 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSALT: When More Rollouts Don't Help in Group-Based Policy Optimization and How to Make Them Matter
Jun 04, 2026Reinforcement learning with verifiable rewards (RLVR) often adopts GRPO-style group-relative updates, sampling multiple rollouts per prompt to construct normalized learning signals. However, merely increasing the number of rollouts does not reliably strengthen learning: under GRPO-style group normalization, per-rollout policy-gradient features can concentrate into a low-rank, signed geometry, causing substantial cancellation during aggregation and weakening the effective update. We address this failure mode with SALT, a Subspace-Adaptive geometry pLug-in componenT that uses sample-wise gradient geometry to reweight the coefficients of group-relative updates. SALT estimates a dominant shared subspace from the mini-batch Gram geometry, decomposes group-relative coefficients into shared and residual channels, and adaptively amplifies the residual channel when signed cancellation is severe. Across diverse reasoning-oriented RLVR benchmarks and model scales, SALT improves effective update geometry and performance without modifying the reward model or the rollout sampling procedure
SPICE: Submodular Penalized Information-Conflict Selection for Efficient Large Language Model Training
Jan 30, 2026Information-based data selection for instruction tuning is compelling: maximizing the log-determinant of the Fisher information yields a monotone submodular objective, enabling greedy algorithms to achieve a $(1-1/e)$ approximation under a cardinality budget. In practice, however, we identify alleviating gradient conflicts, misalignment between per-sample gradients, is a key factor that slows down the decay of marginal log-determinant information gains, thereby preventing significant loss of information. We formalize this via an $\varepsilon$-decomposition that quantifies the deviation from ideal submodularity as a function of conflict statistics, yielding data-dependent approximation factors that tighten as conflicts diminish. Guided by this analysis, we propose SPICE, a conflict-aware selector that maximizes information while penalizing misalignment, and that supports early stopping and proxy models for efficiency. Empirically, SPICE selects subsets with higher log-determinant information than original criteria, and these informational gains translate into performance improvements: across 8 benchmarks with LLaMA2-7B and Qwen2-7B, SPICE uses only 10% of the data, yet matches or exceeds 6 methods including full-data tuning. This achieves performance improvements with substantially lower training cost.
Unifying Visual and Vision-Language Tracking via Contrastive Learning
Jan 20, 2024Single object tracking aims to locate the target object in a video sequence according to the state specified by different modal references, including the initial bounding box (BBOX), natural language (NL), or both (NL+BBOX). Due to the gap between different modalities, most existing trackers are designed for single or partial of these reference settings and overspecialize on the specific modality. Differently, we present a unified tracker called UVLTrack, which can simultaneously handle all three reference settings (BBOX, NL, NL+BBOX) with the same parameters. The proposed UVLTrack enjoys several merits. First, we design a modality-unified feature extractor for joint visual and language feature learning and propose a multi-modal contrastive loss to align the visual and language features into a unified semantic space. Second, a modality-adaptive box head is proposed, which makes full use of the target reference to mine ever-changing scenario features dynamically from video contexts and distinguish the target in a contrastive way, enabling robust performance in different reference settings. Extensive experimental results demonstrate that UVLTrack achieves promising performance on seven visual tracking datasets, three vision-language tracking datasets, and three visual grounding datasets. Codes and models will be open-sourced at https://github.com/OpenSpaceAI/UVLTrack.
On Robust Wasserstein Barycenter: The Model and Algorithm
Dec 25, 2023The Wasserstein barycenter problem is to compute the average of $m$ given probability measures, which has been widely studied in many different areas; however, real-world data sets are often noisy and huge, which impedes its applications in practice. Hence, in this paper, we focus on improving the computational efficiency of two types of robust Wasserstein barycenter problem (RWB): fixed-support RWB (fixed-RWB) and free-support RWB (free-RWB); actually, the former is a subroutine of the latter. Firstly, we improve efficiency through model reducing; we reduce RWB as an augmented Wasserstein barycenter problem, which works for both fixed-RWB and free-RWB. Especially, fixed-RWB can be computed within $\widetilde{O}(\frac{mn^2}{\epsilon_+})$ time by using an off-the-shelf solver, where $\epsilon_+$ is the pre-specified additive error and $n$ is the size of locations of input measures. Then, for free-RWB, we leverage a quality guaranteed data compression technique, coreset, to accelerate computation by reducing the data set size $m$. It shows that running algorithms on the coreset is enough instead of on the original data set. Next, by combining the model reducing and coreset techniques above, we propose an algorithm for free-RWB by updating the weights and locations alternatively. Finally, our experiments demonstrate the efficiency of our techniques.
Disambiguated Lexically Constrained Neural Machine Translation
May 27, 2023Lexically constrained neural machine translation (LCNMT), which controls the translation generation with pre-specified constraints, is important in many practical applications. Current approaches to LCNMT typically assume that the pre-specified lexical constraints are contextually appropriate. This assumption limits their application to real-world scenarios where a source lexicon may have multiple target constraints, and disambiguation is needed to select the most suitable one. In this paper, we propose disambiguated LCNMT (D-LCNMT) to solve the problem. D-LCNMT is a robust and effective two-stage framework that disambiguates the constraints based on contexts at first, then integrates the disambiguated constraints into LCNMT. Experimental results show that our approach outperforms strong baselines including existing data augmentation based approaches on benchmark datasets, and comprehensive experiments in scenarios where a source lexicon corresponds to multiple target constraints demonstrate the constraint disambiguation superiority of our approach.
Third-Party Aligner for Neural Word Alignments
Nov 08, 2022



Word alignment is to find translationally equivalent words between source and target sentences. Previous work has demonstrated that self-training can achieve competitive word alignment results. In this paper, we propose to use word alignments generated by a third-party word aligner to supervise the neural word alignment training. Specifically, source word and target word of each word pair aligned by the third-party aligner are trained to be close neighbors to each other in the contextualized embedding space when fine-tuning a pre-trained cross-lingual language model. Experiments on the benchmarks of various language pairs show that our approach can surprisingly do self-correction over the third-party supervision by finding more accurate word alignments and deleting wrong word alignments, leading to better performance than various third-party word aligners, including the currently best one. When we integrate all supervisions from various third-party aligners, we achieve state-of-the-art word alignment performances, with averagely more than two points lower alignment error rates than the best third-party aligner. We released our code at https://github.com/sdongchuanqi/Third-Party-Supervised-Aligner.
Interactive Multi-scale Fusion of 2D and 3D Features for Multi-object Tracking
Mar 30, 2022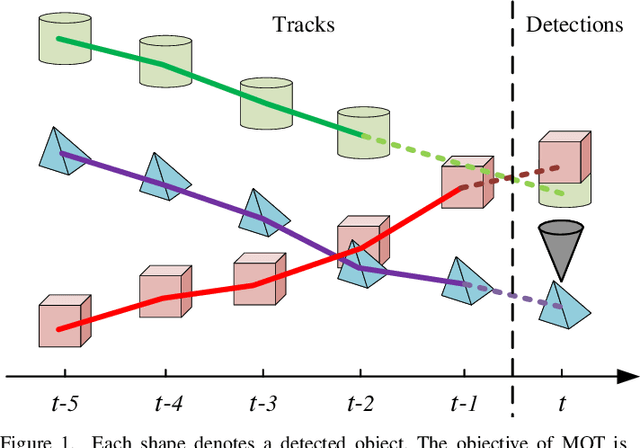
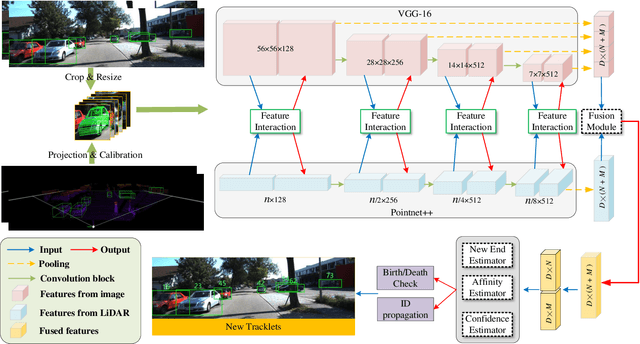
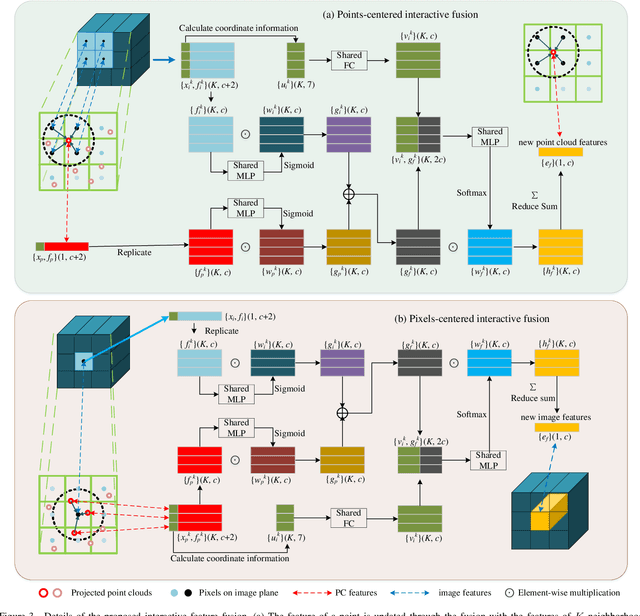

Multiple object tracking (MOT) is a significant task in achieving autonomous driving. Traditional works attempt to complete this task, either based on point clouds (PC) collected by LiDAR, or based on images captured from cameras. However, relying on one single sensor is not robust enough, because it might fail during the tracking process. On the other hand, feature fusion from multiple modalities contributes to the improvement of accuracy. As a result, new techniques based on different sensors integrating features from multiple modalities are being developed. Texture information from RGB cameras and 3D structure information from Lidar have respective advantages under different circumstances. However, it's not easy to achieve effective feature fusion because of completely distinct information modalities. Previous fusion methods usually fuse the top-level features after the backbones extract the features from different modalities. In this paper, we first introduce PointNet++ to obtain multi-scale deep representations of point cloud to make it adaptive to our proposed Interactive Feature Fusion between multi-scale features of images and point clouds. Specifically, through multi-scale interactive query and fusion between pixel-level and point-level features, our method, can obtain more distinguishing features to improve the performance of multiple object tracking. Besides, we explore the effectiveness of pre-training on each single modality and fine-tuning on the fusion-based model. The experimental results demonstrate that our method can achieve good performance on the KITTI benchmark and outperform other approaches without using multi-scale feature fusion. Moreover, the ablation studies indicates the effectiveness of multi-scale feature fusion and pre-training on single modality.
Combining Static Word Embeddings and Contextual Representations for Bilingual Lexicon Induction
Jun 10, 2021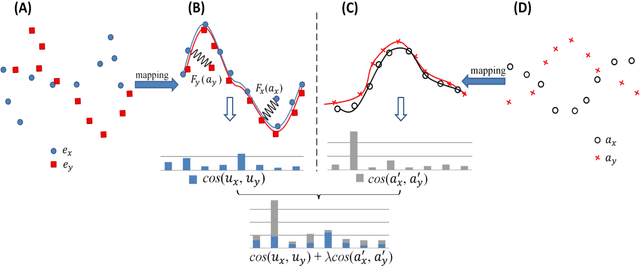
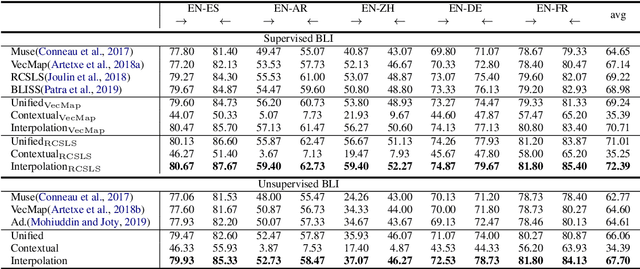
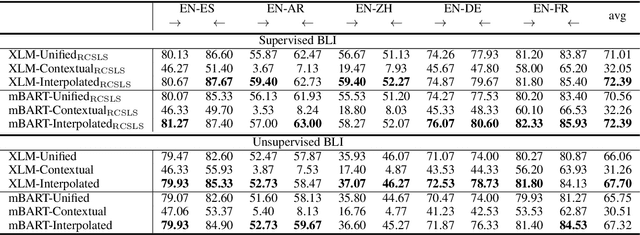

Bilingual Lexicon Induction (BLI) aims to map words in one language to their translations in another, and is typically through learning linear projections to align monolingual word representation spaces. Two classes of word representations have been explored for BLI: static word embeddings and contextual representations, but there is no studies to combine both. In this paper, we propose a simple yet effective mechanism to combine the static word embeddings and the contextual representations to utilize the advantages of both paradigms. We test the combination mechanism on various language pairs under the supervised and unsupervised BLI benchmark settings. Experiments show that our mechanism consistently improves performances over robust BLI baselines on all language pairs by averagely improving 3.2 points in the supervised setting, and 3.1 points in the unsupervised setting.