 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Neural Incentive Design with Parameterized Mean-Field Approximation
Oct 24, 2025
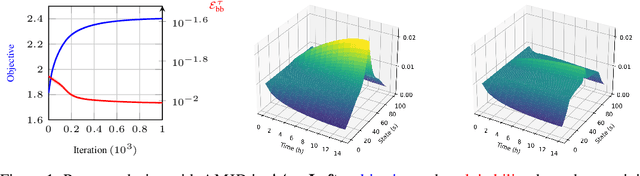
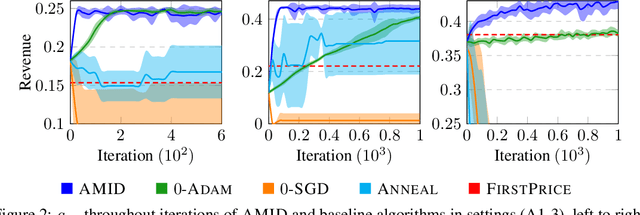

Designing incentives for a multi-agent system to induce a desirable Nash equilibrium is both a crucial and challenging problem appearing in many decision-making domains, especially for a large number of agents $N$. Under the exchangeability assumption, we formalize this incentive design (ID) problem as a parameterized mean-field game (PMFG), aiming to reduce complexity via an infinite-population limit. We first show that when dynamics and rewards are Lipschitz, the finite-$N$ ID objective is approximated by the PMFG at rate $\mathscr{O}(\frac{1}{\sqrt{N}})$. Moreover, beyond the Lipschitz-continuous setting, we prove the same $\mathscr{O}(\frac{1}{\sqrt{N}})$ decay for the important special case of sequential auctions, despite discontinuities in dynamics, through a tailored auction-specific analysis. Built on our novel approximation results, we further introduce our Adjoint Mean-Field Incentive Design (AMID) algorithm, which uses explicit differentiation of iterated equilibrium operators to compute gradients efficiently. By uniting approximation bounds with optimization guarantees, AMID delivers a powerful, scalable algorithmic tool for many-agent (large $N$) ID. Across diverse auction settings, the proposed AMID method substantially increases revenue over first-price formats and outperforms existing benchmark methods.
Provable Maximum Entropy Manifold Exploration via Diffusion Models
Jun 18, 2025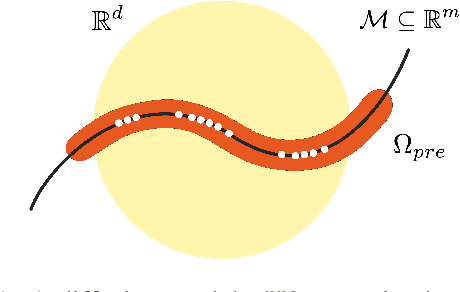

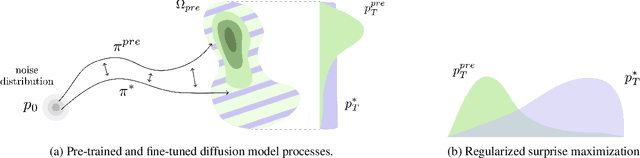

Exploration is critical for solving real-world decision-making problems such as scientific discovery, where the objective is to generate truly novel designs rather than mimic existing data distributions. In this work, we address the challenge of leveraging the representational power of generative models for exploration without relying on explicit uncertainty quantification. We introduce a novel framework that casts exploration as entropy maximization over the approximate data manifold implicitly defined by a pre-trained diffusion model. Then, we present a novel principle for exploration based on density estimation, a problem well-known to be challenging in practice. To overcome this issue and render this method truly scalable, we leverage a fundamental connection between the entropy of the density induced by a diffusion model and its score function. Building on this, we develop an algorithm based on mirror descent that solves the exploration problem as sequential fine-tuning of a pre-trained diffusion model. We prove its convergence to the optimal exploratory diffusion model under realistic assumptions by leveraging recent understanding of mirror flows. Finally, we empirically evaluate our approach on both synthetic and high-dimensional text-to-image diffusion, demonstrating promising results.
Poincaré Inequality for Local Log-Polyak-Lojasiewicz Measures : Non-asymptotic Analysis in Low-temperature Regime
Feb 12, 2025Potential functions in highly pertinent applications, such as deep learning in over-parameterized regime, are empirically observed to admit non-isolated minima. To understand the convergence behavior of stochastic dynamics in such landscapes, we propose to study the class of \logPLmeasure\ measures $\mu_\epsilon \propto \exp(-V/\epsilon)$, where the potential $V$ satisfies a local Polyak-{\L}ojasiewicz (P\L) inequality, and its set of local minima is provably \emph{connected}. Notably, potentials in this class can exhibit local maxima and we characterize its optimal set S to be a compact $\mathcal{C}^2$ \emph{embedding submanifold} of $\mathbb{R}^d$ without boundary. The \emph{non-contractibility} of S distinguishes our function class from the classical convex setting topologically. Moreover, the embedding structure induces a naturally defined Laplacian-Beltrami operator on S, and we show that its first non-trivial eigenvalue provides an \emph{$\epsilon$-independent} lower bound for the \Poincare\ constant in the \Poincare\ inequality of $\mu_\epsilon$. As a direct consequence, Langevin dynamics with such non-convex potential $V$ and diffusion coefficient $\epsilon$ converges to its equilibrium $\mu_\epsilon$ at a rate of $\tilde{\mathcal{O}}(1/\epsilon)$, provided $\epsilon$ is sufficiently small. Here $\tilde{\mathcal{O}}$ hides logarithmic terms.
Learning to Steer Markovian Agents under Model Uncertainty
Jul 14, 2024Designing incentives for an adapting population is a ubiquitous problem in a wide array of economic applications and beyond. In this work, we study how to design additional rewards to steer multi-agent systems towards desired policies \emph{without} prior knowledge of the agents' underlying learning dynamics. We introduce a model-based non-episodic Reinforcement Learning (RL) formulation for our steering problem. Importantly, we focus on learning a \emph{history-dependent} steering strategy to handle the inherent model uncertainty about the agents' learning dynamics. We introduce a novel objective function to encode the desiderata of achieving a good steering outcome with reasonable cost. Theoretically, we identify conditions for the existence of steering strategies to guide agents to the desired policies. Complementing our theoretical contributions, we provide empirical algorithms to approximately solve our objective, which effectively tackles the challenge in learning history-dependent strategies. We demonstrate the efficacy of our algorithms through empirical evaluations.
A Hessian-Aware Stochastic Differential Equation for Modelling SGD
May 28, 2024Continuous-time approximation of Stochastic Gradient Descent (SGD) is a crucial tool to study its escaping behaviors from stationary points. However, existing stochastic differential equation (SDE) models fail to fully capture these behaviors, even for simple quadratic objectives. Built on a novel stochastic backward error analysis framework, we derive the Hessian-Aware Stochastic Modified Equation (HA-SME), an SDE that incorporates Hessian information of the objective function into both its drift and diffusion terms. Our analysis shows that HA-SME matches the order-best approximation error guarantee among existing SDE models in the literature, while achieving a significantly reduced dependence on the smoothness parameter of the objective. Further, for quadratic objectives, under mild conditions, HA-SME is proved to be the first SDE model that recovers exactly the SGD dynamics in the distributional sense. Consequently, when the local landscape near a stationary point can be approximated by quadratics, HA-SME is expected to accurately predict the local escaping behaviors of SGD.
Share Your Representation Only: Guaranteed Improvement of the Privacy-Utility Tradeoff in Federated Learning
Sep 11, 2023



Repeated parameter sharing in federated learning causes significant information leakage about private data, thus defeating its main purpose: data privacy. Mitigating the risk of this information leakage, using state of the art differentially private algorithms, also does not come for free. Randomized mechanisms can prevent convergence of models on learning even the useful representation functions, especially if there is more disagreement between local models on the classification functions (due to data heterogeneity). In this paper, we consider a representation federated learning objective that encourages various parties to collaboratively refine the consensus part of the model, with differential privacy guarantees, while separately allowing sufficient freedom for local personalization (without releasing it). We prove that in the linear representation setting, while the objective is non-convex, our proposed new algorithm \DPFEDREP\ converges to a ball centered around the \emph{global optimal} solution at a linear rate, and the radius of the ball is proportional to the reciprocal of the privacy budget. With this novel utility analysis, we improve the SOTA utility-privacy trade-off for this problem by a factor of $\sqrt{d}$, where $d$ is the input dimension. We empirically evaluate our method with the image classification task on CIFAR10, CIFAR100, and EMNIST, and observe a significant performance improvement over the prior work under the same small privacy budget. The code can be found in this link: https://github.com/shenzebang/CENTAUR-Privacy-Federated-Representation-Learning.
Accelerated Doubly Stochastic Gradient Algorithm for Large-scale Empirical Risk Minimization
Apr 23, 2023Nowadays, algorithms with fast convergence, small memory footprints, and low per-iteration complexity are particularly favorable for artificial intelligence applications. In this paper, we propose a doubly stochastic algorithm with a novel accelerating multi-momentum technique to solve large scale empirical risk minimization problem for learning tasks. While enjoying a provably superior convergence rate, in each iteration, such algorithm only accesses a mini batch of samples and meanwhile updates a small block of variable coordinates, which substantially reduces the amount of memory reference when both the massive sample size and ultra-high dimensionality are involved. Empirical studies on huge scale datasets are conducted to illustrate the efficiency of our method in practice.
Straggler-Resilient Personalized Federated Learning
Jun 05, 2022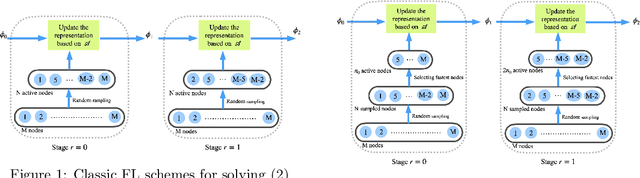
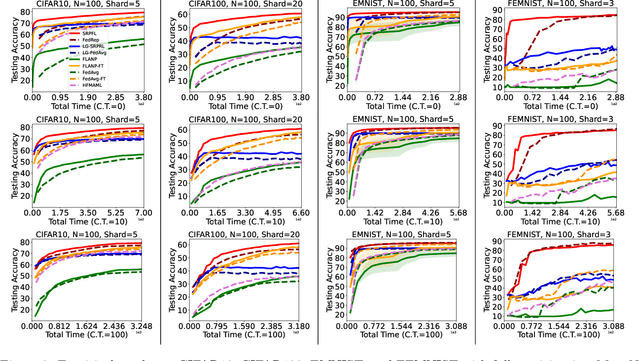
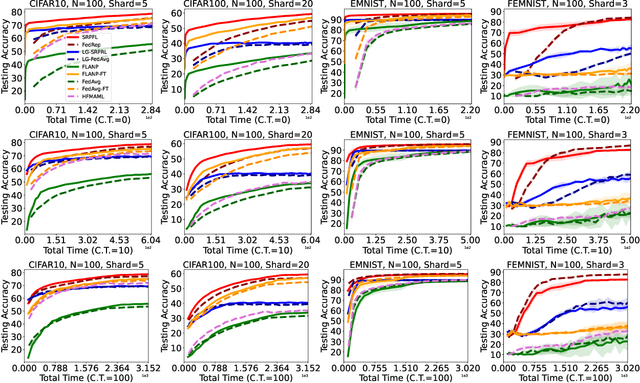
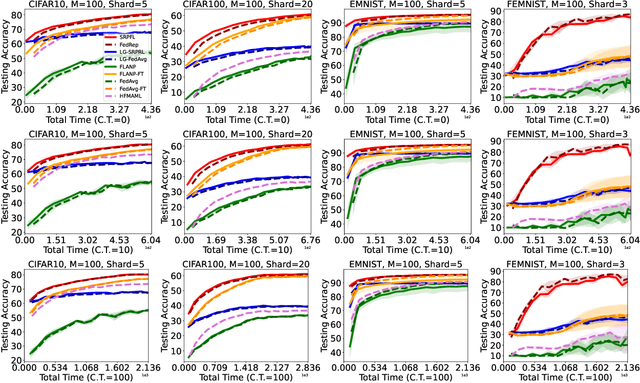
Federated Learning is an emerging learning paradigm that allows training models from samples distributed across a large network of clients while respecting privacy and communication restrictions. Despite its success, federated learning faces several challenges related to its decentralized nature. In this work, we develop a novel algorithmic procedure with theoretical speedup guarantees that simultaneously handles two of these hurdles, namely (i) data heterogeneity, i.e., data distributions can vary substantially across clients, and (ii) system heterogeneity, i.e., the computational power of the clients could differ significantly. Our method relies on ideas from representation learning theory to find a global common representation using all clients' data and learn a user-specific set of parameters leading to a personalized solution for each client. Furthermore, our method mitigates the effects of stragglers by adaptively selecting clients based on their computational characteristics and statistical significance, thus achieving, for the first time, near optimal sample complexity and provable logarithmic speedup. Experimental results support our theoretical findings showing the superiority of our method over alternative personalized federated schemes in system and data heterogeneous environments.
Self-Consistency of the Fokker-Planck Equation
Jun 02, 2022

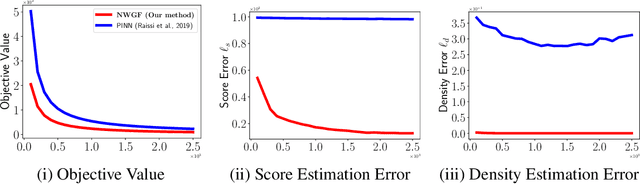
The Fokker-Planck equation (FPE) is the partial differential equation that governs the density evolution of the It\^o process and is of great importance to the literature of statistical physics and machine learning. The FPE can be regarded as a continuity equation where the change of the density is completely determined by a time varying velocity field. Importantly, this velocity field also depends on the current density function. As a result, the ground-truth velocity field can be shown to be the solution of a fixed-point equation, a property that we call self-consistency. In this paper, we exploit this concept to design a potential function of the hypothesis velocity fields, and prove that, if such a function diminishes to zero during the training procedure, the trajectory of the densities generated by the hypothesis velocity fields converges to the solution of the FPE in the Wasserstein-2 sense. The proposed potential function is amenable to neural-network based parameterization as the stochastic gradient with respect to the parameter can be efficiently computed. Once a parameterized model, such as Neural Ordinary Differential Equation is trained, we can generate the entire trajectory to the FPE.
A Federated Learning Framework for Nonconvex-PL Minimax Problems
May 29, 2021
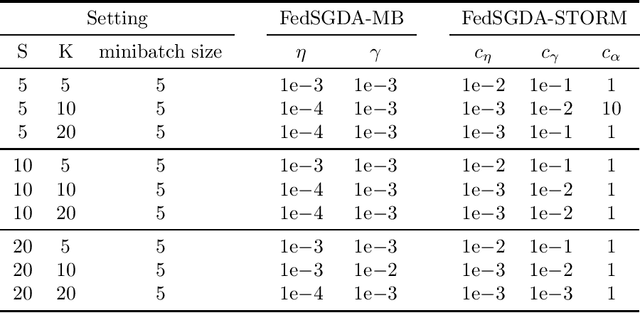
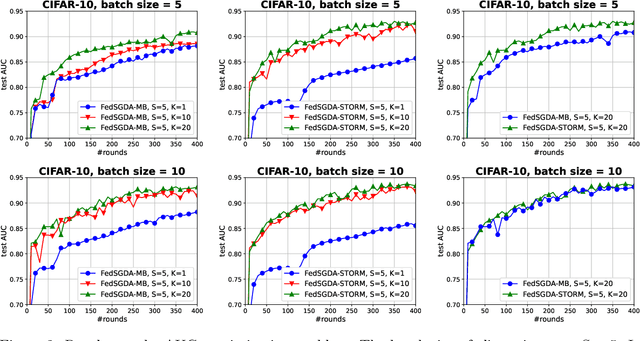
We consider a general class of nonconvex-PL minimax problems in the cross-device federated learning setting. Although nonconvex-PL minimax problems have received a lot of interest in recent years, existing algorithms do not apply to the cross-device federated learning setting which is substantially different from conventional distributed settings and poses new challenges. To bridge this gap, we propose an algorithmic framework named FedSGDA. FedSGDA performs multiple local update steps on a subset of active clients in each round and leverages global gradient estimates to correct the bias in local update directions. By incorporating FedSGDA with two representative global gradient estimators, we obtain two specific algorithms. We establish convergence rates of the proposed algorithms by using novel potential functions. Experimental results on synthetic and real data corroborate our theory and demonstrate the effectiveness of our algorithms.