 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrequency-Based Hyperparameter Selection in Games
Jan 26, 2026Learning in smooth games fundamentally differs from standard minimization due to rotational dynamics, which invalidate classical hyperparameter tuning strategies. Despite their practical importance, effective methods for tuning in games remain underexplored. A notable example is LookAhead (LA), which achieves strong empirical performance but introduces additional parameters that critically influence performance. We propose a principled approach to hyperparameter selection in games by leveraging frequency estimation of oscillatory dynamics. Specifically, we analyze oscillations both in continuous-time trajectories and through the spectrum of the discrete dynamics in the associated frequency-based space. Building on this analysis, we introduce \emph{Modal LookAhead (MoLA)}, an extension of LA that selects the hyperparameters adaptively to a given problem. We provide convergence guarantees and demonstrate in experiments that MoLA accelerates training in both purely rotational games and mixed regimes, all with minimal computational overhead.
Variational Inequality Methods for Multi-Agent Reinforcement Learning: Performance and Stability Gains
Oct 10, 2024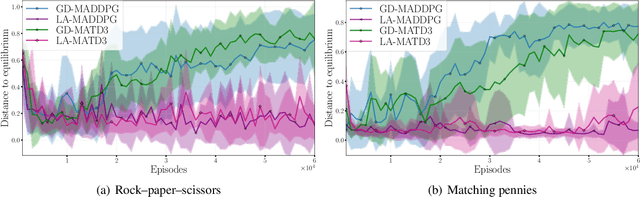

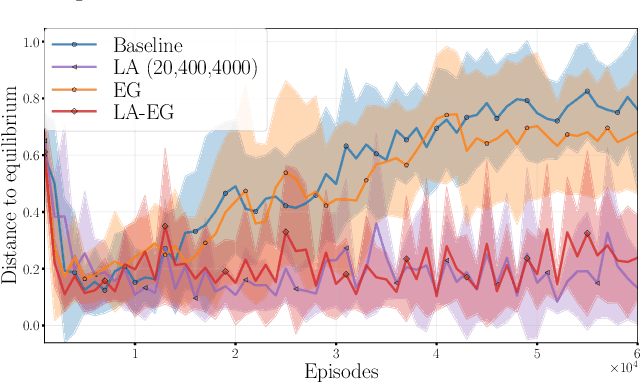
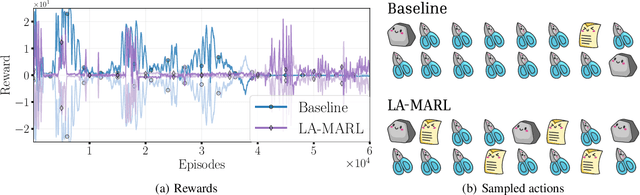
Multi-agent reinforcement learning (MARL) presents unique challenges as agents learn strategies through experiences. Gradient-based methods are often sensitive to hyperparameter selection and initial random seed variations. Concurrently, significant advances have been made in solving Variational Inequalities (VIs) which include equilibrium-finding problems particularly in addressing the non-converging rotational dynamics that impede convergence of traditional gradient based optimization methods. This paper explores the potential of leveraging VI-based techniques to improve MARL training. Specifically, we study the performance of VI method namely, Nested-Lookahead VI (nLA-VI) and Extragradient (EG) in enhancing the multi-agent deep deterministic policy gradient (MADDPG) algorithm. We present a VI reformulation of the actor-critic algorithm for both single- and multi-agent settings. We introduce three algorithms that use nLA-VI, EG, and a combination of both, named LA-MADDPG, EG-MADDPG, and LA-EG-MADDPG, respectively. Our empirical results demonstrate that these VI-based approaches yield significant performance improvements in benchmark environments, such as the zero-sum games: rock-paper-scissors and matching pennies, where equilibrium strategies can be quantitatively assessed, and the Multi-Agent Particle Environment: Predator prey benchmark, where VI-based methods also yield balanced participation of agents from the same team.