 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
Parkour in the Wild: Learning a General and Extensible Agile Locomotion Policy Using Multi-expert Distillation and RL Fine-tuning
May 16, 2025


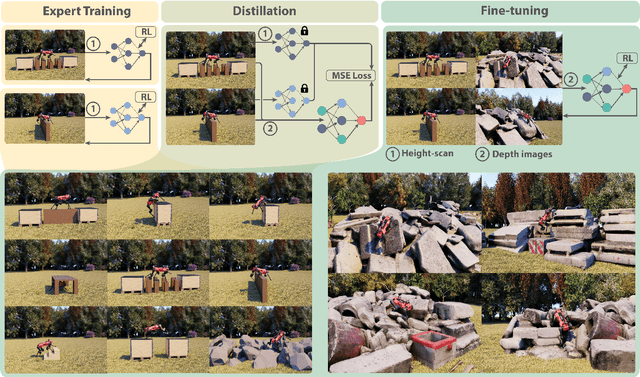
Legged robots are well-suited for navigating terrains inaccessible to wheeled robots, making them ideal for applications in search and rescue or space exploration. However, current control methods often struggle to generalize across diverse, unstructured environments. This paper introduces a novel framework for agile locomotion of legged robots by combining multi-expert distillation with reinforcement learning (RL) fine-tuning to achieve robust generalization. Initially, terrain-specific expert policies are trained to develop specialized locomotion skills. These policies are then distilled into a unified foundation policy via the DAgger algorithm. The distilled policy is subsequently fine-tuned using RL on a broader terrain set, including real-world 3D scans. The framework allows further adaptation to new terrains through repeated fine-tuning. The proposed policy leverages depth images as exteroceptive inputs, enabling robust navigation across diverse, unstructured terrains. Experimental results demonstrate significant performance improvements over existing methods in synthesizing multi-terrain skills into a single controller. Deployment on the ANYmal D robot validates the policy's ability to navigate complex environments with agility and robustness, setting a new benchmark for legged robot locomotion.
Symmetry Considerations for Learning Task Symmetric Robot Policies
Mar 07, 2024



Symmetry is a fundamental aspect of many real-world robotic tasks. However, current deep reinforcement learning (DRL) approaches can seldom harness and exploit symmetry effectively. Often, the learned behaviors fail to achieve the desired transformation invariances and suffer from motion artifacts. For instance, a quadruped may exhibit different gaits when commanded to move forward or backward, even though it is symmetrical about its torso. This issue becomes further pronounced in high-dimensional or complex environments, where DRL methods are prone to local optima and fail to explore regions of the state space equally. Past methods on encouraging symmetry for robotic tasks have studied this topic mainly in a single-task setting, where symmetry usually refers to symmetry in the motion, such as the gait patterns. In this paper, we revisit this topic for goal-conditioned tasks in robotics, where symmetry lies mainly in task execution and not necessarily in the learned motions themselves. In particular, we investigate two approaches to incorporate symmetry invariance into DRL -- data augmentation and mirror loss function. We provide a theoretical foundation for using augmented samples in an on-policy setting. Based on this, we show that the corresponding approach achieves faster convergence and improves the learned behaviors in various challenging robotic tasks, from climbing boxes with a quadruped to dexterous manipulation.
SpaceHopper: A Small-Scale Legged Robot for Exploring Low-Gravity Celestial Bodies
Mar 05, 2024



We present SpaceHopper, a three-legged, small-scale robot designed for future mobile exploration of asteroids and moons. The robot weighs 5.2kg and has a body size of 245mm while using space-qualifiable components. Furthermore, SpaceHopper's design and controls make it well-adapted for investigating dynamic locomotion modes with extended flight-phases. Instead of gyroscopes or fly-wheels, the system uses its three legs to reorient the body during flight in preparation for landing. We control the leg motion for reorientation using Deep Reinforcement Learning policies. In a simulation of Ceres' gravity (0.029g), the robot can reliably jump to commanded positions up to 6m away. Our real-world experiments show that SpaceHopper can successfully reorient to a safe landing orientation within 9.7 degree inside a rotational gimbal and jump in a counterweight setup in Earth's gravity. Overall, we consider SpaceHopper an important step towards controlled jumping locomotion in low-gravity environments.
Learning Agile Locomotion on Risky Terrains
Nov 17, 2023



Quadruped robots have shown remarkable mobility on various terrains through reinforcement learning. Yet, in the presence of sparse footholds and risky terrains such as stepping stones and balance beams, which require precise foot placement to avoid falls, model-based approaches are often used. In this paper, we show that end-to-end reinforcement learning can also enable the robot to traverse risky terrains with dynamic motions. To this end, our approach involves training a generalist policy for agile locomotion on disorderly and sparse stepping stones before transferring its reusable knowledge to various more challenging terrains by finetuning specialist policies from it. Given that the robot needs to rapidly adapt its velocity on these terrains, we formulate the task as a navigation task instead of the commonly used velocity tracking which constrains the robot's behavior and propose an exploration strategy to overcome sparse rewards and achieve high robustness. We validate our proposed method through simulation and real-world experiments on an ANYmal-D robot achieving peak forward velocity of >= 2.5 m/s on sparse stepping stones and narrow balance beams. Video: youtu.be/Z5X0J8OH6z4
Resilient Legged Local Navigation: Learning to Traverse with Compromised Perception End-to-End
Oct 05, 2023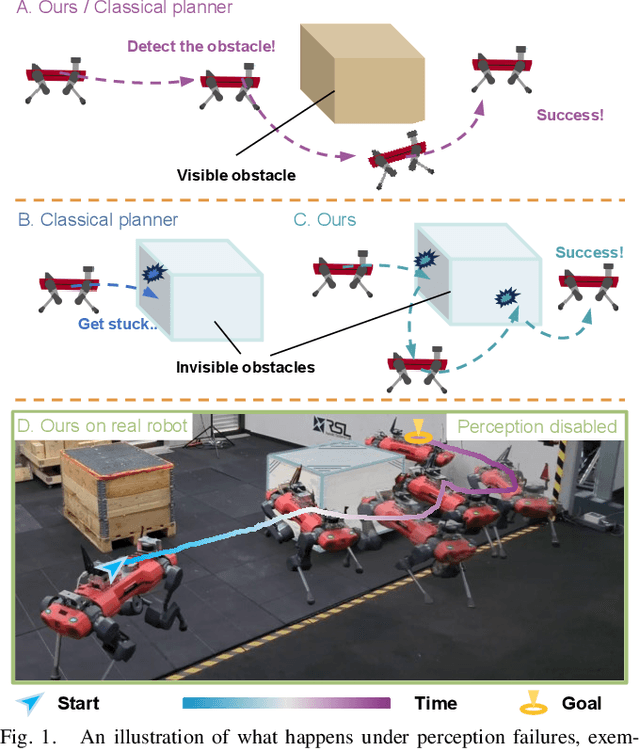

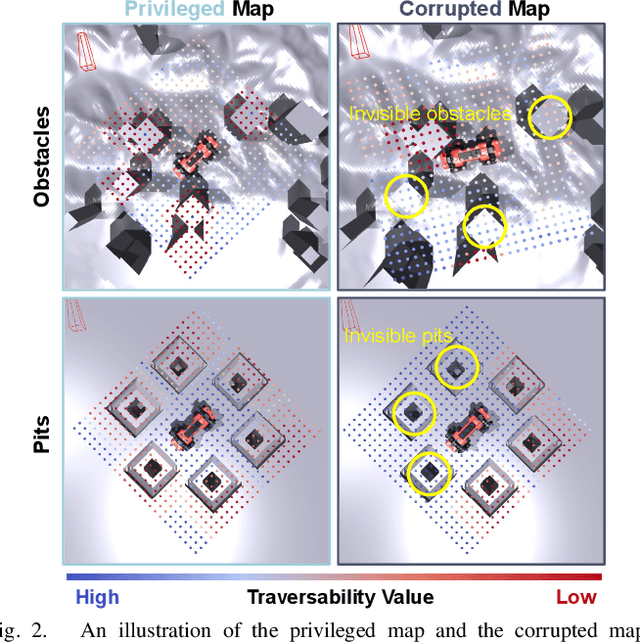

Autonomous robots must navigate reliably in unknown environments even under compromised exteroceptive perception, or perception failures. Such failures often occur when harsh environments lead to degraded sensing, or when the perception algorithm misinterprets the scene due to limited generalization. In this paper, we model perception failures as invisible obstacles and pits, and train a reinforcement learning (RL) based local navigation policy to guide our legged robot. Unlike previous works relying on heuristics and anomaly detection to update navigational information, we train our navigation policy to reconstruct the environment information in the latent space from corrupted perception and react to perception failures end-to-end. To this end, we incorporate both proprioception and exteroception into our policy inputs, thereby enabling the policy to sense collisions on different body parts and pits, prompting corresponding reactions. We validate our approach in simulation and on the real quadruped robot ANYmal running in real-time (<10 ms CPU inference). In a quantitative comparison with existing heuristic-based locally reactive planners, our policy increases the success rate over 30% when facing perception failures. Project Page: https://bit.ly/45NBTuh.
ANYmal Parkour: Learning Agile Navigation for Quadrupedal Robots
Jun 26, 2023Performing agile navigation with four-legged robots is a challenging task due to the highly dynamic motions, contacts with various parts of the robot, and the limited field of view of the perception sensors. In this paper, we propose a fully-learned approach to train such robots and conquer scenarios that are reminiscent of parkour challenges. The method involves training advanced locomotion skills for several types of obstacles, such as walking, jumping, climbing, and crouching, and then using a high-level policy to select and control those skills across the terrain. Thanks to our hierarchical formulation, the navigation policy is aware of the capabilities of each skill, and it will adapt its behavior depending on the scenario at hand. Additionally, a perception module is trained to reconstruct obstacles from highly occluded and noisy sensory data and endows the pipeline with scene understanding. Compared to previous attempts, our method can plan a path for challenging scenarios without expert demonstration, offline computation, a priori knowledge of the environment, or taking contacts explicitly into account. While these modules are trained from simulated data only, our real-world experiments demonstrate successful transfer on hardware, where the robot navigates and crosses consecutive challenging obstacles with speeds of up to two meters per second. The supplementary video can be found on the project website: https://sites.google.com/leggedrobotics.com/agile-navigation
ORBIT: A Unified Simulation Framework for Interactive Robot Learning Environments
Jan 10, 2023



We present ORBIT, a unified and modular framework for robot learning powered by NVIDIA Isaac Sim. It offers a modular design to easily and efficiently create robotic environments with photo-realistic scenes and fast and accurate rigid and deformable body simulation. With ORBIT, we provide a suite of benchmark tasks of varying difficulty -- from single-stage cabinet opening and cloth folding to multi-stage tasks such as room reorganization. To support working with diverse observations and action spaces, we include fixed-arm and mobile manipulators with different physically-based sensors and motion generators. ORBIT allows training reinforcement learning policies and collecting large demonstration datasets from hand-crafted or expert solutions in a matter of minutes by leveraging GPU-based parallelization. In summary, we offer an open-sourced framework that readily comes with 16 robotic platforms, 4 sensor modalities, 10 motion generators, more than 20 benchmark tasks, and wrappers to 4 learning libraries. With this framework, we aim to support various research areas, including representation learning, reinforcement learning, imitation learning, and task and motion planning. We hope it helps establish interdisciplinary collaborations in these communities, and its modularity makes it easily extensible for more tasks and applications in the future. For videos, documentation, and code: https://isaac-orbit.github.io/.
Advanced Skills by Learning Locomotion and Local Navigation End-to-End
Sep 26, 2022


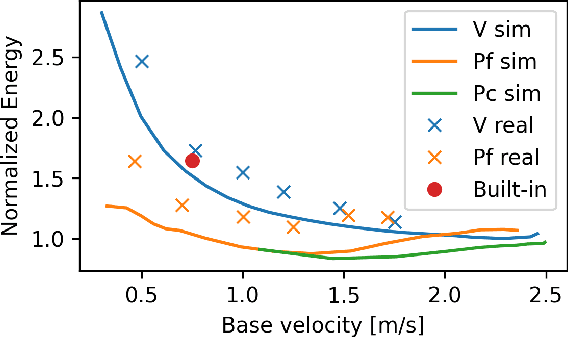
The common approach for local navigation on challenging environments with legged robots requires path planning, path following and locomotion, which usually requires a locomotion control policy that accurately tracks a commanded velocity. However, by breaking down the navigation problem into these sub-tasks, we limit the robot's capabilities since the individual tasks do not consider the full solution space. In this work, we propose to solve the complete problem by training an end-to-end policy with deep reinforcement learning. Instead of continuously tracking a precomputed path, the robot needs to reach a target position within a provided time. The task's success is only evaluated at the end of an episode, meaning that the policy does not need to reach the target as fast as possible. It is free to select its path and the locomotion gait. Training a policy in this way opens up a larger set of possible solutions, which allows the robot to learn more complex behaviors. We compare our approach to velocity tracking and additionally show that the time dependence of the task reward is critical to successfully learn these new behaviors. Finally, we demonstrate the successful deployment of policies on a real quadrupedal robot. The robot is able to cross challenging terrains, which were not possible previously, while using a more energy-efficient gait and achieving a higher success rate.
Neural Scene Representation for Locomotion on Structured Terrain
Jun 16, 2022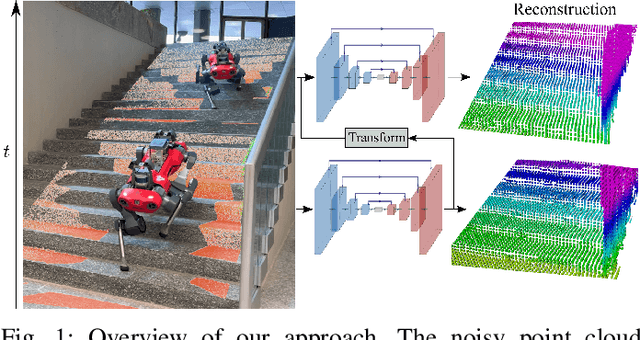
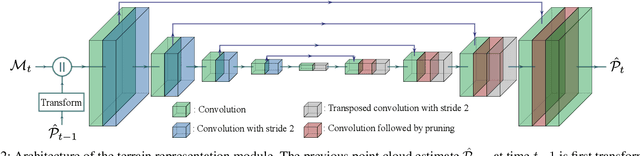

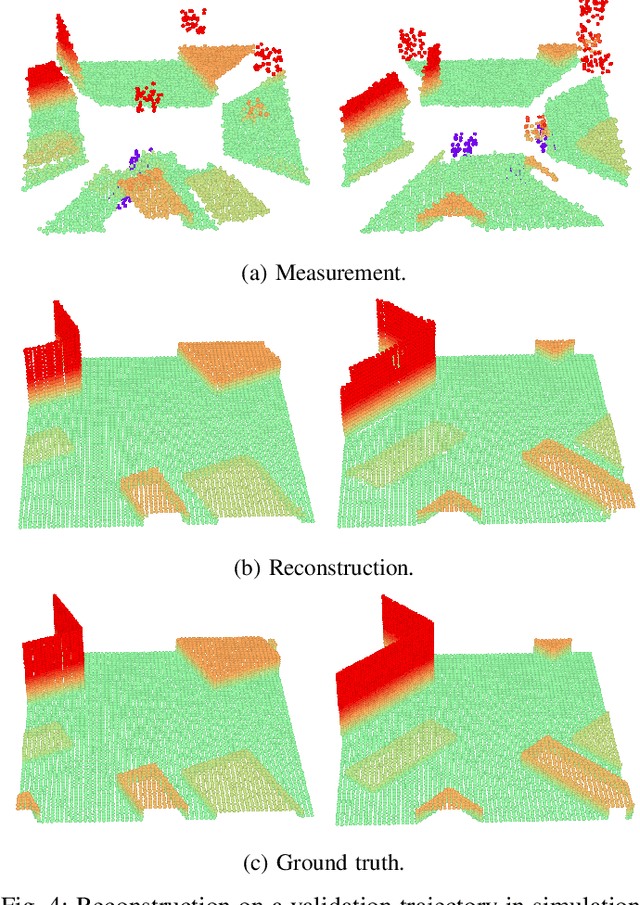
We propose a learning-based method to reconstruct the local terrain for locomotion with a mobile robot traversing urban environments. Using a stream of depth measurements from the onboard cameras and the robot's trajectory, the algorithm estimates the topography in the robot's vicinity. The raw measurements from these cameras are noisy and only provide partial and occluded observations that in many cases do not show the terrain the robot stands on. Therefore, we propose a 3D reconstruction model that faithfully reconstructs the scene, despite the noisy measurements and large amounts of missing data coming from the blind spots of the camera arrangement. The model consists of a 4D fully convolutional network on point clouds that learns the geometric priors to complete the scene from the context and an auto-regressive feedback to leverage spatio-temporal consistency and use evidence from the past. The network can be solely trained with synthetic data, and due to extensive augmentation, it is robust in the real world, as shown in the validation on a quadrupedal robot, ANYmal, traversing challenging settings. We run the pipeline on the robot's onboard low-power computer using an efficient sparse tensor implementation and show that the proposed method outperforms classical map representations.