 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-Based Hyperparameter Selection in Games
Jan 26, 2026Learning in smooth games fundamentally differs from standard minimization due to rotational dynamics, which invalidate classical hyperparameter tuning strategies. Despite their practical importance, effective methods for tuning in games remain underexplored. A notable example is LookAhead (LA), which achieves strong empirical performance but introduces additional parameters that critically influence performance. We propose a principled approach to hyperparameter selection in games by leveraging frequency estimation of oscillatory dynamics. Specifically, we analyze oscillations both in continuous-time trajectories and through the spectrum of the discrete dynamics in the associated frequency-based space. Building on this analysis, we introduce \emph{Modal LookAhead (MoLA)}, an extension of LA that selects the hyperparameters adaptively to a given problem. We provide convergence guarantees and demonstrate in experiments that MoLA accelerates training in both purely rotational games and mixed regimes, all with minimal computational overhead.
Understanding Lookahead Dynamics Through Laplace Transform
Jun 16, 2025We introduce a frequency-domain framework for convergence analysis of hyperparameters in game optimization, leveraging High-Resolution Differential Equations (HRDEs) and Laplace transforms. Focusing on the Lookahead algorithm--characterized by gradient steps $k$ and averaging coefficient $\alpha$--we transform the discrete-time oscillatory dynamics of bilinear games into the frequency domain to derive precise convergence criteria. Our higher-precision $O(\gamma^2)$-HRDE models yield tighter criteria, while our first-order $O(\gamma)$-HRDE models offer practical guidance by prioritizing actionable hyperparameter tuning over complex closed-form solutions. Empirical validation in discrete-time settings demonstrates the effectiveness of our approach, which may further extend to locally linear operators, offering a scalable framework for selecting hyperparameters for learning in games.
Decoupled SGDA for Games with Intermittent Strategy Communication
Jan 24, 2025We focus on reducing communication overhead in multiplayer games, where frequently exchanging strategies between players is not feasible and players have noisy or outdated strategies of the other players. We introduce Decoupled SGDA, a novel adaptation of Stochastic Gradient Descent Ascent (SGDA). In this approach, players independently update their strategies based on outdated opponent strategies, with periodic synchronization to align strategies. For Strongly-Convex-Strongly-Concave (SCSC) games, we demonstrate that Decoupled SGDA achieves near-optimal communication complexity comparable to the best-known GDA rates. For weakly coupled games where the interaction between players is lower relative to the non-interactive part of the game, Decoupled SGDA significantly reduces communication costs compared to standard SGDA. Our findings extend to multi-player games. To provide insights into the effect of communication frequency and convergence, we extensively study the convergence of Decoupled SGDA for quadratic minimax problems. Lastly, in settings where the noise over the players is imbalanced, Decoupled SGDA significantly outperforms federated minimax methods.
Learning Variational Inequalities from Data: Fast Generalization Rates under Strong Monotonicity
Oct 28, 2024Variational inequalities (VIs) are a broad class of optimization problems encompassing machine learning problems ranging from standard convex minimization to more complex scenarios like min-max optimization and computing the equilibria of multi-player games. In convex optimization, strong convexity allows for fast statistical learning rates requiring only $\Theta(1/\epsilon)$ stochastic first-order oracle calls to find an $\epsilon$-optimal solution, rather than the standard $\Theta(1/\epsilon^2)$ calls. In this paper, we explain how one can similarly obtain fast $\Theta(1/\epsilon)$ rates for learning VIs that satisfy strong monotonicity, a generalization of strong convexity. Specifically, we demonstrate that standard stability-based generalization arguments for convex minimization extend directly to VIs when the domain admits a small covering, or when the operator is integrable and suboptimality is measured by potential functions; such as when finding equilibria in multi-player games.
On the Hypomonotone Class of Variational Inequalities
Oct 11, 2024This paper studies the behavior of the extragradient algorithm when applied to hypomonotone operators, a class of problems that extends beyond the classical monotone setting. While the extragradient method is widely known for its efficacy in solving variational inequalities with monotone and Lipschitz continuous operators, we demonstrate that its convergence is not guaranteed in the hypomonotone setting. We provide a characterization theorem that identifies the conditions under which the extragradient algorithm fails to converge. Our results highlight the necessity of stronger assumptions to guarantee convergence of extragradient and to further develop the existing VI methods for broader problems.
Variational Inequality Methods for Multi-Agent Reinforcement Learning: Performance and Stability Gains
Oct 10, 2024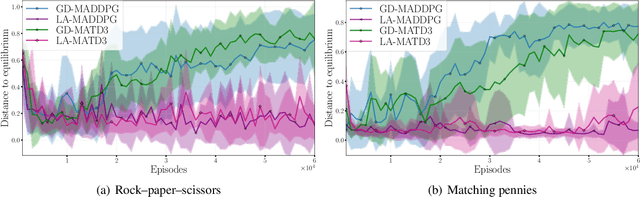

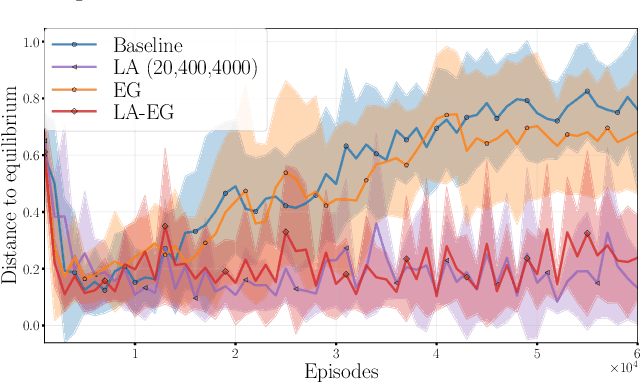
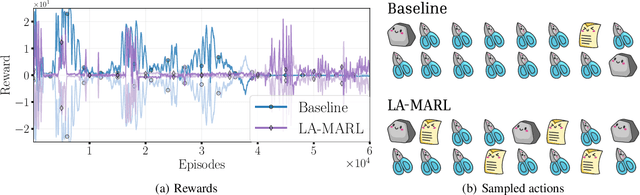
Multi-agent reinforcement learning (MARL) presents unique challenges as agents learn strategies through experiences. Gradient-based methods are often sensitive to hyperparameter selection and initial random seed variations. Concurrently, significant advances have been made in solving Variational Inequalities (VIs) which include equilibrium-finding problems particularly in addressing the non-converging rotational dynamics that impede convergence of traditional gradient based optimization methods. This paper explores the potential of leveraging VI-based techniques to improve MARL training. Specifically, we study the performance of VI method namely, Nested-Lookahead VI (nLA-VI) and Extragradient (EG) in enhancing the multi-agent deep deterministic policy gradient (MADDPG) algorithm. We present a VI reformulation of the actor-critic algorithm for both single- and multi-agent settings. We introduce three algorithms that use nLA-VI, EG, and a combination of both, named LA-MADDPG, EG-MADDPG, and LA-EG-MADDPG, respectively. Our empirical results demonstrate that these VI-based approaches yield significant performance improvements in benchmark environments, such as the zero-sum games: rock-paper-scissors and matching pennies, where equilibrium strategies can be quantitatively assessed, and the Multi-Agent Particle Environment: Predator prey benchmark, where VI-based methods also yield balanced participation of agents from the same team.
Revisiting the ACVI Method for Constrained Variational Inequalities
Oct 27, 2022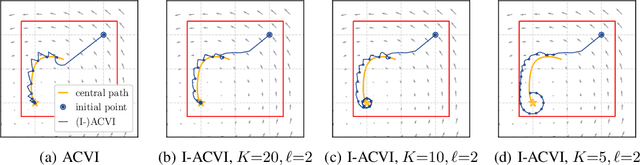
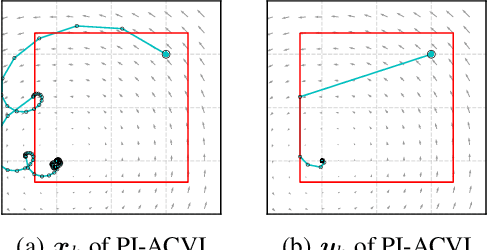

ACVI is a recently proposed first-order method for solving variational inequalities (VIs) with general constraints. Yang et al. (2022) showed that the gap function of the last iterate decreases at a rate of $\mathcal{O}(\frac{1}{\sqrt{K}})$ when the operator is $L$-Lipschitz, monotone, and at least one constraint is active. In this work, we show that the same guarantee holds when only assuming that the operator is monotone. To our knowledge, this is the first analytically derived last-iterate convergence rate for general monotone VIs, and overall the only one that does not rely on the assumption that the operator is $L$-Lipschitz. Furthermore, when the sub-problems of ACVI are solved approximately, we show that by using a standard warm-start technique the convergence rate stays the same, provided that the errors decrease at appropriate rates. We further provide empirical analyses and insights on its implementation for the latter case.
Continuous-time Analysis for Variational Inequalities: An Overview and Desiderata
Jul 14, 2022Algorithms that solve zero-sum games, multi-objective agent objectives, or, more generally, variational inequality (VI) problems are notoriously unstable on general problems. Owing to the increasing need for solving such problems in machine learning, this instability has been highlighted in recent years as a significant research challenge. In this paper, we provide an overview of recent progress in the use of continuous-time perspectives in the analysis and design of methods targeting the broad VI problem class. Our presentation draws parallels between single-objective problems and multi-objective problems, highlighting the challenges of the latter. We also formulate various desiderata for algorithms that apply to general VIs and we argue that achieving these desiderata may profit from an understanding of the associated continuous-time dynamics.
Solving Constrained Variational Inequalities via an Interior Point Method
Jun 21, 2022



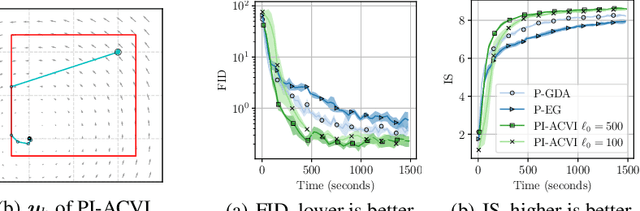
We develop an interior-point approach to solve constrained variational inequality (cVI) problems. Inspired by the efficacy of the alternating direction method of multipliers (ADMM) method in the single-objective context, we generalize ADMM to derive a first-order method for cVIs, that we refer to as ADMM-based interior point method for constrained VIs (ACVI). We provide convergence guarantees for ACVI in two general classes of problems: (i) when the operator is $\xi$-monotone, and (ii) when it is monotone, the constraints are active and the game is not purely rotational. When the operator is in addition L-Lipschitz for the latter case, we match known lower bounds on rates for the gap function of $\mathcal{O}(1/\sqrt{K})$ and $\mathcal{O}(1/K)$ for the last and average iterate, respectively. To the best of our knowledge, this is the first presentation of a first-order interior-point method for the general cVI problem that has a global convergence guarantee. Moreover, unlike previous work in this setting, ACVI provides a means to solve cVIs when the constraints are nontrivial. Empirical analyses demonstrate clear advantages of ACVI over common first-order methods. In particular, (i) cyclical behavior is notably reduced as our methods approach the solution from the analytic center, and (ii) unlike projection-based methods that oscillate when near a constraint, ACVI efficiently handles the constraints.
Improving Generalization via Uncertainty Driven Perturbations
Feb 28, 2022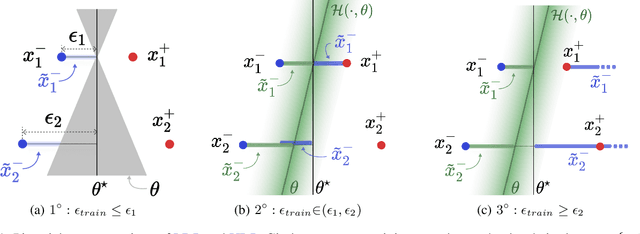
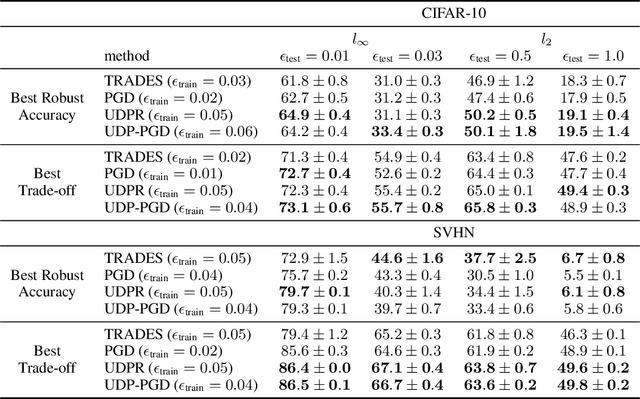
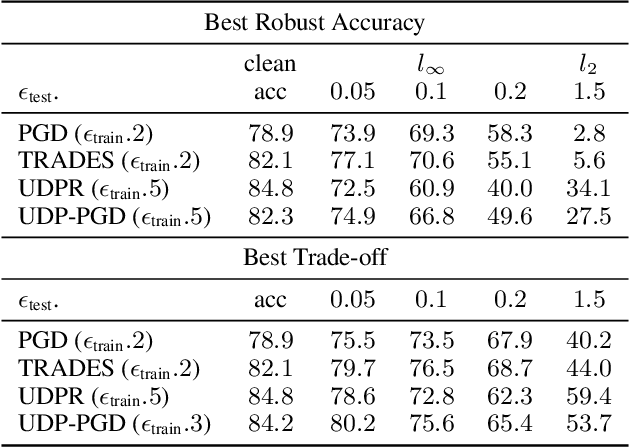
Recently Shah et al., 2020 pointed out the pitfalls of the simplicity bias - the tendency of gradient-based algorithms to learn simple models - which include the model's high sensitivity to small input perturbations, as well as sub-optimal margins. In particular, while Stochastic Gradient Descent yields max-margin boundary on linear models, such guarantee does not extend to non-linear models. To mitigate the simplicity bias, we consider uncertainty-driven perturbations (UDP) of the training data points, obtained iteratively by following the direction that maximizes the model's estimated uncertainty. The uncertainty estimate does not rely on the input's label and it is highest at the decision boundary, and - unlike loss-driven perturbations - it allows for using a larger range of values for the perturbation magnitude. Furthermore, as real-world datasets have non-isotropic distances between data points of different classes, the above property is particularly appealing for increasing the margin of the decision boundary, which in turn improves the model's generalization. We show that UDP is guaranteed to achieve the maximum margin decision boundary on linear models and that it notably increases it on challenging simulated datasets. For nonlinear models, we show empirically that UDP reduces the simplicity bias and learns more exhaustive features. Interestingly, it also achieves competitive loss-based robustness and generalization trade-off on several datasets.