 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisambiguated Lexically Constrained Neural Machine Translation
May 27, 2023Lexically constrained neural machine translation (LCNMT), which controls the translation generation with pre-specified constraints, is important in many practical applications. Current approaches to LCNMT typically assume that the pre-specified lexical constraints are contextually appropriate. This assumption limits their application to real-world scenarios where a source lexicon may have multiple target constraints, and disambiguation is needed to select the most suitable one. In this paper, we propose disambiguated LCNMT (D-LCNMT) to solve the problem. D-LCNMT is a robust and effective two-stage framework that disambiguates the constraints based on contexts at first, then integrates the disambiguated constraints into LCNMT. Experimental results show that our approach outperforms strong baselines including existing data augmentation based approaches on benchmark datasets, and comprehensive experiments in scenarios where a source lexicon corresponds to multiple target constraints demonstrate the constraint disambiguation superiority of our approach.
TSMind: Alibaba and Soochow University's Submission to the WMT22 Translation Suggestion Task
Nov 16, 2022This paper describes the joint submission of Alibaba and Soochow University, TSMind, to the WMT 2022 Shared Task on Translation Suggestion (TS). We participate in the English-German and English-Chinese tasks. Basically, we utilize the model paradigm fine-tuning on the downstream tasks based on large-scale pre-trained models, which has recently achieved great success. We choose FAIR's WMT19 English-German news translation system and MBART50 for English-Chinese as our pre-trained models. Considering the task's condition of limited use of training data, we follow the data augmentation strategies proposed by WeTS to boost our TS model performance. The difference is that we further involve the dual conditional cross-entropy model and GPT-2 language model to filter augmented data. The leader board finally shows that our submissions are ranked first in three of four language directions in the Naive TS task of the WMT22 Translation Suggestion task.
AdMix: A Mixed Sample Data Augmentation Method for Neural Machine Translation
May 10, 2022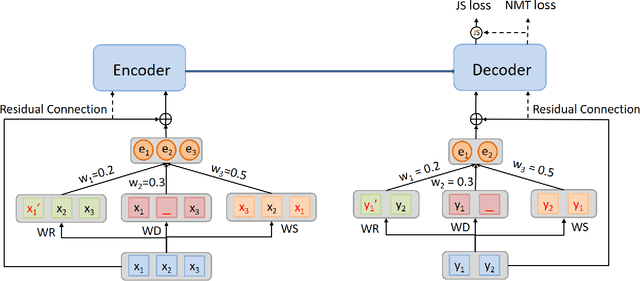
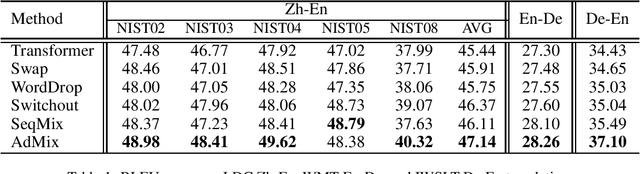
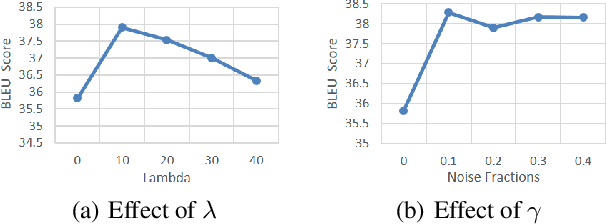
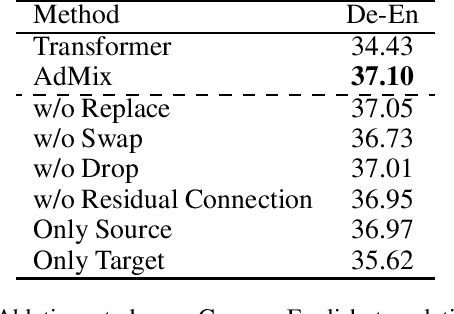
In Neural Machine Translation (NMT), data augmentation methods such as back-translation have proven their effectiveness in improving translation performance. In this paper, we propose a novel data augmentation approach for NMT, which is independent of any additional training data. Our approach, AdMix, consists of two parts: 1) introduce faint discrete noise (word replacement, word dropping, word swapping) into the original sentence pairs to form augmented samples; 2) generate new synthetic training data by softly mixing the augmented samples with their original samples in training corpus. Experiments on three translation datasets of different scales show that AdMix achieves signifi cant improvements (1.0 to 2.7 BLEU points) over strong Transformer baseline. When combined with other data augmentation techniques (e.g., back-translation), our approach can obtain further improvements.
Combining Static Word Embeddings and Contextual Representations for Bilingual Lexicon Induction
Jun 10, 2021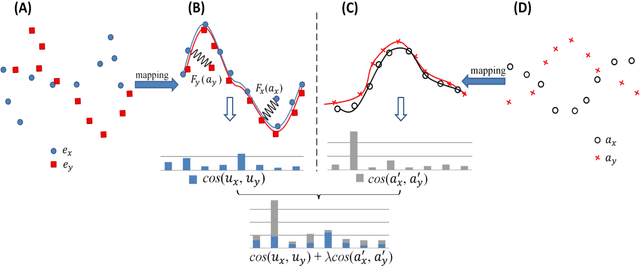
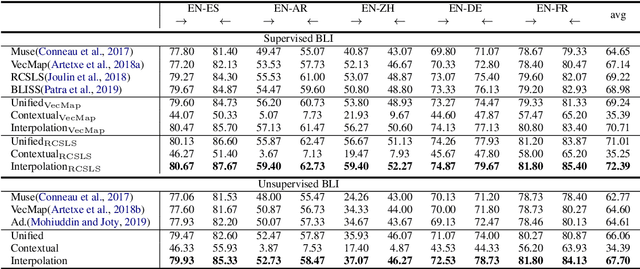
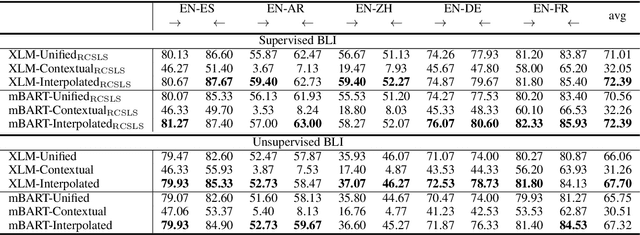

Bilingual Lexicon Induction (BLI) aims to map words in one language to their translations in another, and is typically through learning linear projections to align monolingual word representation spaces. Two classes of word representations have been explored for BLI: static word embeddings and contextual representations, but there is no studies to combine both. In this paper, we propose a simple yet effective mechanism to combine the static word embeddings and the contextual representations to utilize the advantages of both paradigms. We test the combination mechanism on various language pairs under the supervised and unsupervised BLI benchmark settings. Experiments show that our mechanism consistently improves performances over robust BLI baselines on all language pairs by averagely improving 3.2 points in the supervised setting, and 3.1 points in the unsupervised setting.