 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuagmires in SFT-RL Post-Training: When High SFT Scores Mislead and What to Use Instead
Oct 02, 2025In post-training for reasoning Large Language Models (LLMs), the current state of practice trains LLMs in two independent stages: Supervised Fine-Tuning (SFT) and Reinforcement Learning with Verifiable Rewards (RLVR, shortened as ``RL'' below). In this work, we challenge whether high SFT scores translate to improved performance after RL. We provide extensive counter-examples where this is not true. We find high SFT scores can be biased toward simpler or more homogeneous data and are not reliably predictive of subsequent RL gains or scaled-up post-training effectiveness. In some cases, RL training on models with improved SFT performance could lead to substantially worse outcome compared to RL on the base model without SFT. We study alternative metrics and identify generalization loss on held-out reasoning examples and Pass@large k performance to provide strong proxies for the RL outcome. We trained hundreds of models up to 12B-parameter with SFT and RLVR via GRPO and ran extensive evaluations on 7 math benchmarks with up to 256 repetitions, spending $>$1M GPU hours. Experiments include models from Llama3, Mistral-Nemo, Qwen3 and multiple state-of-the-art SFT/RL datasets. Compared to directly predicting from pre-RL performance, prediction based on generalization loss and Pass@large k achieves substantial higher precision, improving $R^2$ coefficient and Spearman's rank correlation coefficient by up to 0.5 (2x). This provides strong utility for broad use cases. For example, in most experiments, we find SFT training on unique examples for a one epoch underperforms training on half examples for two epochs, either after SFT or SFT-then-RL; With the same SFT budget, training only on short examples may lead to better SFT performance, though, it often leads to worse outcome after RL compared to training on examples with varying lengths. Evaluation tool will be open-sourced.
Divide, Discover, Deploy: Factorized Skill Learning with Symmetry and Style Priors
Aug 27, 2025Unsupervised Skill Discovery (USD) allows agents to autonomously learn diverse behaviors without task-specific rewards. While recent USD methods have shown promise, their application to real-world robotics remains underexplored. In this paper, we propose a modular USD framework to address the challenges in the safety, interpretability, and deployability of the learned skills. Our approach employs user-defined factorization of the state space to learn disentangled skill representations. It assigns different skill discovery algorithms to each factor based on the desired intrinsic reward function. To encourage structured morphology-aware skills, we introduce symmetry-based inductive biases tailored to individual factors. We also incorporate a style factor and regularization penalties to promote safe and robust behaviors. We evaluate our framework in simulation using a quadrupedal robot and demonstrate zero-shot transfer of the learned skills to real hardware. Our results show that factorization and symmetry lead to the discovery of structured human-interpretable behaviors, while the style factor and penalties enhance safety and diversity. Additionally, we show that the learned skills can be used for downstream tasks and perform on par with oracle policies trained with hand-crafted rewards.
Provable Maximum Entropy Manifold Exploration via Diffusion Models
Jun 18, 2025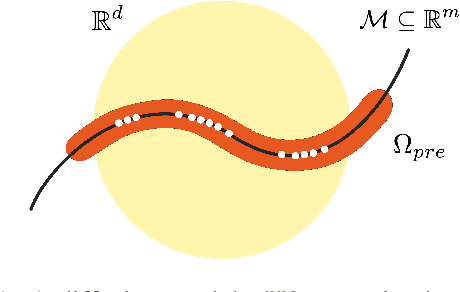

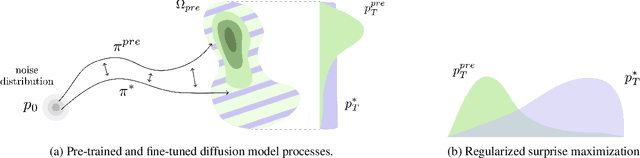

Exploration is critical for solving real-world decision-making problems such as scientific discovery, where the objective is to generate truly novel designs rather than mimic existing data distributions. In this work, we address the challenge of leveraging the representational power of generative models for exploration without relying on explicit uncertainty quantification. We introduce a novel framework that casts exploration as entropy maximization over the approximate data manifold implicitly defined by a pre-trained diffusion model. Then, we present a novel principle for exploration based on density estimation, a problem well-known to be challenging in practice. To overcome this issue and render this method truly scalable, we leverage a fundamental connection between the entropy of the density induced by a diffusion model and its score function. Building on this, we develop an algorithm based on mirror descent that solves the exploration problem as sequential fine-tuning of a pre-trained diffusion model. We prove its convergence to the optimal exploratory diffusion model under realistic assumptions by leveraging recent understanding of mirror flows. Finally, we empirically evaluate our approach on both synthetic and high-dimensional text-to-image diffusion, demonstrating promising results.
Dual-Force: Enhanced Offline Diversity Maximization under Imitation Constraints
Jan 08, 2025


While many algorithms for diversity maximization under imitation constraints are online in nature, many applications require offline algorithms without environment interactions. Tackling this problem in the offline setting, however, presents significant challenges that require non-trivial, multi-stage optimization processes with non-stationary rewards. In this work, we present a novel offline algorithm that enhances diversity using an objective based on Van der Waals (VdW) force and successor features, and eliminates the need to learn a previously used skill discriminator. Moreover, by conditioning the value function and policy on a pre-trained Functional Reward Encoding (FRE), our method allows for better handling of non-stationary rewards and provides zero-shot recall of all skills encountered during training, significantly expanding the set of skills learned in prior work. Consequently, our algorithm benefits from receiving a consistently strong diversity signal (VdW), and enjoys more stable and efficient training. We demonstrate the effectiveness of our method in generating diverse skills for two robotic tasks in simulation: locomotion of a quadruped and local navigation with obstacle traversal.
Causal Action Influence Aware Counterfactual Data Augmentation
May 29, 2024



Offline data are both valuable and practical resources for teaching robots complex behaviors. Ideally, learning agents should not be constrained by the scarcity of available demonstrations, but rather generalize beyond the training distribution. However, the complexity of real-world scenarios typically requires huge amounts of data to prevent neural network policies from picking up on spurious correlations and learning non-causal relationships. We propose CAIAC, a data augmentation method that can create feasible synthetic transitions from a fixed dataset without having access to online environment interactions. By utilizing principled methods for quantifying causal influence, we are able to perform counterfactual reasoning by swapping $\it{action}$-unaffected parts of the state-space between independent trajectories in the dataset. We empirically show that this leads to a substantial increase in robustness of offline learning algorithms against distributional shift.
Learning Diverse Skills for Local Navigation under Multi-constraint Optimality
Oct 03, 2023



Despite many successful applications of data-driven control in robotics, extracting meaningful diverse behaviors remains a challenge. Typically, task performance needs to be compromised in order to achieve diversity. In many scenarios, task requirements are specified as a multitude of reward terms, each requiring a different trade-off. In this work, we take a constrained optimization viewpoint on the quality-diversity trade-off and show that we can obtain diverse policies while imposing constraints on their value functions which are defined through distinct rewards. In line with previous work, further control of the diversity level can be achieved through an attract-repel reward term motivated by the Van der Waals force. We demonstrate the effectiveness of our method on a local navigation task where a quadruped robot needs to reach the target within a finite horizon. Finally, our trained policies transfer well to the real 12-DoF quadruped robot, Solo12, and exhibit diverse agile behaviors with successful obstacle traversal.
Diffusion Generative Inverse Design
Sep 18, 2023



Inverse design refers to the problem of optimizing the input of an objective function in order to enact a target outcome. For many real-world engineering problems, the objective function takes the form of a simulator that predicts how the system state will evolve over time, and the design challenge is to optimize the initial conditions that lead to a target outcome. Recent developments in learned simulation have shown that graph neural networks (GNNs) can be used for accurate, efficient, differentiable estimation of simulator dynamics, and support high-quality design optimization with gradient- or sampling-based optimization procedures. However, optimizing designs from scratch requires many expensive model queries, and these procedures exhibit basic failures on either non-convex or high-dimensional problems. In this work, we show how denoising diffusion models (DDMs) can be used to solve inverse design problems efficiently and propose a particle sampling algorithm for further improving their efficiency. We perform experiments on a number of fluid dynamics design challenges, and find that our approach substantially reduces the number of calls to the simulator compared to standard techniques.
Mind the Uncertainty: Risk-Aware and Actively Exploring Model-Based Reinforcement Learning
Sep 11, 2023


We introduce a simple but effective method for managing risk in model-based reinforcement learning with trajectory sampling that involves probabilistic safety constraints and balancing of optimism in the face of epistemic uncertainty and pessimism in the face of aleatoric uncertainty of an ensemble of stochastic neural networks.Various experiments indicate that the separation of uncertainties is essential to performing well with data-driven MPC approaches in uncertain and safety-critical control environments.
Diverse Offline Imitation via Fenchel Duality
Jul 21, 2023



There has been significant recent progress in the area of unsupervised skill discovery, with various works proposing mutual information based objectives, as a source of intrinsic motivation. Prior works predominantly focused on designing algorithms that require online access to the environment. In contrast, we develop an \textit{offline} skill discovery algorithm. Our problem formulation considers the maximization of a mutual information objective constrained by a KL-divergence. More precisely, the constraints ensure that the state occupancy of each skill remains close to the state occupancy of an expert, within the support of an offline dataset with good state-action coverage. Our main contribution is to connect Fenchel duality, reinforcement learning and unsupervised skill discovery, and to give a simple offline algorithm for learning diverse skills that are aligned with an expert.
Spuriosity Didn't Kill the Classifier: Using Invariant Predictions to Harness Spurious Features
Jul 19, 2023



To avoid failures on out-of-distribution data, recent works have sought to extract features that have a stable or invariant relationship with the label across domains, discarding the "spurious" or unstable features whose relationship with the label changes across domains. However, unstable features often carry complementary information about the label that could boost performance if used correctly in the test domain. Our main contribution is to show that it is possible to learn how to use these unstable features in the test domain without labels. In particular, we prove that pseudo-labels based on stable features provide sufficient guidance for doing so, provided that stable and unstable features are conditionally independent given the label. Based on this theoretical insight, we propose Stable Feature Boosting (SFB), an algorithm for: (i) learning a predictor that separates stable and conditionally-independent unstable features; and (ii) using the stable-feature predictions to adapt the unstable-feature predictions in the test domain. Theoretically, we prove that SFB can learn an asymptotically-optimal predictor without test-domain labels. Empirically, we demonstrate the effectiveness of SFB on real and synthetic data.