 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagineUAV: Aerial Vision-Language Navigation via World-Action Modeling and Kinodynamic Planning
May 31, 2026Vision-language navigation (VLN) for UAVs demands grounding free-form instructions into 6-DoF flight under partial observability. While Vision-Language-Action (VLA) models excel at semantic reasoning, they suffer from brittleness due to geometric inconsistency and dynamics mismatch. To address this, we propose ImagineUAV, an imagination-driven framework leveraging cascaded world-action modeling. Instead of direct regression, ImagineUAV employs a latent video diffusion model to generate instruction-conditioned future observations, explicitly imagining environmental evolution, from which 6-DoF motions are inferred via an action extractor. A kinodynamic planner then refines these estimates into collision-free trajectories. Additionally, a step-distilled inference pipeline ensures real-time execution. With only 1.3B parameters, ImagineUAV outperforms prior VLN and VLA baselines on benchmarks and real-world flights, validating the practicality of imagination-driven aerial navigation.
Revisiting DAgger in the Era of LLM-Agents
May 13, 2026Long-horizon LM agents learn from multi-turn interaction, where a single early mistake can alter the subsequent state distribution and derail the whole trajectory. Existing recipes fall short in complementary ways: supervised fine-tuning provides dense teacher supervision but suffers from covariate shift because it is trained on off-policy teacher trajectories; while reinforcement learning with verifiable rewards avoids this off-policy mismatch by learning from on-policy rollouts but with only sparse outcome feedback. We address this dilemma by revisiting Dataset Aggregation (DAgger) for multi-turn LM agents: the algorithm collects trajectories through a turn-level interpolation of student and teacher policies, and the student is then trained on these trajectories using supervised labels provided by the teacher. By directly interacting with environments, we expose the model to realistic states likely to be encountered during deployment, thereby effectively mitigating covariate shift. Besides, since the student is learned by mimicking the teacher's behavior, it receives rich feedback during learning. To demonstrate DAgger enjoys the benefits of both worlds, we tested the algorithm to train a software-engineering agent with 4B- and 8B-scale student models. On SWE-bench Verified, our DAgger-style training improves over the strongest post-training baseline by +3.9 points at 4B and +3.6 points at 8B. The resulting 4B agent reaches 27.3%, outperforming representative published 8B SWE-agent systems, while the 8B agent achieves 29.8%, surpassing SWE-Gym-32B and coming within 5 points of stronger 32B-scale agents. Together with consistent gains on the held-out SWE-Gym split, these results suggest the effectiveness of DAgger for modern long-horizon LM agents.
Empowering VLMs for Few-Shot Multimodal Time Series Classification via Tailored Agentic Reasoning
May 10, 2026In this paper, we propose the first VL$\underline{\textbf{M}}$ $\underline{\textbf{a}}$gentic $\underline{\textbf{r}}$easoning framework for few-$\underline{\textbf{s}}$hot multimodal $\underline{\textbf{T}}$ime $\underline{\textbf{S}}$eries $\underline{\textbf{C}}$lassification ($\textbf{MarsTSC}$), which introduces a self-evolving knowledge bank as a dynamic context iteratively refined via reflective agentic reasoning. The framework comprises three collaborative roles: i) Generator conducts reliable classification via reasoning; ii) Reflector diagnoses the root causes of reasoning errors to yield discriminative insights targeting the temporal features overlooked by Generator; iii) Modifier applies verified updates to the knowledge bank to prevent context collapse. We further introduce a test-time update strategy to enable cautious, continuous knowledge bank refinement to mitigate few-shot bias and distribution shift. Extensive experiments across 12 mainstream time series benchmarks demonstrate that $\textbf{MarsTSC}$ delivers substantial and consistent performance gains across 6 VLM backbones, outperforming both classical and foundation model-based time series baselines under few-shot conditions, while producing interpretable rationales that ground each classification decision in human-readable feature evidence.
WaveMoE: A Wavelet-Enhanced Mixture-of-Experts Foundation Model for Time Series Forecasting
Apr 12, 2026Time series foundation models (TSFMs) have recently achieved remarkable success in universal forecasting by leveraging large-scale pretraining on diverse time series data. Complementing this progress, incorporating frequency-domain information yields promising performance in enhancing the modeling of complex temporal patterns, such as periodicity and localized high-frequency dynamics, which are prevalent in real-world time series. To advance this direction, we propose a new perspective that integrates explicit frequency-domain representations into scalable foundation models, and introduce WaveMoE, a wavelet-enhanced mixture-of-experts foundation model for time series forecasting. WaveMoE adopts a dual-path architecture that jointly processes time series tokens and wavelet tokens aligned along a unified temporal axis, and coordinates them through a shared expert routing mechanism that enables consistent expert specialization while efficiently scaling model capacity. Preliminary experimental results on 16 diverse benchmark datasets indicate that WaveMoE has the potential to further improve forecasting performance by incorporating wavelet-domain corpora.
SDP: A Unified Protocol and Benchmarking Framework for Reproducible Wireless Sensing
Jan 13, 2026Learning-based wireless sensing has made rapid progress, yet the field still lacks a unified and reproducible experimental foundation. Unlike computer vision, wireless sensing relies on hardware-dependent channel measurements whose representations, preprocessing pipelines, and evaluation protocols vary significantly across devices and datasets, hindering fair comparison and reproducibility. This paper proposes the Sensing Data Protocol (SDP), a protocol-level abstraction and unified benchmark for scalable wireless sensing. SDP acts as a standardization layer that decouples learning tasks from hardware heterogeneity. To this end, SDP enforces deterministic physical-layer sanitization, canonical tensor construction, and standardized training and evaluation procedures, decoupling learning performance from hardware-specific artifacts. Rather than introducing task-specific models, SDP establishes a principled protocol foundation for fair evaluation across diverse sensing tasks and platforms. Extensive experiments demonstrate that SDP achieves competitive accuracy while substantially improving stability, reducing inter-seed performance variance by orders of magnitude on complex activity recognition tasks. A real-world experiment using commercial off-the-shelf Wi-Fi hardware further illustrating the protocol's interoperability across heterogeneous hardware. By providing a unified protocol and benchmark, SDP enables reproducible and comparable wireless sensing research and supports the transition from ad hoc experimentation toward reliable engineering practice.
A Sensing Dataset Protocol for Benchmarking and Multi-Task Wireless Sensing
Dec 13, 2025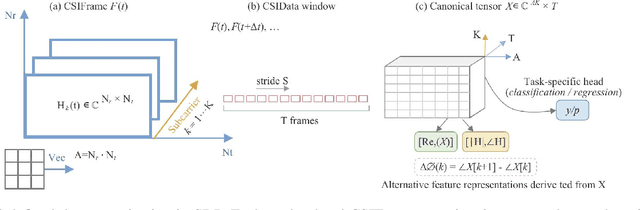
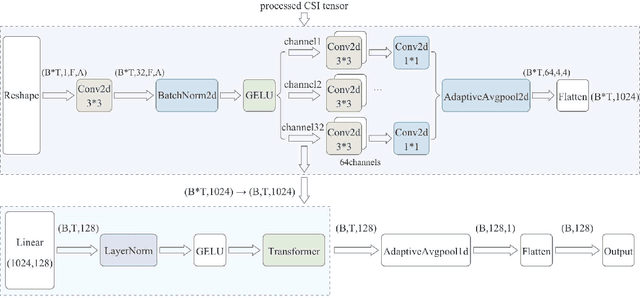
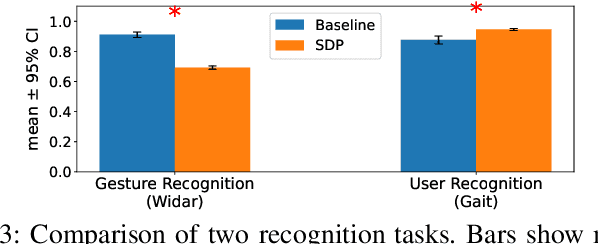
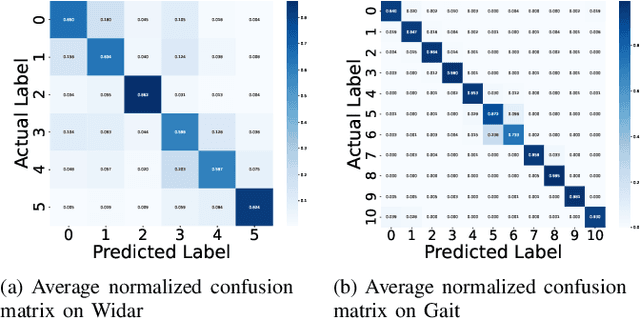
Wireless sensing has become a fundamental enabler for intelligent environments, supporting applications such as human detection, activity recognition, localization, and vital sign monitoring. Despite rapid advances, existing datasets and pipelines remain fragmented across sensing modalities, hindering fair comparison, transfer, and reproducibility. We propose the Sensing Dataset Protocol (SDP), a protocol-level specification and benchmark framework for large-scale wireless sensing. SDP defines how heterogeneous wireless signals are mapped into a unified perception data-block schema through lightweight synchronization, frequency-time alignment, and resampling, while a Canonical Polyadic-Alternating Least Squares (CP-ALS) pooling stage provides a task-agnostic representation that preserves multipath, spectral, and temporal structures. Built upon this protocol, a unified benchmark is established for detection, recognition, and vital-sign estimation with consistent preprocessing, training, and evaluation. Experiments under the cross-user split demonstrate that SDP significantly reduces variance (approximately 88%) across seeds while maintaining competitive accuracy and latency, confirming its value as a reproducible foundation for multi-modal and multitask sensing research.
Transformer IMU Calibrator: Dynamic On-body IMU Calibration for Inertial Motion Capture
Jun 12, 2025In this paper, we propose a novel dynamic calibration method for sparse inertial motion capture systems, which is the first to break the restrictive absolute static assumption in IMU calibration, i.e., the coordinate drift RG'G and measurement offset RBS remain constant during the entire motion, thereby significantly expanding their application scenarios. Specifically, we achieve real-time estimation of RG'G and RBS under two relaxed assumptions: i) the matrices change negligibly in a short time window; ii) the human movements/IMU readings are diverse in such a time window. Intuitively, the first assumption reduces the number of candidate matrices, and the second assumption provides diverse constraints, which greatly reduces the solution space and allows for accurate estimation of RG'G and RBS from a short history of IMU readings in real time. To achieve this, we created synthetic datasets of paired RG'G, RBS matrices and IMU readings, and learned their mappings using a Transformer-based model. We also designed a calibration trigger based on the diversity of IMU readings to ensure that assumption ii) is met before applying our method. To our knowledge, we are the first to achieve implicit IMU calibration (i.e., seamlessly putting IMUs into use without the need for an explicit calibration process), as well as the first to enable long-term and accurate motion capture using sparse IMUs. The code and dataset are available at https://github.com/ZuoCX1996/TIC.
T2A-Feedback: Improving Basic Capabilities of Text-to-Audio Generation via Fine-grained AI Feedback
May 15, 2025

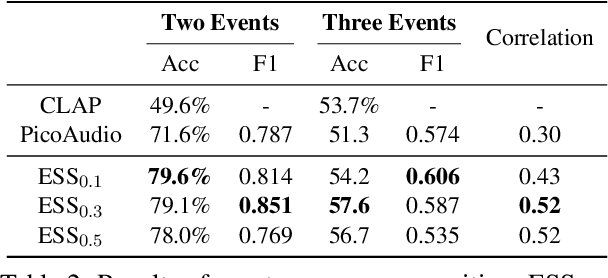

Text-to-audio (T2A) generation has achieved remarkable progress in generating a variety of audio outputs from language prompts. However, current state-of-the-art T2A models still struggle to satisfy human preferences for prompt-following and acoustic quality when generating complex multi-event audio. To improve the performance of the model in these high-level applications, we propose to enhance the basic capabilities of the model with AI feedback learning. First, we introduce fine-grained AI audio scoring pipelines to: 1) verify whether each event in the text prompt is present in the audio (Event Occurrence Score), 2) detect deviations in event sequences from the language description (Event Sequence Score), and 3) assess the overall acoustic and harmonic quality of the generated audio (Acoustic&Harmonic Quality). We evaluate these three automatic scoring pipelines and find that they correlate significantly better with human preferences than other evaluation metrics. This highlights their value as both feedback signals and evaluation metrics. Utilizing our robust scoring pipelines, we construct a large audio preference dataset, T2A-FeedBack, which contains 41k prompts and 249k audios, each accompanied by detailed scores. Moreover, we introduce T2A-EpicBench, a benchmark that focuses on long captions, multi-events, and story-telling scenarios, aiming to evaluate the advanced capabilities of T2A models. Finally, we demonstrate how T2A-FeedBack can enhance current state-of-the-art audio model. With simple preference tuning, the audio generation model exhibits significant improvements in both simple (AudioCaps test set) and complex (T2A-EpicBench) scenarios.
Steering No-Regret Agents in MFGs under Model Uncertainty
Mar 12, 2025Incentive design is a popular framework for guiding agents' learning dynamics towards desired outcomes by providing additional payments beyond intrinsic rewards. However, most existing works focus on a finite, small set of agents or assume complete knowledge of the game, limiting their applicability to real-world scenarios involving large populations and model uncertainty. To address this gap, we study the design of steering rewards in Mean-Field Games (MFGs) with density-independent transitions, where both the transition dynamics and intrinsic reward functions are unknown. This setting presents non-trivial challenges, as the mediator must incentivize the agents to explore for its model learning under uncertainty, while simultaneously steer them to converge to desired behaviors without incurring excessive incentive payments. Assuming agents exhibit no(-adaptive) regret behaviors, we contribute novel optimistic exploration algorithms. Theoretically, we establish sub-linear regret guarantees for the cumulative gaps between the agents' behaviors and the desired ones. In terms of the steering cost, we demonstrate that our total incentive payments incur only sub-linear excess, competing with a baseline steering strategy that stabilizes the target policy as an equilibrium. Our work presents an effective framework for steering agents behaviors in large-population systems under uncertainty.
Can RLHF be More Efficient with Imperfect Reward Models? A Policy Coverage Perspective
Feb 26, 2025Sample efficiency is critical for online Reinforcement Learning from Human Feedback (RLHF). While existing works investigate sample-efficient online exploration strategies, the potential of utilizing misspecified yet relevant reward models to accelerate learning remains underexplored. This paper studies how to transfer knowledge from those imperfect reward models in online RLHF. We start by identifying a novel property of the KL-regularized RLHF objective: \emph{a policy's ability to cover the optimal policy is captured by its sub-optimality}. Building on this insight, we propose a theoretical transfer learning algorithm with provable benefits compared to standard online learning. Our approach achieves low regret in the early stage by quickly adapting to the best available source reward models without prior knowledge of their quality, and over time, it attains an $\tilde{O}(\sqrt{T})$ regret bound \emph{independent} of structural complexity measures. Inspired by our theoretical findings, we develop an empirical algorithm with improved computational efficiency, and demonstrate its effectiveness empirically in summarization tasks.