 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Information Extraction with Meta-Pretrained Self-Retrieval
Jun 18, 2023



Universal Information Extraction~(Universal IE) aims to solve different extraction tasks in a uniform text-to-structure generation manner. Such a generation procedure tends to struggle when there exist complex information structures to be extracted. Retrieving knowledge from external knowledge bases may help models to overcome this problem but it is impossible to construct a knowledge base suitable for various IE tasks. Inspired by the fact that large amount of knowledge are stored in the pretrained language models~(PLM) and can be retrieved explicitly, in this paper, we propose MetaRetriever to retrieve task-specific knowledge from PLMs to enhance universal IE. As different IE tasks need different knowledge, we further propose a Meta-Pretraining Algorithm which allows MetaRetriever to quicktly achieve maximum task-specific retrieval performance when fine-tuning on downstream IE tasks. Experimental results show that MetaRetriever achieves the new state-of-the-art on 4 IE tasks, 12 datasets under fully-supervised, low-resource and few-shot scenarios.
Path-Enhanced Multi-Relational Question Answering with Knowledge Graph Embeddings
Oct 29, 2021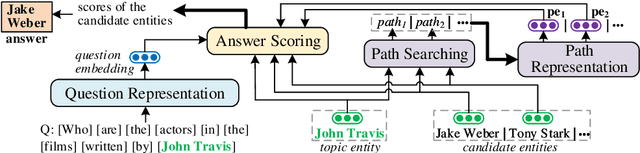
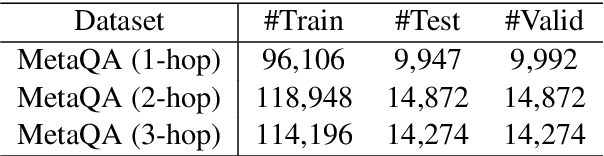

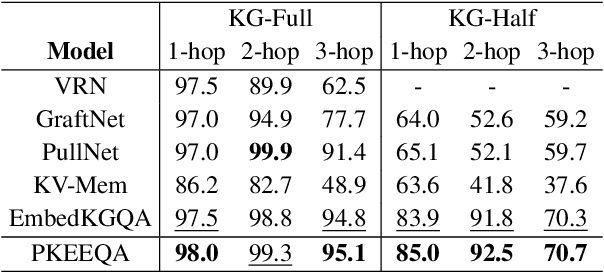
The multi-relational Knowledge Base Question Answering (KBQA) system performs multi-hop reasoning over the knowledge graph (KG) to achieve the answer. Recent approaches attempt to introduce the knowledge graph embedding (KGE) technique to handle the KG incompleteness but only consider the triple facts and neglect the significant semantic correlation between paths and multi-relational questions. In this paper, we propose a Path and Knowledge Embedding-Enhanced multi-relational Question Answering model (PKEEQA), which leverages multi-hop paths between entities in the KG to evaluate the ambipolar correlation between a path embedding and a multi-relational question embedding via a customizable path representation mechanism, benefiting for achieving more accurate answers from the perspective of both the triple facts and the extra paths. Experimental results illustrate that PKEEQA improves KBQA models' performance for multi-relational question answering with explainability to some extent derived from paths.
Bilingual Terminology Extraction from Non-Parallel E-Commerce Corpora
Apr 15, 2021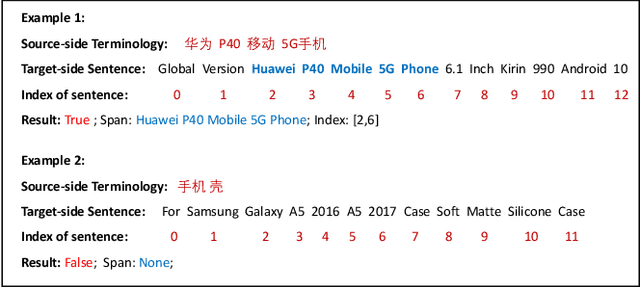
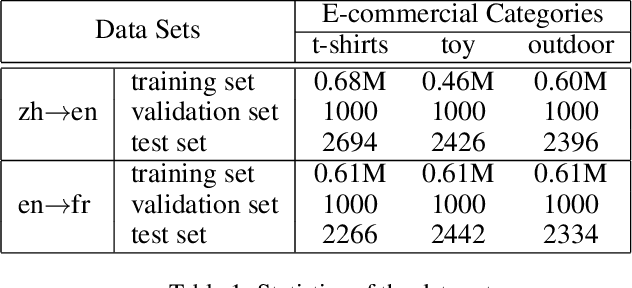
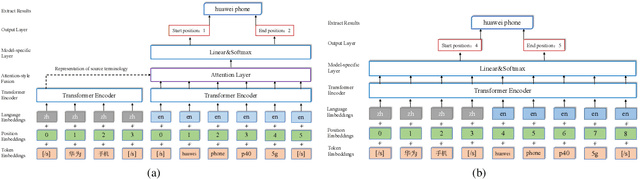
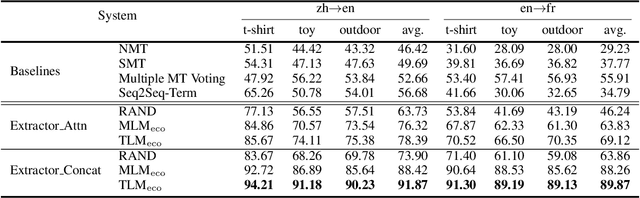
Bilingual terminologies are important resources for natural language processing (NLP) applications. The acquisition of bilingual terminology pairs is either human translation or automatic extraction from parallel data. We notice that comparable corpora could also be a good resource for extracting bilingual terminology pairs, especially for e-commerce domain. The parallel corpora are particularly scarce in e-commerce settings, but the non-parallel corpora in different languages from the same domain are easily available. In this paper, we propose a novel framework of extracting bilingual terminologies from non-parallel comparable corpus in e-commerce. Benefiting from cross-lingual pre-training in e-commerce, our framework can extract the corresponding target terminology by fully utilizing the deep semantic relationship between source-side terminology and target-side sentence. Experimental results on various language pairs show that our approaches achieve significantly better performance than various strong baselines.