 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Glass-Box Features: Uncertainty Quantification Enhanced Quality Estimation for Neural Machine Translation
Sep 15, 2021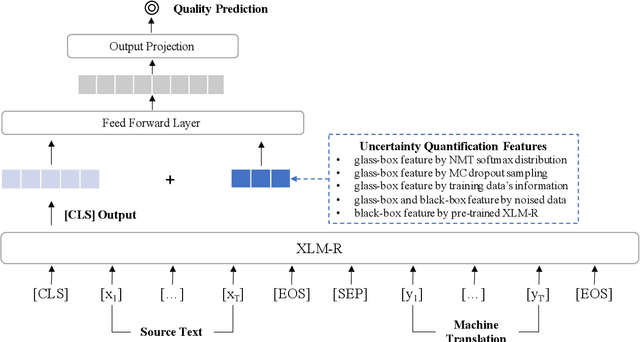

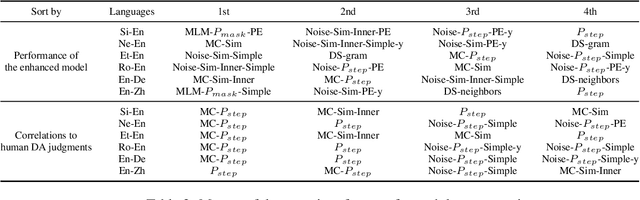

Quality Estimation (QE) plays an essential role in applications of Machine Translation (MT). Traditionally, a QE system accepts the original source text and translation from a black-box MT system as input. Recently, a few studies indicate that as a by-product of translation, QE benefits from the model and training data's information of the MT system where the translations come from, and it is called the "glass-box QE". In this paper, we extend the definition of "glass-box QE" generally to uncertainty quantification with both "black-box" and "glass-box" approaches and design several features deduced from them to blaze a new trial in improving QE's performance. We propose a framework to fuse the feature engineering of uncertainty quantification into a pre-trained cross-lingual language model to predict the translation quality. Experiment results show that our method achieves state-of-the-art performances on the datasets of WMT 2020 QE shared task.
Combining Static Word Embeddings and Contextual Representations for Bilingual Lexicon Induction
Jun 10, 2021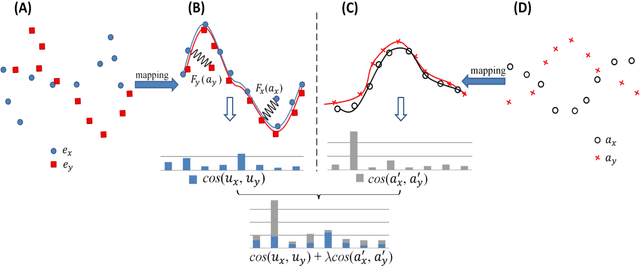
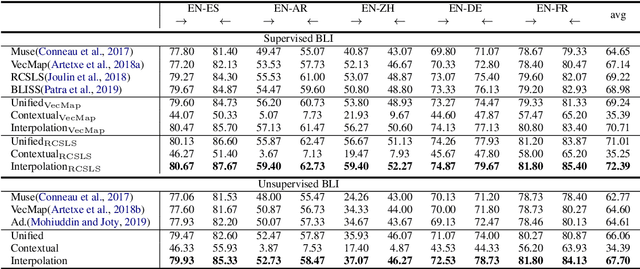
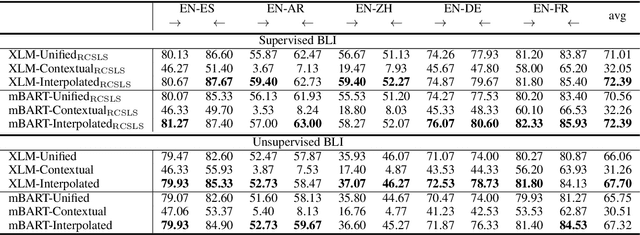

Bilingual Lexicon Induction (BLI) aims to map words in one language to their translations in another, and is typically through learning linear projections to align monolingual word representation spaces. Two classes of word representations have been explored for BLI: static word embeddings and contextual representations, but there is no studies to combine both. In this paper, we propose a simple yet effective mechanism to combine the static word embeddings and the contextual representations to utilize the advantages of both paradigms. We test the combination mechanism on various language pairs under the supervised and unsupervised BLI benchmark settings. Experiments show that our mechanism consistently improves performances over robust BLI baselines on all language pairs by averagely improving 3.2 points in the supervised setting, and 3.1 points in the unsupervised setting.
Bilingual Terminology Extraction from Non-Parallel E-Commerce Corpora
Apr 15, 2021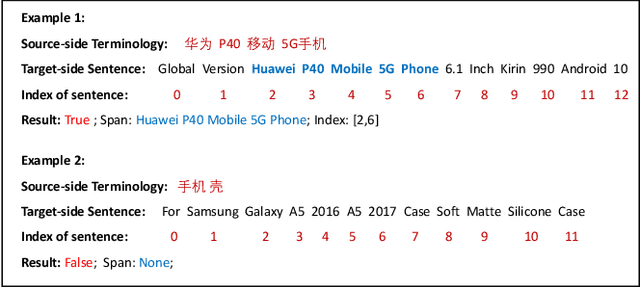
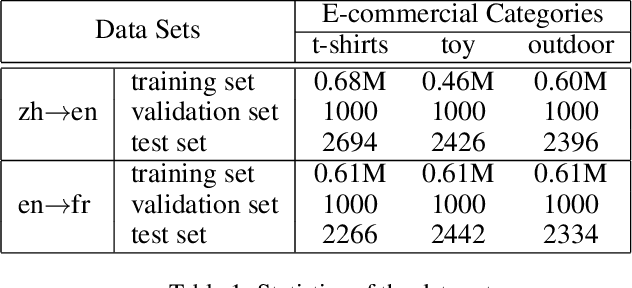
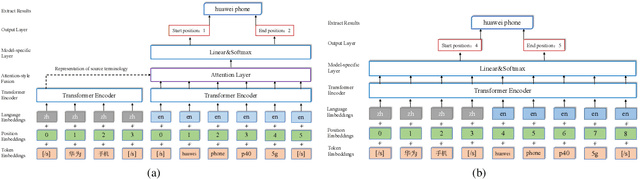
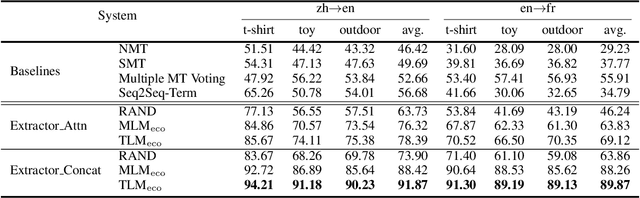
Bilingual terminologies are important resources for natural language processing (NLP) applications. The acquisition of bilingual terminology pairs is either human translation or automatic extraction from parallel data. We notice that comparable corpora could also be a good resource for extracting bilingual terminology pairs, especially for e-commerce domain. The parallel corpora are particularly scarce in e-commerce settings, but the non-parallel corpora in different languages from the same domain are easily available. In this paper, we propose a novel framework of extracting bilingual terminologies from non-parallel comparable corpus in e-commerce. Benefiting from cross-lingual pre-training in e-commerce, our framework can extract the corresponding target terminology by fully utilizing the deep semantic relationship between source-side terminology and target-side sentence. Experimental results on various language pairs show that our approaches achieve significantly better performance than various strong baselines.