 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupport Before Frequency in Discrete Diffusion
May 13, 2026Discrete diffusion models are increasingly competitive for language modeling, yet it remains unclear how their denoising objectives organize learning. Although these objectives target the full data distribution, we show that the exact reverse process induces a hierarchy between coarse support information and finer frequency information. For uniform and absorbing (a.k.a. masking) diffusion, we prove that, in the small-noise regime of the final denoising steps, each single-token reverse edit decomposes into a leading scale, determined by whether it moves toward the data support (e.g., grammatically valid sentences), and a finer coefficient, determining relative probabilities within the same scale. Thus, recovering validity structure only requires learning the correct order of magnitude of reverse probabilities, whereas recovering data frequencies requires coefficient-level estimation. The separation is mechanism-dependent: uniform diffusion exhibits a trichotomy into validity-improving, validity-preserving, and validity-worsening edits, while absorbing diffusion places its leading-order mass on validity-improving moves. Experiments on a masked language diffusion model and synthetic regular-language tasks support these predictions: support-localization emerges earlier than within-support frequency ranking, and the contrast between uniform and absorbing diffusion matches the predicted rate separation. Together, our results suggest that discrete diffusion models learn data support before data frequencies.
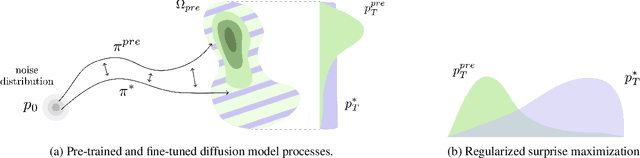
Manifold Generalization Provably Proceeds Memorization in Diffusion Models
Mar 24, 2026Diffusion models often generate novel samples even when the learned score is only \emph{coarse} -- a phenomenon not accounted for by the standard view of diffusion training as density estimation. In this paper, we show that, under the \emph{manifold hypothesis}, this behavior can instead be explained by coarse scores capturing the \emph{geometry} of the data while discarding the fine-scale distributional structure of the population measure~$μ_{\scriptscriptstyle\mathrm{data}}$. Concretely, whereas estimating the full data distribution $μ_{\scriptscriptstyle\mathrm{data}}$ supported on a $k$-dimensional manifold is known to require the classical minimax rate $\tilde{\mathcal{O}}(N^{-1/k})$, we prove that diffusion models trained with coarse scores can exploit the \emph{regularity of the manifold support} and attain a near-parametric rate toward a \emph{different} target distribution. This target distribution has density uniformly comparable to that of~$μ_{\scriptscriptstyle\mathrm{data}}$ throughout any $\tilde{\mathcal{O}}\bigl(N^{-β/(4k)}\bigr)$-neighborhood of the manifold, where $β$ denotes the manifold regularity. Our guarantees therefore depend only on the smoothness of the underlying support, and are especially favorable when the data density itself is irregular, for instance non-differentiable. In particular, when the manifold is sufficiently smooth, we obtain that \emph{generalization} -- formalized as the ability to generate novel, high-fidelity samples -- occurs at a statistical rate strictly faster than that required to estimate the full population distribution~$μ_{\scriptscriptstyle\mathrm{data}}$.
Verifier-Constrained Flow Expansion for Discovery Beyond the Data
Feb 17, 2026Flow and diffusion models are typically pre-trained on limited available data (e.g., molecular samples), covering only a fraction of the valid design space (e.g., the full molecular space). As a consequence, they tend to generate samples from only a narrow portion of the feasible domain. This is a fundamental limitation for scientific discovery applications, where one typically aims to sample valid designs beyond the available data distribution. To this end, we address the challenge of leveraging access to a verifier (e.g., an atomic bonds checker), to adapt a pre-trained flow model so that its induced density expands beyond regions of high data availability, while preserving samples validity. We introduce formal notions of strong and weak verifiers and propose algorithmic frameworks for global and local flow expansion via probability-space optimization. Then, we present Flow Expander (FE), a scalable mirror descent scheme that provably tackles both problems by verifier-constrained entropy maximization over the flow process noised state space. Next, we provide a thorough theoretical analysis of the proposed method, and state convergence guarantees under both idealized and general assumptions. Ultimately, we empirically evaluate our method on both illustrative, yet visually interpretable settings, and on a molecular design task showcasing the ability of FE to expand a pre-trained flow model increasing conformer diversity while preserving validity.
A Unified Density Operator View of Flow Control and Merging
Feb 08, 2026Recent progress in large-scale flow and diffusion models raised two fundamental algorithmic challenges: (i) control-based reward adaptation of pre-trained flows, and (ii) integration of multiple models, i.e., flow merging. While current approaches address them separately, we introduce a unifying probability-space framework that subsumes both as limit cases, and enables reward-guided flow merging, allowing principled, task-aware combination of multiple pre-trained flows (e.g., merging priors while maximizing drug-discovery utilities). Our formulation renders possible to express a rich family of operators over generative models densities, including intersection (e.g., to enforce safety), union (e.g., to compose diverse models), interpolation (e.g., for discovery), their reward-guided counterparts, as well as complex logical expressions via generative circuits. Next, we introduce Reward-Guided Flow Merging (RFM), a mirror-descent scheme that reduces reward-guided flow merging to a sequence of standard fine-tuning problems. Then, we provide first-of-their-kind theoretical guarantees for reward-guided and pure flow merging via RFM. Ultimately, we showcase the capabilities of the proposed method on illustrative settings providing visually interpretable insights, and apply our method to high-dimensional de-novo molecular design and low-energy conformer generation.
Provable Maximum Entropy Manifold Exploration via Diffusion Models
Jun 18, 2025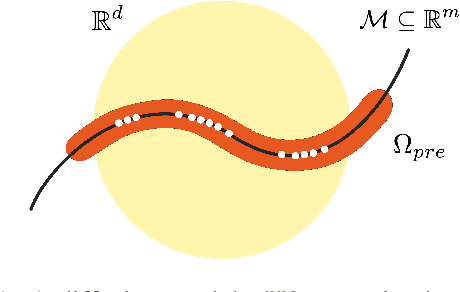


Exploration is critical for solving real-world decision-making problems such as scientific discovery, where the objective is to generate truly novel designs rather than mimic existing data distributions. In this work, we address the challenge of leveraging the representational power of generative models for exploration without relying on explicit uncertainty quantification. We introduce a novel framework that casts exploration as entropy maximization over the approximate data manifold implicitly defined by a pre-trained diffusion model. Then, we present a novel principle for exploration based on density estimation, a problem well-known to be challenging in practice. To overcome this issue and render this method truly scalable, we leverage a fundamental connection between the entropy of the density induced by a diffusion model and its score function. Building on this, we develop an algorithm based on mirror descent that solves the exploration problem as sequential fine-tuning of a pre-trained diffusion model. We prove its convergence to the optimal exploratory diffusion model under realistic assumptions by leveraging recent understanding of mirror flows. Finally, we empirically evaluate our approach on both synthetic and high-dimensional text-to-image diffusion, demonstrating promising results.
Sinkhorn Flow: A Continuous-Time Framework for Understanding and Generalizing the Sinkhorn Algorithm
Nov 28, 2023Many problems in machine learning can be formulated as solving entropy-regularized optimal transport on the space of probability measures. The canonical approach involves the Sinkhorn iterates, renowned for their rich mathematical properties. Recently, the Sinkhorn algorithm has been recast within the mirror descent framework, thus benefiting from classical optimization theory insights. Here, we build upon this result by introducing a continuous-time analogue of the Sinkhorn algorithm. This perspective allows us to derive novel variants of Sinkhorn schemes that are robust to noise and bias. Moreover, our continuous-time dynamics not only generalize but also offer a unified perspective on several recently discovered dynamics in machine learning and mathematics, such as the "Wasserstein mirror flow" of (Deb et al. 2023) or the "mean-field Schr\"odinger equation" of (Claisse et al. 2023).
Riemannian stochastic optimization methods avoid strict saddle points
Nov 04, 2023

Many modern machine learning applications - from online principal component analysis to covariance matrix identification and dictionary learning - can be formulated as minimization problems on Riemannian manifolds, and are typically solved with a Riemannian stochastic gradient method (or some variant thereof). However, in many cases of interest, the resulting minimization problem is not geodesically convex, so the convergence of the chosen solver to a desirable solution - i.e., a local minimizer - is by no means guaranteed. In this paper, we study precisely this question, that is, whether stochastic Riemannian optimization algorithms are guaranteed to avoid saddle points with probability 1. For generality, we study a family of retraction-based methods which, in addition to having a potentially much lower per-iteration cost relative to Riemannian gradient descent, include other widely used algorithms, such as natural policy gradient methods and mirror descent in ordinary convex spaces. In this general setting, we show that, under mild assumptions for the ambient manifold and the oracle providing gradient information, the policies under study avoid strict saddle points / submanifolds with probability 1, from any initial condition. This result provides an important sanity check for the use of gradient methods on manifolds as it shows that, almost always, the limit state of a stochastic Riemannian algorithm can only be a local minimizer.
Unbalanced Diffusion Schrödinger Bridge
Jun 15, 2023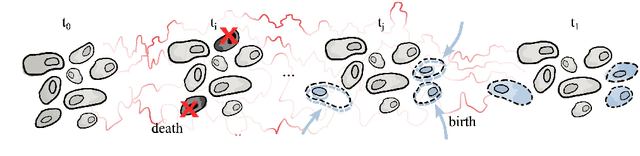

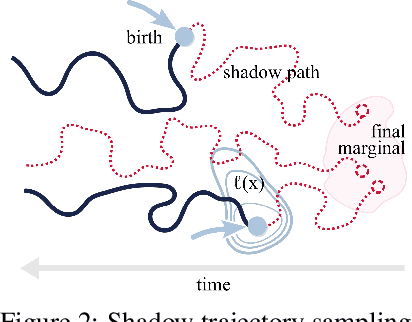

Schr\"odinger bridges (SBs) provide an elegant framework for modeling the temporal evolution of populations in physical, chemical, or biological systems. Such natural processes are commonly subject to changes in population size over time due to the emergence of new species or birth and death events. However, existing neural parameterizations of SBs such as diffusion Schr\"odinger bridges (DSBs) are restricted to settings in which the endpoints of the stochastic process are both probability measures and assume conservation of mass constraints. To address this limitation, we introduce unbalanced DSBs which model the temporal evolution of marginals with arbitrary finite mass. This is achieved by deriving the time reversal of stochastic differential equations with killing and birth terms. We present two novel algorithmic schemes that comprise a scalable objective function for training unbalanced DSBs and provide a theoretical analysis alongside challenging applications on predicting heterogeneous molecular single-cell responses to various cancer drugs and simulating the emergence and spread of new viral variants.
Aligned Diffusion Schrödinger Bridges
Feb 22, 2023Diffusion Schr\"odinger bridges (DSB) have recently emerged as a powerful framework for recovering stochastic dynamics via their marginal observations at different time points. Despite numerous successful applications, existing algorithms for solving DSBs have so far failed to utilize the structure of aligned data, which naturally arises in many biological phenomena. In this paper, we propose a novel algorithmic framework that, for the first time, solves DSBs while respecting the data alignment. Our approach hinges on a combination of two decades-old ideas: The classical Schr\"odinger bridge theory and Doob's $h$-transform. Compared to prior methods, our approach leads to a simpler training procedure with lower variance, which we further augment with principled regularization schemes. This ultimately leads to sizeable improvements across experiments on synthetic and real data, including the tasks of rigid protein docking and temporal evolution of cellular differentiation processes.
A Dynamical System View of Langevin-Based Non-Convex Sampling
Oct 25, 2022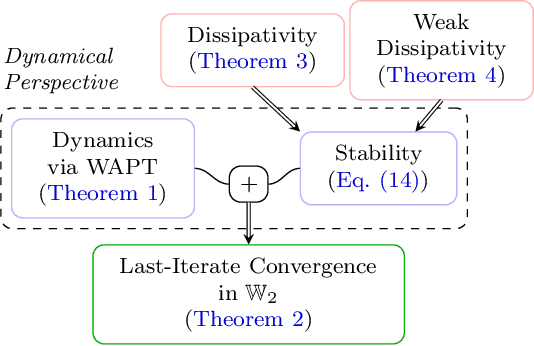
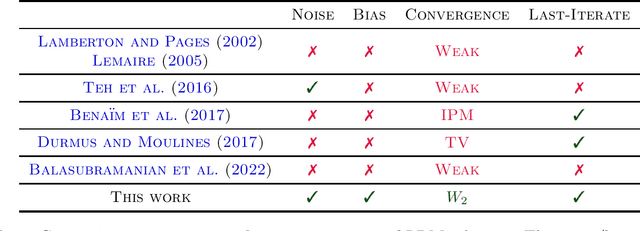
Non-convex sampling is a key challenge in machine learning, central to non-convex optimization in deep learning as well as to approximate probabilistic inference. Despite its significance, theoretically there remain many important challenges: Existing guarantees (1) typically only hold for the averaged iterates rather than the more desirable last iterates, (2) lack convergence metrics that capture the scales of the variables such as Wasserstein distances, and (3) mainly apply to elementary schemes such as stochastic gradient Langevin dynamics. In this paper, we develop a new framework that lifts the above issues by harnessing several tools from the theory of dynamical systems. Our key result is that, for a large class of state-of-the-art sampling schemes, their last-iterate convergence in Wasserstein distances can be reduced to the study of their continuous-time counterparts, which is much better understood. Coupled with standard assumptions of MCMC sampling, our theory immediately yields the last-iterate Wasserstein convergence of many advanced sampling schemes such as proximal, randomized mid-point, and Runge-Kutta integrators. Beyond existing methods, our framework also motivates more efficient schemes that enjoy the same rigorous guarantees.