 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Robust Autonomous Navigation and Locomotion for Wheeled-Legged Robots
May 03, 2024Autonomous wheeled-legged robots have the potential to transform logistics systems, improving operational efficiency and adaptability in urban environments. Navigating urban environments, however, poses unique challenges for robots, necessitating innovative solutions for locomotion and navigation. These challenges include the need for adaptive locomotion across varied terrains and the ability to navigate efficiently around complex dynamic obstacles. This work introduces a fully integrated system comprising adaptive locomotion control, mobility-aware local navigation planning, and large-scale path planning within the city. Using model-free reinforcement learning (RL) techniques and privileged learning, we develop a versatile locomotion controller. This controller achieves efficient and robust locomotion over various rough terrains, facilitated by smooth transitions between walking and driving modes. It is tightly integrated with a learned navigation controller through a hierarchical RL framework, enabling effective navigation through challenging terrain and various obstacles at high speed. Our controllers are integrated into a large-scale urban navigation system and validated by autonomous, kilometer-scale navigation missions conducted in Zurich, Switzerland, and Seville, Spain. These missions demonstrate the system's robustness and adaptability, underscoring the importance of integrated control systems in achieving seamless navigation in complex environments. Our findings support the feasibility of wheeled-legged robots and hierarchical RL for autonomous navigation, with implications for last-mile delivery and beyond.
Solving Multi-Entity Robotic Problems Using Permutation Invariant Neural Networks
Feb 28, 2024Challenges in real-world robotic applications often stem from managing multiple, dynamically varying entities such as neighboring robots, manipulable objects, and navigation goals. Existing multi-agent control strategies face scalability limitations, struggling to handle arbitrary numbers of entities. Additionally, they often rely on engineered heuristics for assigning entities among agents. We propose a data driven approach to address these limitations by introducing a decentralized control system using neural network policies trained in simulation. Leveraging permutation invariant neural network architectures and model-free reinforcement learning, our approach allows control agents to autonomously determine the relative importance of different entities without being biased by ordering or limited by a fixed capacity. We validate our approach through both simulations and real-world experiments involving multiple wheeled-legged quadrupedal robots, demonstrating their collaborative control capabilities. We prove the effectiveness of our architectural choice through experiments with three exemplary multi-entity problems. Our analysis underscores the pivotal role of the end-to-end trained permutation invariant encoders in achieving scalability and improving the task performance in multi-object manipulation or multi-goal navigation problems. The adaptability of our policy is further evidenced by its ability to manage varying numbers of entities in a zero-shot manner, showcasing near-optimal autonomous task distribution and collision avoidance behaviors.
Evaluation of Constrained Reinforcement Learning Algorithms for Legged Locomotion
Sep 27, 2023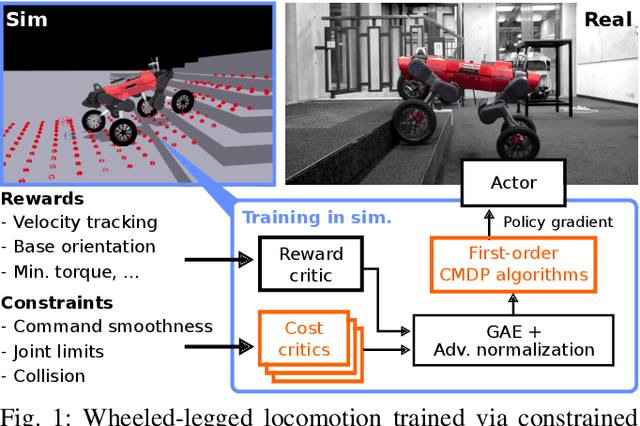
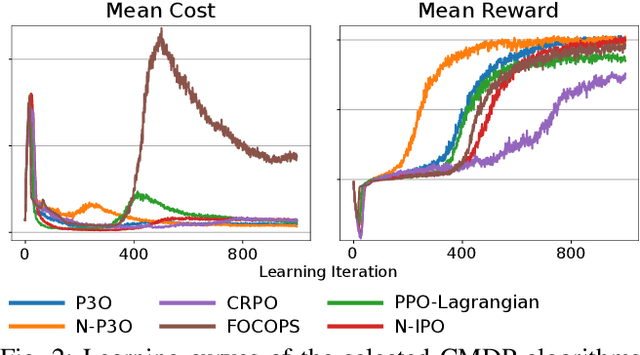
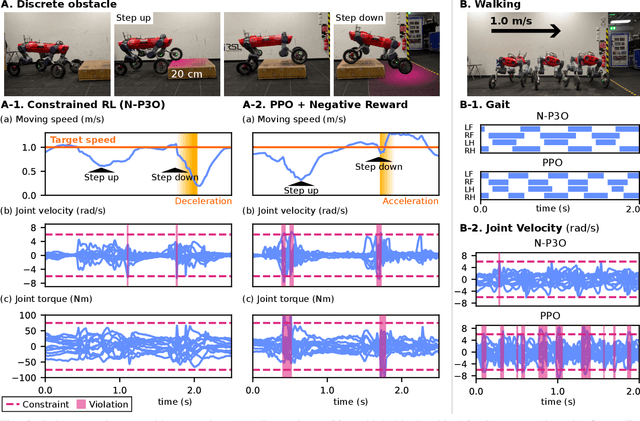
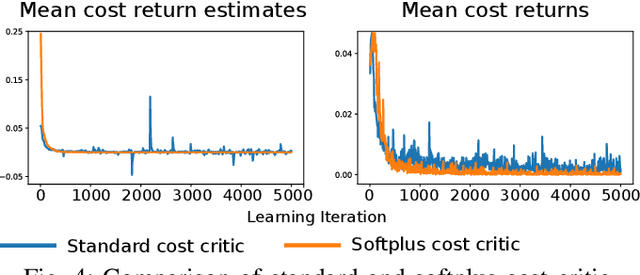
Shifting from traditional control strategies to Deep Reinforcement Learning (RL) for legged robots poses inherent challenges, especially when addressing real-world physical constraints during training. While high-fidelity simulations provide significant benefits, they often bypass these essential physical limitations. In this paper, we experiment with the Constrained Markov Decision Process (CMDP) framework instead of the conventional unconstrained RL for robotic applications. We perform a comparative study of different constrained policy optimization algorithms to identify suitable methods for practical implementation. Our robot experiments demonstrate the critical role of incorporating physical constraints, yielding successful sim-to-real transfers, and reducing operational errors on physical systems. The CMDP formulation streamlines the training process by separately handling constraints from rewards. Our findings underscore the potential of constrained RL for the effective development and deployment of learned controllers in robotics.
Advanced Skills by Learning Locomotion and Local Navigation End-to-End
Sep 26, 2022


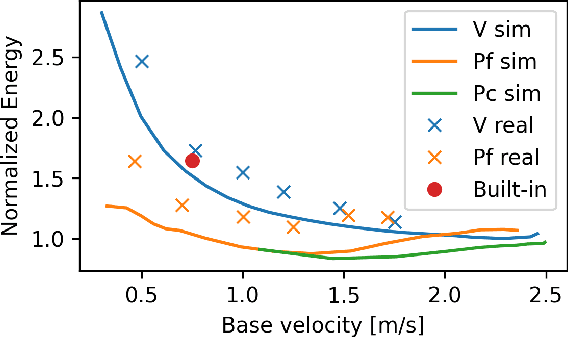
The common approach for local navigation on challenging environments with legged robots requires path planning, path following and locomotion, which usually requires a locomotion control policy that accurately tracks a commanded velocity. However, by breaking down the navigation problem into these sub-tasks, we limit the robot's capabilities since the individual tasks do not consider the full solution space. In this work, we propose to solve the complete problem by training an end-to-end policy with deep reinforcement learning. Instead of continuously tracking a precomputed path, the robot needs to reach a target position within a provided time. The task's success is only evaluated at the end of an episode, meaning that the policy does not need to reach the target as fast as possible. It is free to select its path and the locomotion gait. Training a policy in this way opens up a larger set of possible solutions, which allows the robot to learn more complex behaviors. We compare our approach to velocity tracking and additionally show that the time dependence of the task reward is critical to successfully learn these new behaviors. Finally, we demonstrate the successful deployment of policies on a real quadrupedal robot. The robot is able to cross challenging terrains, which were not possible previously, while using a more energy-efficient gait and achieving a higher success rate.
Self-Supervised Traversability Prediction by Learning to Reconstruct Safe Terrain
Aug 02, 2022
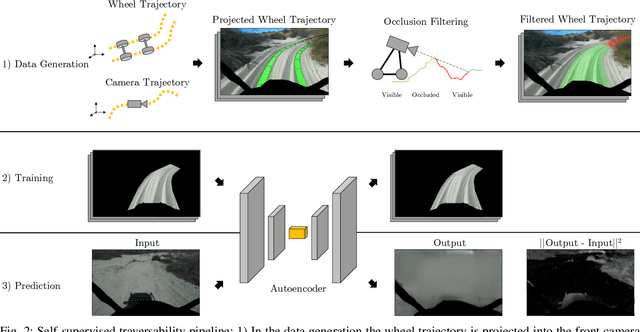


Navigating off-road with a fast autonomous vehicle depends on a robust perception system that differentiates traversable from non-traversable terrain. Typically, this depends on a semantic understanding which is based on supervised learning from images annotated by a human expert. This requires a significant investment in human time, assumes correct expert classification, and small details can lead to misclassification. To address these challenges, we propose a method for predicting high- and low-risk terrains from only past vehicle experience in a self-supervised fashion. First, we develop a tool that projects the vehicle trajectory into the front camera image. Second, occlusions in the 3D representation of the terrain are filtered out. Third, an autoencoder trained on masked vehicle trajectory regions identifies low- and high-risk terrains based on the reconstruction error. We evaluated our approach with two models and different bottleneck sizes with two different training and testing sites with a fourwheeled off-road vehicle. Comparison with two independent test sets of semantic labels from similar terrain as training sites demonstrates the ability to separate the ground as low-risk and the vegetation as high-risk with 81.1% and 85.1% accuracy.
Design and Motion Planning for a Reconfigurable Robotic Base
Jul 04, 2022
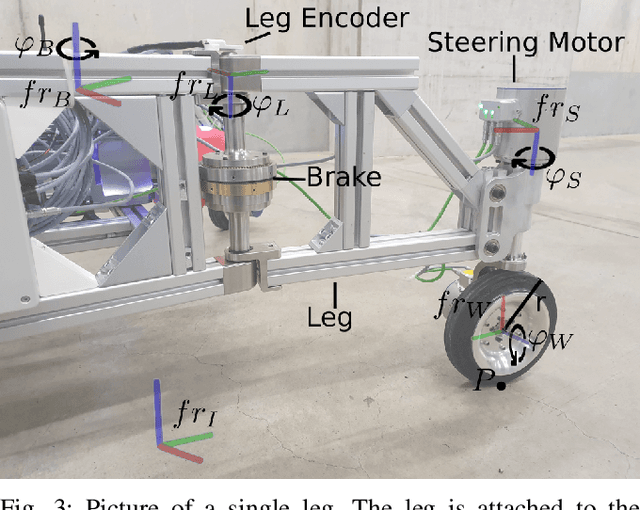

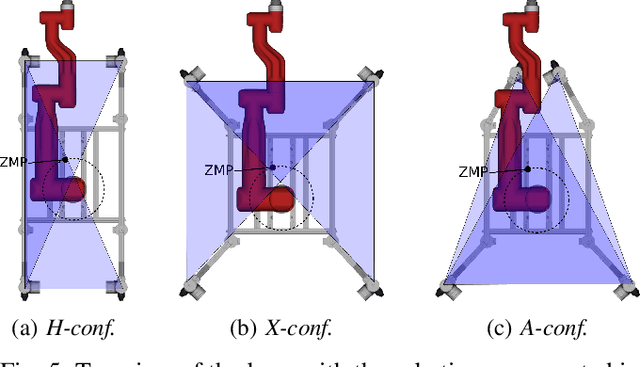
A robotic platform for mobile manipulation needs to satisfy two contradicting requirements for many real-world applications: A compact base is required to navigate through cluttered indoor environments, while the support needs to be large enough to prevent tumbling or tip over, especially during fast manipulation operations with heavy payloads or forceful interaction with the environment. This paper proposes a novel robot design that fulfills both requirements through a versatile footprint. It can reconfigure its footprint to a narrow configuration when navigating through tight spaces and to a wide stance when manipulating heavy objects. Furthermore, its triangular configuration allows for high-precision tasks on uneven ground by preventing support switches. A model predictive control strategy is presented that unifies planning and control for simultaneous navigation, reconfiguration, and manipulation. It converts task-space goals into whole-body motion plans for the new robot. The proposed design has been tested extensively with a hardware prototype. The footprint reconfiguration allows to almost completely remove manipulation-induced vibrations. The control strategy proves effective in both lab experiment and during a real-world construction task.
Advanced Skills through Multiple Adversarial Motion Priors in Reinforcement Learning
Mar 23, 2022



In recent years, reinforcement learning (RL) has shown outstanding performance for locomotion control of highly articulated robotic systems. Such approaches typically involve tedious reward function tuning to achieve the desired motion style. Imitation learning approaches such as adversarial motion priors aim to reduce this problem by encouraging a pre-defined motion style. In this work, we present an approach to augment the concept of adversarial motion prior-based RL to allow for multiple, discretely switchable styles. We show that multiple styles and skills can be learned simultaneously without notable performance differences, even in combination with motion data-free skills. Our approach is validated in several real-world experiments with a wheeled-legged quadruped robot showing skills learned from existing RL controllers and trajectory optimization, such as ducking and walking, and novel skills such as switching between a quadrupedal and humanoid configuration. For the latter skill, the robot is required to stand up, navigate on two wheels, and sit down. Instead of tuning the sit-down motion, we verify that a reverse playback of the stand-up movement helps the robot discover feasible sit-down behaviors and avoids tedious reward function tuning.
CERBERUS: Autonomous Legged and Aerial Robotic Exploration in the Tunnel and Urban Circuits of the DARPA Subterranean Challenge
Jan 18, 2022

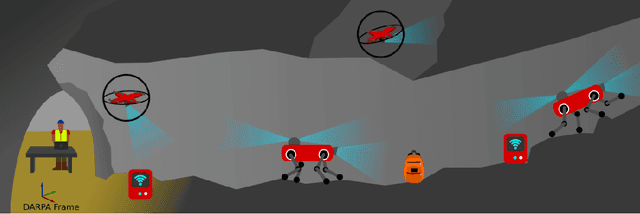

Autonomous exploration of subterranean environments constitutes a major frontier for robotic systems as underground settings present key challenges that can render robot autonomy hard to achieve. This has motivated the DARPA Subterranean Challenge, where teams of robots search for objects of interest in various underground environments. In response, the CERBERUS system-of-systems is presented as a unified strategy towards subterranean exploration using legged and flying robots. As primary robots, ANYmal quadruped systems are deployed considering their endurance and potential to traverse challenging terrain. For aerial robots, both conventional and collision-tolerant multirotors are utilized to explore spaces too narrow or otherwise unreachable by ground systems. Anticipating degraded sensing conditions, a complementary multi-modal sensor fusion approach utilizing camera, LiDAR, and inertial data for resilient robot pose estimation is proposed. Individual robot pose estimates are refined by a centralized multi-robot map optimization approach to improve the reported location accuracy of detected objects of interest in the DARPA-defined coordinate frame. Furthermore, a unified exploration path planning policy is presented to facilitate the autonomous operation of both legged and aerial robots in complex underground networks. Finally, to enable communication between the robots and the base station, CERBERUS utilizes a ground rover with a high-gain antenna and an optical fiber connection to the base station, alongside breadcrumbing of wireless nodes by our legged robots. We report results from the CERBERUS system-of-systems deployment at the DARPA Subterranean Challenge Tunnel and Urban Circuits, along with the current limitations and the lessons learned for the benefit of the community.
Collision-Free MPC for Legged Robots in Static and Dynamic Scenes
Mar 25, 2021
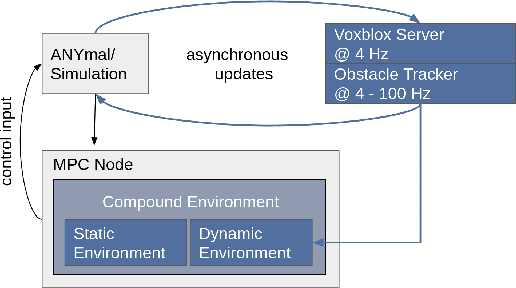
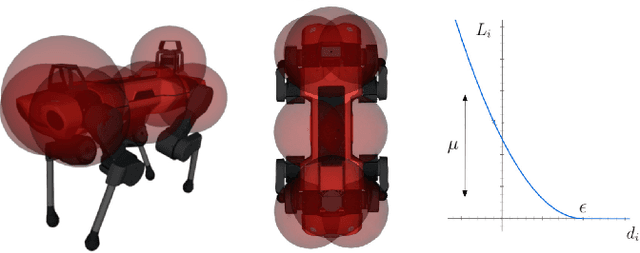
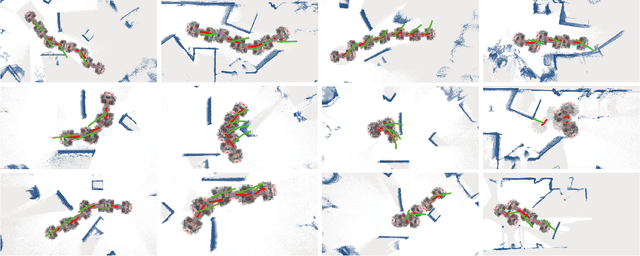
We present a model predictive controller (MPC) that automatically discovers collision-free locomotion while simultaneously taking into account the system dynamics, friction constraints, and kinematic limitations. A relaxed barrier function is added to the optimization's cost function, leading to collision avoidance behavior without increasing the problem's computational complexity. Our holistic approach does not require any heuristics and enables legged robots to find whole-body motions in the presence of static and dynamic obstacles. We use a dynamically generated euclidean signed distance field for static collision checking. Collision checking for dynamic obstacles is modeled with moving cylinders, increasing the responsiveness to fast-moving agents. Furthermore, we include a Kalman filter motion prediction for moving obstacles into our receding horizon planning, enabling the robot to anticipate possible future collisions. Our experiments demonstrate collision-free motions on a quadrupedal robot in challenging indoor environments. The robot handles complex scenes like overhanging obstacles and dynamic agents by exploring motions at the robot's dynamic and kinematic limits.
Whole-Body MPC and Online Gait Sequence Generation for Wheeled-Legged Robots
Oct 13, 2020

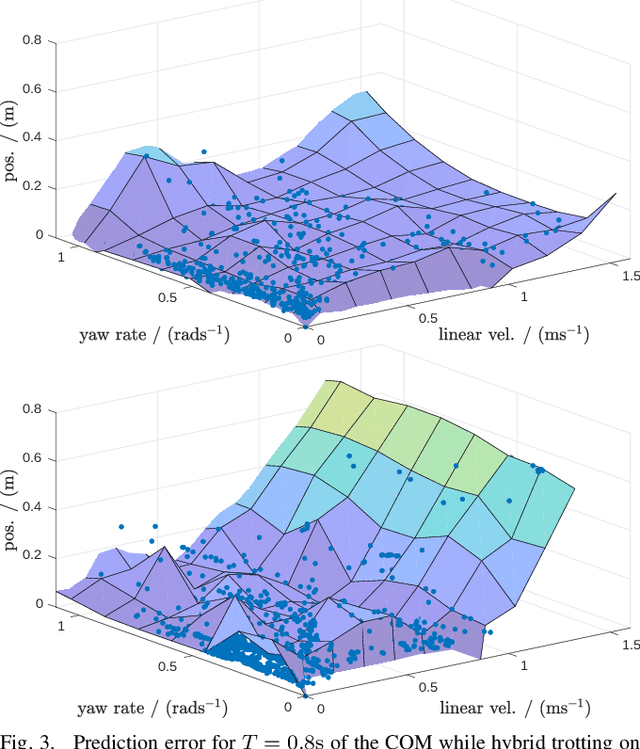
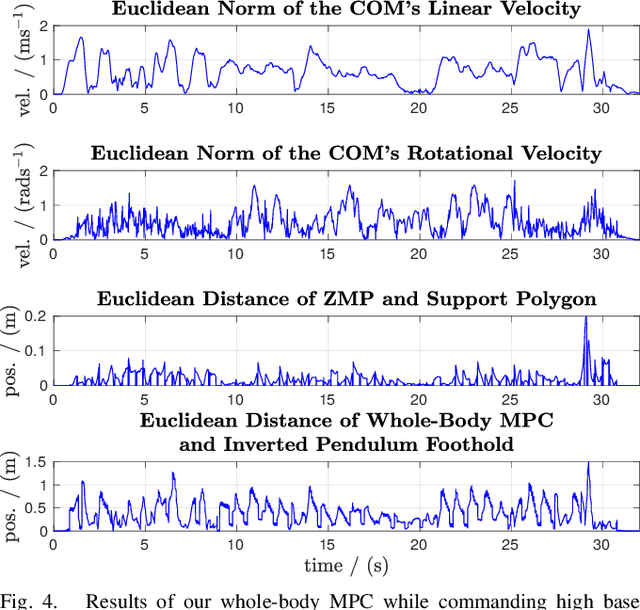
The additional degrees of freedom and missing counterparts in nature make designing locomotion capabilities for wheeled-legged robots more challenging. We propose a whole-body model predictive controller as a single task formulation that simultaneously optimizes wheel and torso motions. Due to the real-time joint velocity and ground reaction force optimization based on a kinodynamic model, our approach accurately captures the real robot's dynamics and automatically discovers complex and dynamic motions cumbersome to hand-craft through heuristics. Thanks to the single set of parameters for all behaviors, whole-body optimization makes online gait sequence adaptation possible. Aperiodic gait sequences are automatically found through kinematic leg utilities without the need for predefined contact and lift-off timings. Also, this enables us to reduce the cost of transport of wheeled-legged robots significantly. Our experiments demonstrate highly dynamic motions on a quadrupedal robot with non-steerable wheels in challenging indoor and outdoor environments. Herewith, we verify that a single task formulation is key to reveal the full potential of wheeled-legged robots.