 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Inequality Methods for Multi-Agent Reinforcement Learning: Performance and Stability Gains
Paper and Code
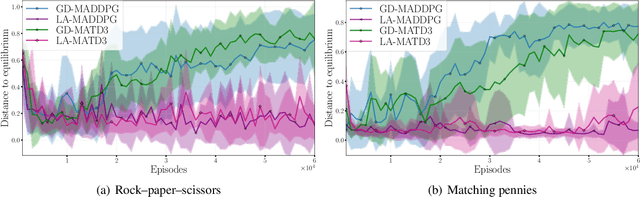

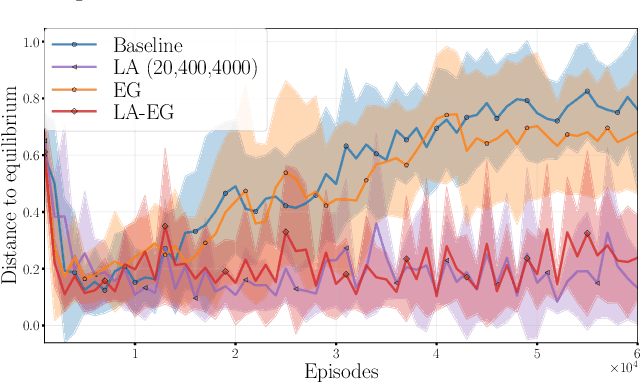
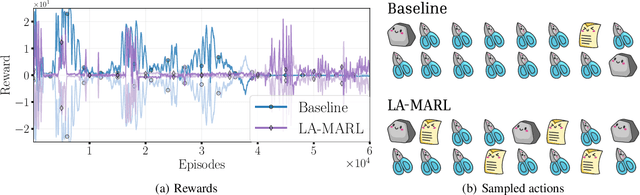
Multi-agent reinforcement learning (MARL) presents unique challenges as agents learn strategies through experiences. Gradient-based methods are often sensitive to hyperparameter selection and initial random seed variations. Concurrently, significant advances have been made in solving Variational Inequalities (VIs) which include equilibrium-finding problems particularly in addressing the non-converging rotational dynamics that impede convergence of traditional gradient based optimization methods. This paper explores the potential of leveraging VI-based techniques to improve MARL training. Specifically, we study the performance of VI method namely, Nested-Lookahead VI (nLA-VI) and Extragradient (EG) in enhancing the multi-agent deep deterministic policy gradient (MADDPG) algorithm. We present a VI reformulation of the actor-critic algorithm for both single- and multi-agent settings. We introduce three algorithms that use nLA-VI, EG, and a combination of both, named LA-MADDPG, EG-MADDPG, and LA-EG-MADDPG, respectively. Our empirical results demonstrate that these VI-based approaches yield significant performance improvements in benchmark environments, such as the zero-sum games: rock-paper-scissors and matching pennies, where equilibrium strategies can be quantitatively assessed, and the Multi-Agent Particle Environment: Predator prey benchmark, where VI-based methods also yield balanced participation of agents from the same team.