 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Uncertainty: Risk-Aware and Actively Exploring Model-Based Reinforcement Learning
Sep 11, 2023


We introduce a simple but effective method for managing risk in model-based reinforcement learning with trajectory sampling that involves probabilistic safety constraints and balancing of optimism in the face of epistemic uncertainty and pessimism in the face of aleatoric uncertainty of an ensemble of stochastic neural networks.Various experiments indicate that the separation of uncertainties is essential to performing well with data-driven MPC approaches in uncertain and safety-critical control environments.
Real Robot Challenge 2022: Learning Dexterous Manipulation from Offline Data in the Real World
Sep 04, 2023Experimentation on real robots is demanding in terms of time and costs. For this reason, a large part of the reinforcement learning (RL) community uses simulators to develop and benchmark algorithms. However, insights gained in simulation do not necessarily translate to real robots, in particular for tasks involving complex interactions with the environment. The Real Robot Challenge 2022 therefore served as a bridge between the RL and robotics communities by allowing participants to experiment remotely with a real robot - as easily as in simulation. In the last years, offline reinforcement learning has matured into a promising paradigm for learning from pre-collected datasets, alleviating the reliance on expensive online interactions. We therefore asked the participants to learn two dexterous manipulation tasks involving pushing, grasping, and in-hand orientation from provided real-robot datasets. An extensive software documentation and an initial stage based on a simulation of the real set-up made the competition particularly accessible. By giving each team plenty of access budget to evaluate their offline-learned policies on a cluster of seven identical real TriFinger platforms, we organized an exciting competition for machine learners and roboticists alike. In this work we state the rules of the competition, present the methods used by the winning teams and compare their results with a benchmark of state-of-the-art offline RL algorithms on the challenge datasets.
Benchmarking Offline Reinforcement Learning on Real-Robot Hardware
Jul 28, 2023



Learning policies from previously recorded data is a promising direction for real-world robotics tasks, as online learning is often infeasible. Dexterous manipulation in particular remains an open problem in its general form. The combination of offline reinforcement learning with large diverse datasets, however, has the potential to lead to a breakthrough in this challenging domain analogously to the rapid progress made in supervised learning in recent years. To coordinate the efforts of the research community toward tackling this problem, we propose a benchmark including: i) a large collection of data for offline learning from a dexterous manipulation platform on two tasks, obtained with capable RL agents trained in simulation; ii) the option to execute learned policies on a real-world robotic system and a simulation for efficient debugging. We evaluate prominent open-sourced offline reinforcement learning algorithms on the datasets and provide a reproducible experimental setup for offline reinforcement learning on real systems.
Optimistic Active Exploration of Dynamical Systems
Jun 21, 2023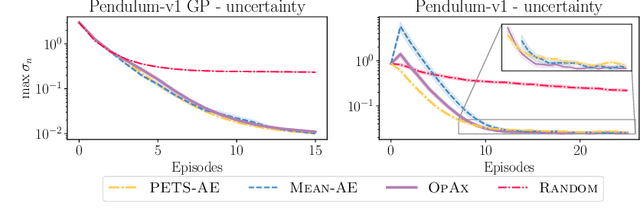
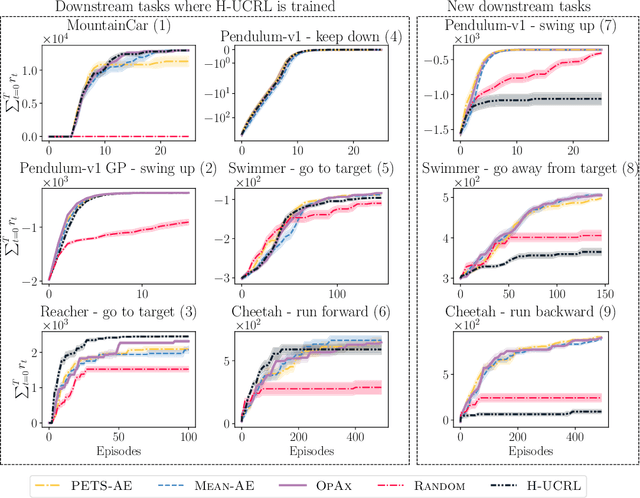
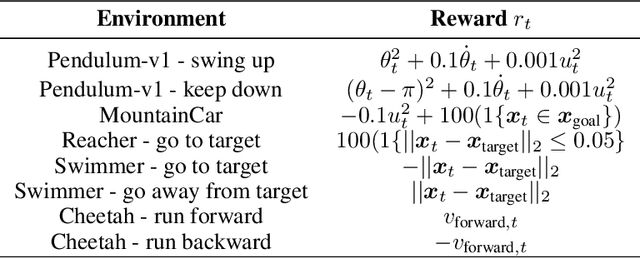
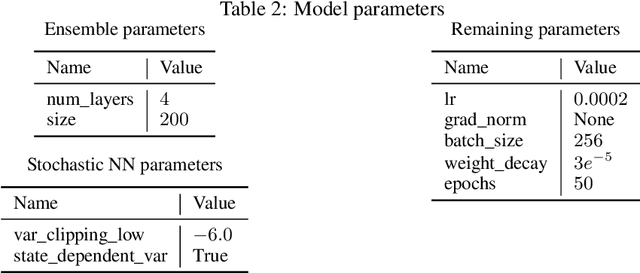
Reinforcement learning algorithms commonly seek to optimize policies for solving one particular task. How should we explore an unknown dynamical system such that the estimated model allows us to solve multiple downstream tasks in a zero-shot manner? In this paper, we address this challenge, by developing an algorithm -- OPAX -- for active exploration. OPAX uses well-calibrated probabilistic models to quantify the epistemic uncertainty about the unknown dynamics. It optimistically -- w.r.t. to plausible dynamics -- maximizes the information gain between the unknown dynamics and state observations. We show how the resulting optimization problem can be reduced to an optimal control problem that can be solved at each episode using standard approaches. We analyze our algorithm for general models, and, in the case of Gaussian process dynamics, we give a sample complexity bound and show that the epistemic uncertainty converges to zero. In our experiments, we compare OPAX with other heuristic active exploration approaches on several environments. Our experiments show that OPAX is not only theoretically sound but also performs well for zero-shot planning on novel downstream tasks.
Versatile Skill Control via Self-supervised Adversarial Imitation of Unlabeled Mixed Motions
Sep 16, 2022
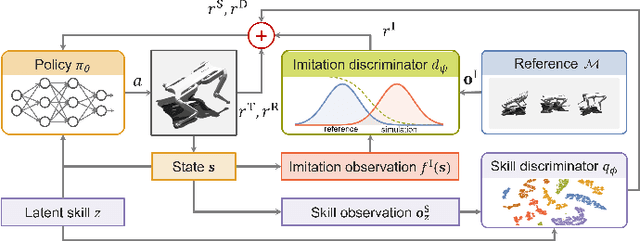

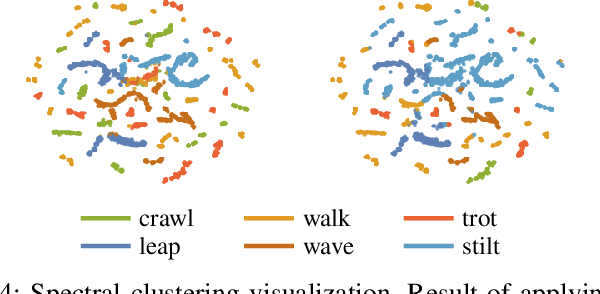
Learning diverse skills is one of the main challenges in robotics. To this end, imitation learning approaches have achieved impressive results. These methods require explicitly labeled datasets or assume consistent skill execution to enable learning and active control of individual behaviors, which limits their applicability. In this work, we propose a cooperative adversarial method for obtaining single versatile policies with controllable skill sets from unlabeled datasets containing diverse state transition patterns by maximizing their discriminability. Moreover, we show that by utilizing unsupervised skill discovery in the generative adversarial imitation learning framework, novel and useful skills emerge with successful task fulfillment. Finally, the obtained versatile policies are tested on an agile quadruped robot called Solo 8 and present faithful replications of diverse skills encoded in the demonstrations.
Learning Agile Skills via Adversarial Imitation of Rough Partial Demonstrations
Jun 23, 2022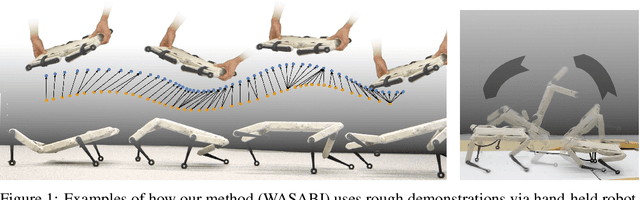

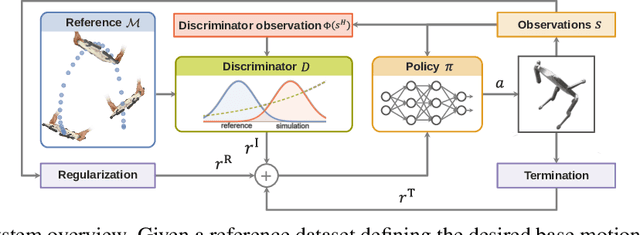

Learning agile skills is one of the main challenges in robotics. To this end, reinforcement learning approaches have achieved impressive results. These methods require explicit task information in terms of a reward function or an expert that can be queried in simulation to provide a target control output, which limits their applicability. In this work, we propose a generative adversarial method for inferring reward functions from partial and potentially physically incompatible demonstrations for successful skill acquirement where reference or expert demonstrations are not easily accessible. Moreover, we show that by using a Wasserstein GAN formulation and transitions from demonstrations with rough and partial information as input, we are able to extract policies that are robust and capable of imitating demonstrated behaviors. Finally, the obtained skills such as a backflip are tested on an agile quadruped robot called Solo 8 and present faithful replication of hand-held human demonstrations.
Curious Exploration via Structured World Models Yields Zero-Shot Object Manipulation
Jun 22, 2022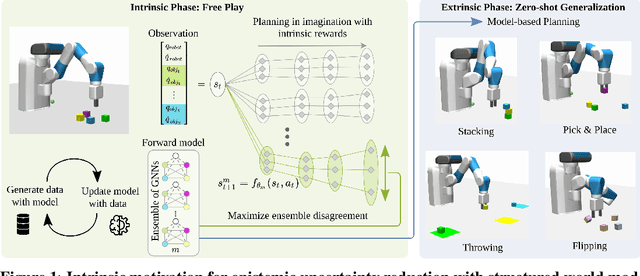

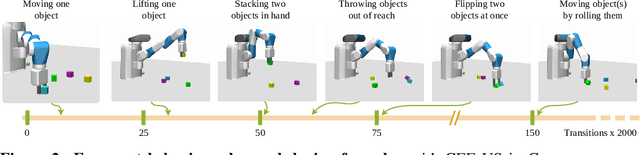
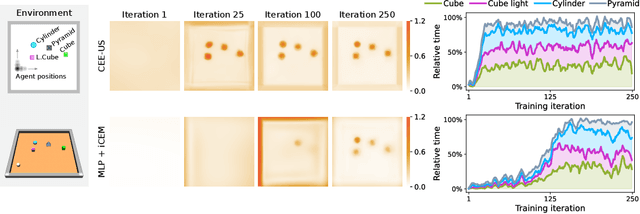
It has been a long-standing dream to design artificial agents that explore their environment efficiently via intrinsic motivation, similar to how children perform curious free play. Despite recent advances in intrinsically motivated reinforcement learning (RL), sample-efficient exploration in object manipulation scenarios remains a significant challenge as most of the relevant information lies in the sparse agent-object and object-object interactions. In this paper, we propose to use structured world models to incorporate relational inductive biases in the control loop to achieve sample-efficient and interaction-rich exploration in compositional multi-object environments. By planning for future novelty inside structured world models, our method generates free-play behavior that starts to interact with objects early on and develops more complex behavior over time. Instead of using models only to compute intrinsic rewards, as commonly done, our method showcases that the self-reinforcing cycle between good models and good exploration also opens up another avenue: zero-shot generalization to downstream tasks via model-based planning. After the entirely intrinsic task-agnostic exploration phase, our method solves challenging downstream tasks such as stacking, flipping, pick & place, and throwing that generalizes to unseen numbers and arrangements of objects without any additional training.
Sample-efficient Cross-Entropy Method for Real-time Planning
Aug 14, 2020
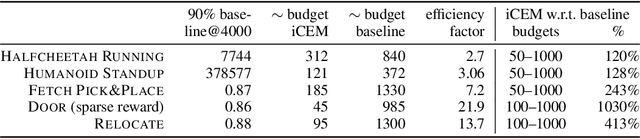
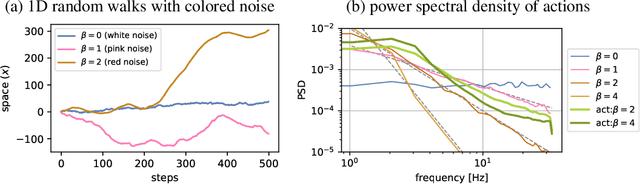
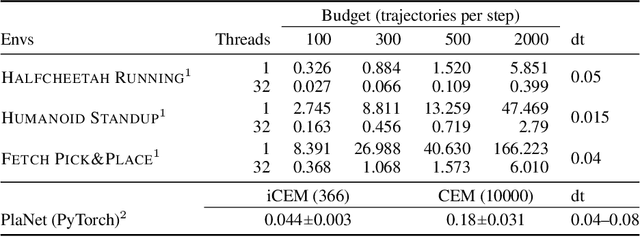
Trajectory optimizers for model-based reinforcement learning, such as the Cross-Entropy Method (CEM), can yield compelling results even in high-dimensional control tasks and sparse-reward environments. However, their sampling inefficiency prevents them from being used for real-time planning and control. We propose an improved version of the CEM algorithm for fast planning, with novel additions including temporally-correlated actions and memory, requiring 2.7-22x less samples and yielding a performance increase of 1.2-10x in high-dimensional control problems.
Control What You Can: Intrinsically Motivated Task-Planning Agent
Jun 19, 2019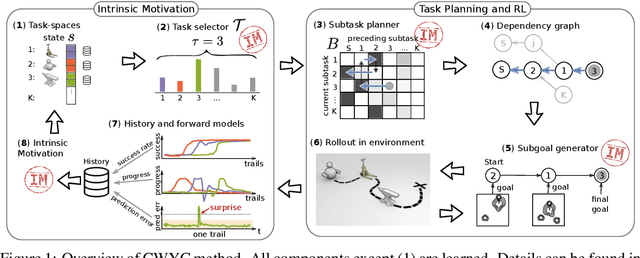
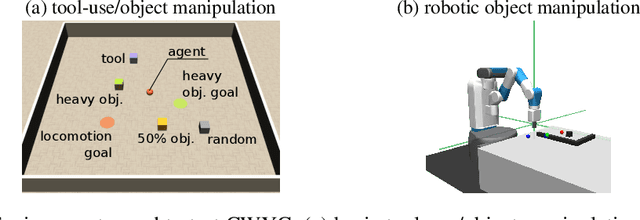
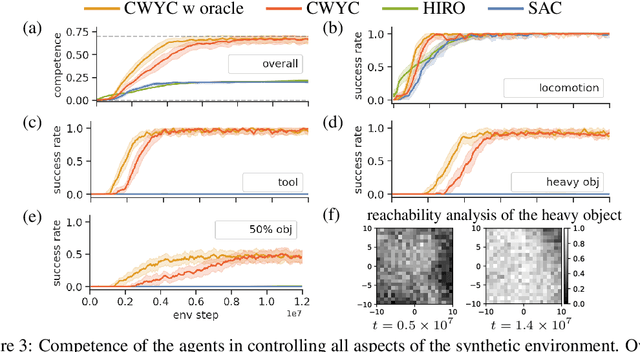
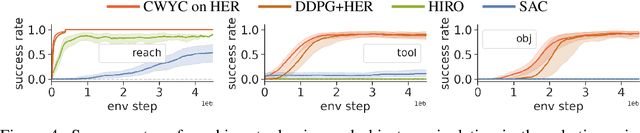
We present a novel intrinsically motivated agent that learns how to control the environment in the fastest possible manner by optimizing learning progress. It learns what can be controlled, how to allocate time and attention, and the relations between objects using surprise based motivation. The effectiveness of our method is demonstrated in a synthetic as well as a robotic manipulation environment yielding considerably improved performance and smaller sample complexity. In a nutshell, our work combines several task-level planning agent structures (backtracking search on task graph, probabilistic road-maps, allocation of search efforts) with intrinsic motivation to achieve learning from scratch.