, to improve the contrastive power of graph neural networks, we propose to use a supervised contrastive loss for graph classification. With the integration of label information, the one-vs-many contrastive learning can be extended to a many-vs-many setting, so that the graph-level embeddings with higher topological similarities will be pulled closer. The supervised contrastive loss and structure inference can be naturally incorporated within the hierarchical graph neural networks where the topological patterns can be fully explored to produce discriminative graph embeddings. Experiment results show the effectiveness of the proposed method compared with recent state-of-the-art methods.