 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Imitation Enables Contextual Humanoid Control
May 07, 2025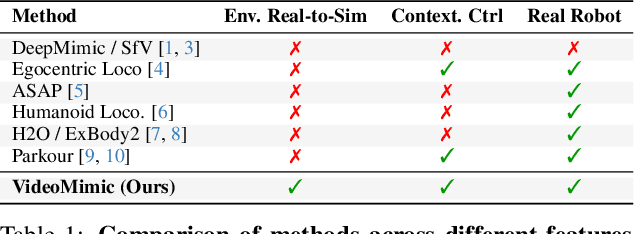
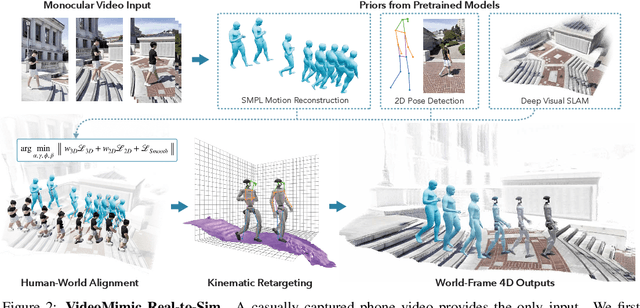

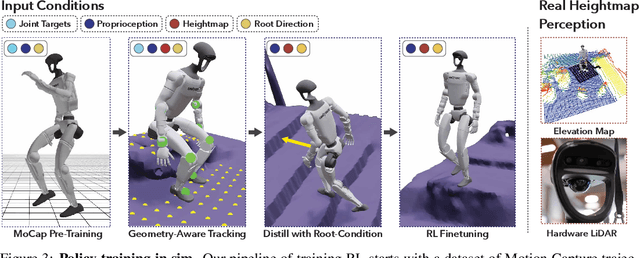
How can we teach humanoids to climb staircases and sit on chairs using the surrounding environment context? Arguably, the simplest way is to just show them-casually capture a human motion video and feed it to humanoids. We introduce VIDEOMIMIC, a real-to-sim-to-real pipeline that mines everyday videos, jointly reconstructs the humans and the environment, and produces whole-body control policies for humanoid robots that perform the corresponding skills. We demonstrate the results of our pipeline on real humanoid robots, showing robust, repeatable contextual control such as staircase ascents and descents, sitting and standing from chairs and benches, as well as other dynamic whole-body skills-all from a single policy, conditioned on the environment and global root commands. VIDEOMIMIC offers a scalable path towards teaching humanoids to operate in diverse real-world environments.
MuJoCo Playground
Feb 12, 2025We introduce MuJoCo Playground, a fully open-source framework for robot learning built with MJX, with the express goal of streamlining simulation, training, and sim-to-real transfer onto robots. With a simple "pip install playground", researchers can train policies in minutes on a single GPU. Playground supports diverse robotic platforms, including quadrupeds, humanoids, dexterous hands, and robotic arms, enabling zero-shot sim-to-real transfer from both state and pixel inputs. This is achieved through an integrated stack comprising a physics engine, batch renderer, and training environments. Along with video results, the entire framework is freely available at playground.mujoco.org
DextrAH-RGB: Visuomotor Policies to Grasp Anything with Dexterous Hands
Nov 27, 2024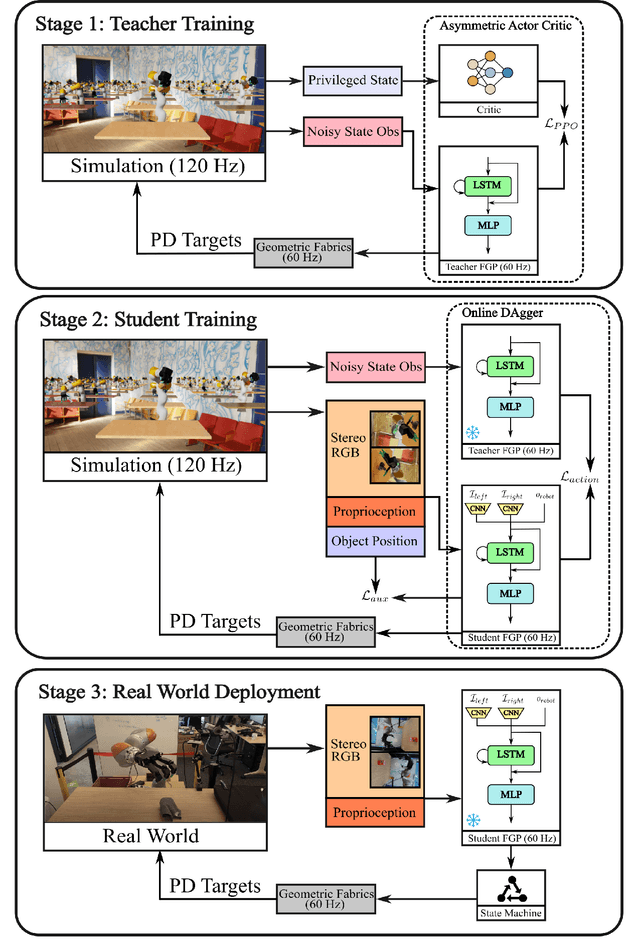



One of the most important yet challenging skills for a robot is the task of dexterous grasping of a diverse range of objects. Much of the prior work is limited by the speed, dexterity, or reliance on depth maps. In this paper, we introduce DextrAH-RGB, a system that can perform dexterous arm-hand grasping end2end from stereo RGB input. We train a teacher fabric-guided policy (FGP) in simulation through reinforcement learning that acts on a geometric fabric action space to ensure reactivity and safety. We then distill this teacher FGP into a stereo RGB-based student FGP in simulation. To our knowledge, this is the first work that is able to demonstrate robust sim2real transfer of an end2end RGB-based policy for complex, dynamic, contact-rich tasks such as dexterous grasping. Our policies are able to generalize grasping to novel objects with unseen geometry, texture, or lighting conditions during training. Videos of our system grasping a diverse range of unseen objects are available at \url{https://dextrah-rgb.github.io/}
DextrAH-G: Pixels-to-Action Dexterous Arm-Hand Grasping with Geometric Fabrics
Jul 02, 2024

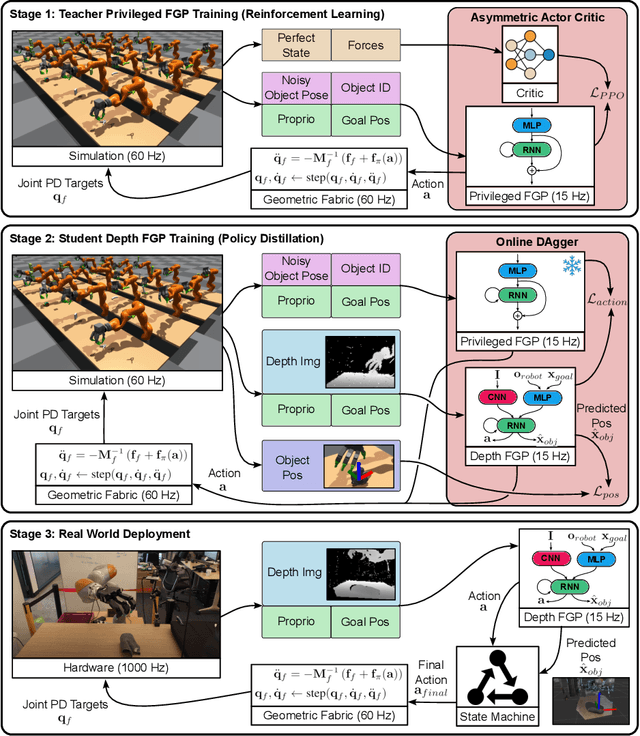
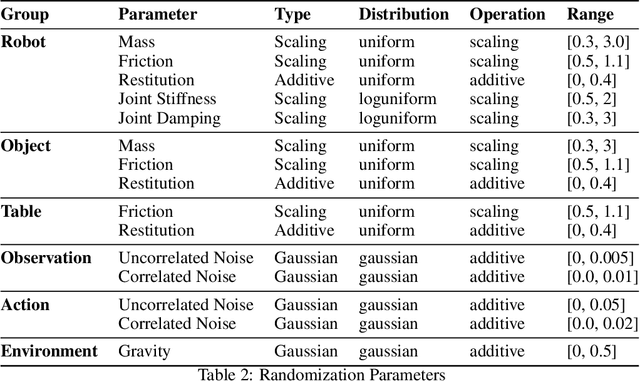
A pivotal challenge in robotics is achieving fast, safe, and robust dexterous grasping across a diverse range of objects, an important goal within industrial applications. However, existing methods often have very limited speed, dexterity, and generality, along with limited or no hardware safety guarantees. In this work, we introduce DextrAH-G, a depth-based dexterous grasping policy trained entirely in simulation that combines reinforcement learning, geometric fabrics, and teacher-student distillation. We address key challenges in joint arm-hand policy learning, such as high-dimensional observation and action spaces, the sim2real gap, collision avoidance, and hardware constraints. DextrAH-G enables a 23 motor arm-hand robot to safely and continuously grasp and transport a large variety of objects at high speed using multi-modal inputs including depth images, allowing generalization across object geometry. Videos at https://sites.google.com/view/dextrah-g.
Geometric Fabrics: a Safe Guiding Medium for Policy Learning
May 03, 2024


Robotics policies are always subjected to complex, second order dynamics that entangle their actions with resulting states. In reinforcement learning (RL) contexts, policies have the burden of deciphering these complicated interactions over massive amounts of experience and complex reward functions to learn how to accomplish tasks. Moreover, policies typically issue actions directly to controllers like Operational Space Control (OSC) or joint PD control, which induces straightline motion towards these action targets in task or joint space. However, straightline motion in these spaces for the most part do not capture the rich, nonlinear behavior our robots need to exhibit, shifting the burden of discovering these behaviors more completely to the agent. Unlike these simpler controllers, geometric fabrics capture a much richer and desirable set of behaviors via artificial, second order dynamics grounded in nonlinear geometry. These artificial dynamics shift the uncontrolled dynamics of a robot via an appropriate control law to form behavioral dynamics. Behavioral dynamics unlock a new action space and safe, guiding behavior over which RL policies are trained. Behavioral dynamics enable bang-bang-like RL policy actions that are still safe for real robots, simplify reward engineering, and help sequence real-world, high-performance policies. We describe the framework more generally and create a specific instantiation for the problem of dexterous, in-hand reorientation of a cube by a highly actuated robot hand.
Symmetry Considerations for Learning Task Symmetric Robot Policies
Mar 07, 2024



Symmetry is a fundamental aspect of many real-world robotic tasks. However, current deep reinforcement learning (DRL) approaches can seldom harness and exploit symmetry effectively. Often, the learned behaviors fail to achieve the desired transformation invariances and suffer from motion artifacts. For instance, a quadruped may exhibit different gaits when commanded to move forward or backward, even though it is symmetrical about its torso. This issue becomes further pronounced in high-dimensional or complex environments, where DRL methods are prone to local optima and fail to explore regions of the state space equally. Past methods on encouraging symmetry for robotic tasks have studied this topic mainly in a single-task setting, where symmetry usually refers to symmetry in the motion, such as the gait patterns. In this paper, we revisit this topic for goal-conditioned tasks in robotics, where symmetry lies mainly in task execution and not necessarily in the learned motions themselves. In particular, we investigate two approaches to incorporate symmetry invariance into DRL -- data augmentation and mirror loss function. We provide a theoretical foundation for using augmented samples in an on-policy setting. Based on this, we show that the corresponding approach achieves faster convergence and improves the learned behaviors in various challenging robotic tasks, from climbing boxes with a quadruped to dexterous manipulation.
Real Robot Challenge 2022: Learning Dexterous Manipulation from Offline Data in the Real World
Sep 04, 2023Experimentation on real robots is demanding in terms of time and costs. For this reason, a large part of the reinforcement learning (RL) community uses simulators to develop and benchmark algorithms. However, insights gained in simulation do not necessarily translate to real robots, in particular for tasks involving complex interactions with the environment. The Real Robot Challenge 2022 therefore served as a bridge between the RL and robotics communities by allowing participants to experiment remotely with a real robot - as easily as in simulation. In the last years, offline reinforcement learning has matured into a promising paradigm for learning from pre-collected datasets, alleviating the reliance on expensive online interactions. We therefore asked the participants to learn two dexterous manipulation tasks involving pushing, grasping, and in-hand orientation from provided real-robot datasets. An extensive software documentation and an initial stage based on a simulation of the real set-up made the competition particularly accessible. By giving each team plenty of access budget to evaluate their offline-learned policies on a cluster of seven identical real TriFinger platforms, we organized an exciting competition for machine learners and roboticists alike. In this work we state the rules of the competition, present the methods used by the winning teams and compare their results with a benchmark of state-of-the-art offline RL algorithms on the challenge datasets.
DexPBT: Scaling up Dexterous Manipulation for Hand-Arm Systems with Population Based Training
May 20, 2023



In this work, we propose algorithms and methods that enable learning dexterous object manipulation using simulated one- or two-armed robots equipped with multi-fingered hand end-effectors. Using a parallel GPU-accelerated physics simulator (Isaac Gym), we implement challenging tasks for these robots, including regrasping, grasp-and-throw, and object reorientation. To solve these problems we introduce a decentralized Population-Based Training (PBT) algorithm that allows us to massively amplify the exploration capabilities of deep reinforcement learning. We find that this method significantly outperforms regular end-to-end learning and is able to discover robust control policies in challenging tasks. Video demonstrations of learned behaviors and the code can be found at https://sites.google.com/view/dexpbt
DeXtreme: Transfer of Agile In-hand Manipulation from Simulation to Reality
Oct 25, 2022Recent work has demonstrated the ability of deep reinforcement learning (RL) algorithms to learn complex robotic behaviours in simulation, including in the domain of multi-fingered manipulation. However, such models can be challenging to transfer to the real world due to the gap between simulation and reality. In this paper, we present our techniques to train a) a policy that can perform robust dexterous manipulation on an anthropomorphic robot hand and b) a robust pose estimator suitable for providing reliable real-time information on the state of the object being manipulated. Our policies are trained to adapt to a wide range of conditions in simulation. Consequently, our vision-based policies significantly outperform the best vision policies in the literature on the same reorientation task and are competitive with policies that are given privileged state information via motion capture systems. Our work reaffirms the possibilities of sim-to-real transfer for dexterous manipulation in diverse kinds of hardware and simulator setups, and in our case, with the Allegro Hand and Isaac Gym GPU-based simulation. Furthermore, it opens up possibilities for researchers to achieve such results with commonly-available, affordable robot hands and cameras. Videos of the resulting policy and supplementary information, including experiments and demos, can be found at \url{https://dextreme.org/}
A Robot Cluster for Reproducible Research in Dexterous Manipulation
Sep 22, 2021

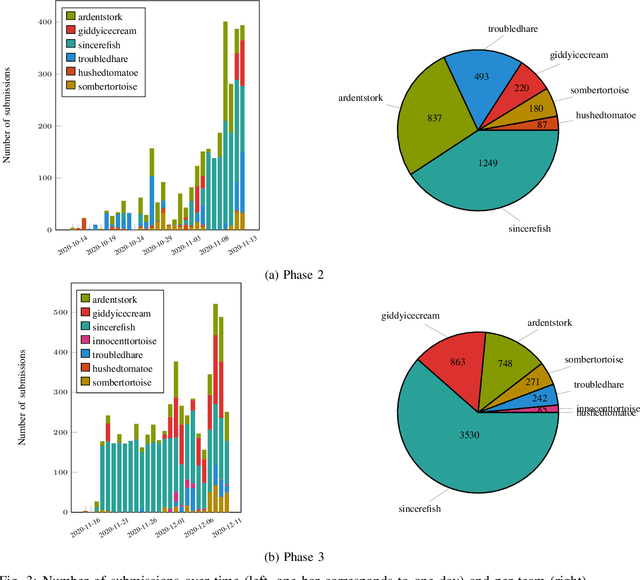
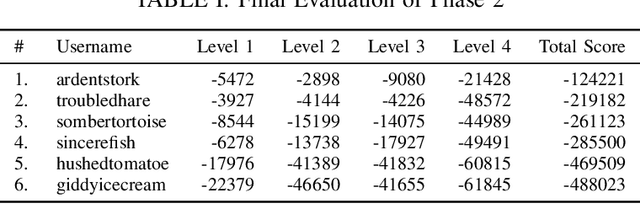
Dexterous manipulation remains an open problem in robotics. To coordinate efforts of the research community towards tackling this problem, we propose a shared benchmark. We designed and built robotic platforms that are hosted at the MPI-IS and can be accessed remotely. Each platform consists of three robotic fingers that are capable of dexterous object manipulation. Users are able to control the platforms remotely by submitting code that is executed automatically, akin to a computational cluster. Using this setup, i) we host robotics competitions, where teams from anywhere in the world access our platforms to tackle challenging tasks, ii) we publish the datasets collected during these competitions (consisting of hundreds of robot hours), and iii) we give researchers access to these platforms for their own projects.