 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Addendum to NeBula: Towards Extending TEAM CoSTAR's Solution to Larger Scale Environments
Apr 18, 2025This paper presents an appendix to the original NeBula autonomy solution developed by the TEAM CoSTAR (Collaborative SubTerranean Autonomous Robots), participating in the DARPA Subterranean Challenge. Specifically, this paper presents extensions to NeBula's hardware, software, and algorithmic components that focus on increasing the range and scale of the exploration environment. From the algorithmic perspective, we discuss the following extensions to the original NeBula framework: (i) large-scale geometric and semantic environment mapping; (ii) an adaptive positioning system; (iii) probabilistic traversability analysis and local planning; (iv) large-scale POMDP-based global motion planning and exploration behavior; (v) large-scale networking and decentralized reasoning; (vi) communication-aware mission planning; and (vii) multi-modal ground-aerial exploration solutions. We demonstrate the application and deployment of the presented systems and solutions in various large-scale underground environments, including limestone mine exploration scenarios as well as deployment in the DARPA Subterranean challenge.
Self-Supervised Traversability Prediction by Learning to Reconstruct Safe Terrain
Aug 02, 2022
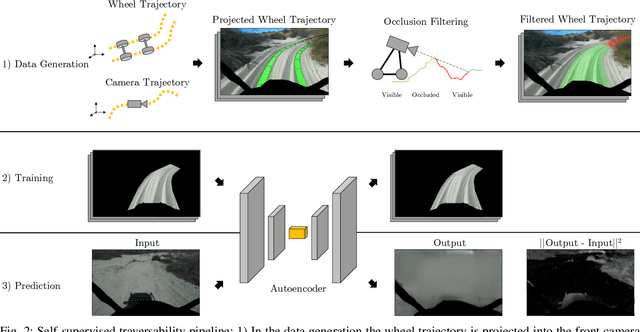


Navigating off-road with a fast autonomous vehicle depends on a robust perception system that differentiates traversable from non-traversable terrain. Typically, this depends on a semantic understanding which is based on supervised learning from images annotated by a human expert. This requires a significant investment in human time, assumes correct expert classification, and small details can lead to misclassification. To address these challenges, we propose a method for predicting high- and low-risk terrains from only past vehicle experience in a self-supervised fashion. First, we develop a tool that projects the vehicle trajectory into the front camera image. Second, occlusions in the 3D representation of the terrain are filtered out. Third, an autoencoder trained on masked vehicle trajectory regions identifies low- and high-risk terrains based on the reconstruction error. We evaluated our approach with two models and different bottleneck sizes with two different training and testing sites with a fourwheeled off-road vehicle. Comparison with two independent test sets of semantic labels from similar terrain as training sites demonstrates the ability to separate the ground as low-risk and the vegetation as high-risk with 81.1% and 85.1% accuracy.
Early Recall, Late Precision: Multi-Robot Semantic Object Mapping under Operational Constraints in Perceptually-Degraded Environments
Jun 21, 2022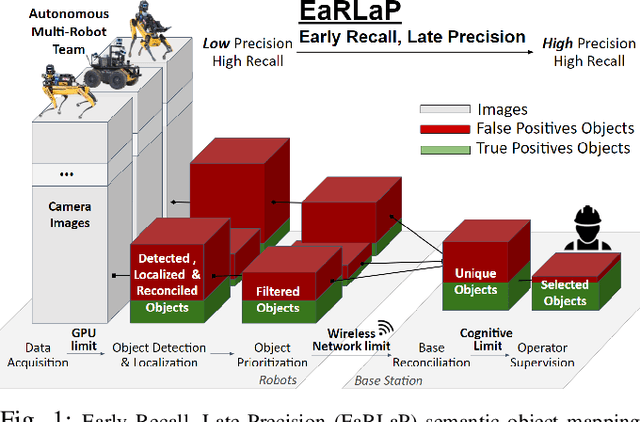
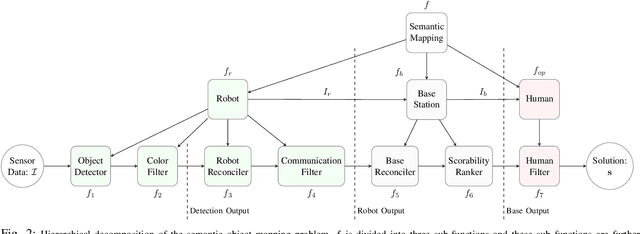
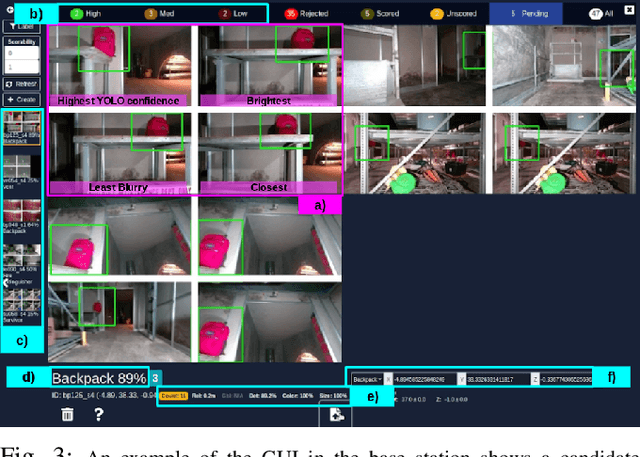
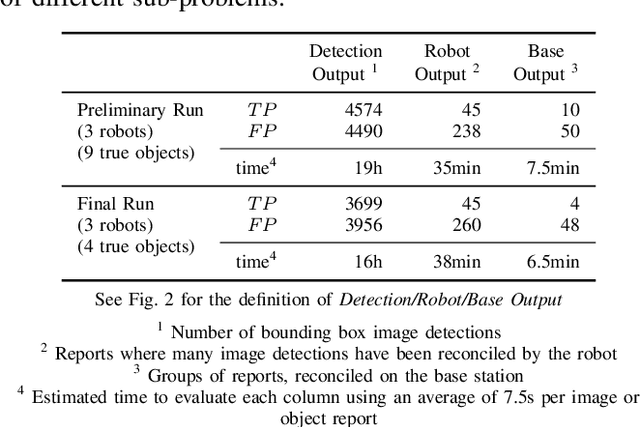
Semantic object mapping in uncertain, perceptually degraded environments during long-range multi-robot autonomous exploration tasks such as search-and-rescue is important and challenging. During such missions, high recall is desirable to avoid missing true target objects and high precision is also critical to avoid wasting valuable operational time on false positives. Given recent advancements in visual perception algorithms, the former is largely solvable autonomously, but the latter is difficult to address without the supervision of a human operator. However, operational constraints such as mission time, computational requirements, mesh network bandwidth and so on, can make the operator's task infeasible unless properly managed. We propose the Early Recall, Late Precision (EaRLaP) semantic object mapping pipeline to solve this problem. EaRLaP was used by Team CoSTAR in DARPA Subterranean Challenge, where it successfully detected all the artifacts encountered by the team of robots. We will discuss these results and performance of the EaRLaP on various datasets.
Machine Vision based Sample-Tube Localization for Mars Sample Return
Mar 17, 2021

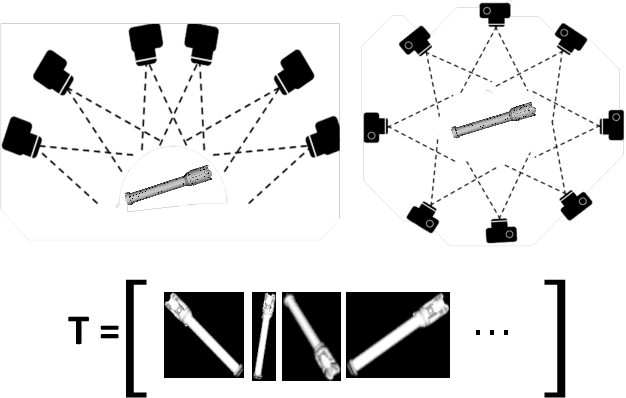
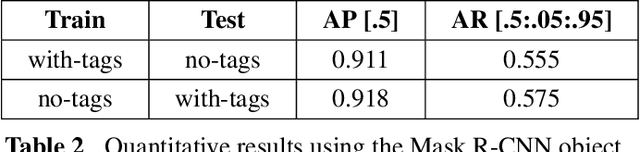
A potential Mars Sample Return (MSR) architecture is being jointly studied by NASA and ESA. As currently envisioned, the MSR campaign consists of a series of 3 missions: sample cache, fetch and return to Earth. In this paper, we focus on the fetch part of the MSR, and more specifically the problem of autonomously detecting and localizing sample tubes deposited on the Martian surface. Towards this end, we study two machine-vision based approaches: First, a geometry-driven approach based on template matching that uses hard-coded filters and a 3D shape model of the tube; and second, a data-driven approach based on convolutional neural networks (CNNs) and learned features. Furthermore, we present a large benchmark dataset of sample-tube images, collected in representative outdoor environments and annotated with ground truth segmentation masks and locations. The dataset was acquired systematically across different terrain, illumination conditions and dust-coverage; and benchmarking was performed to study the feasibility of each approach, their relative strengths and weaknesses, and robustness in the presence of adverse environmental conditions.
Rover Relocalization for Mars Sample Return by Virtual Template Synthesis and Matching
Mar 05, 2021
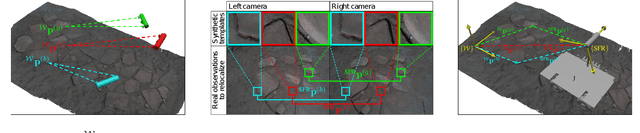

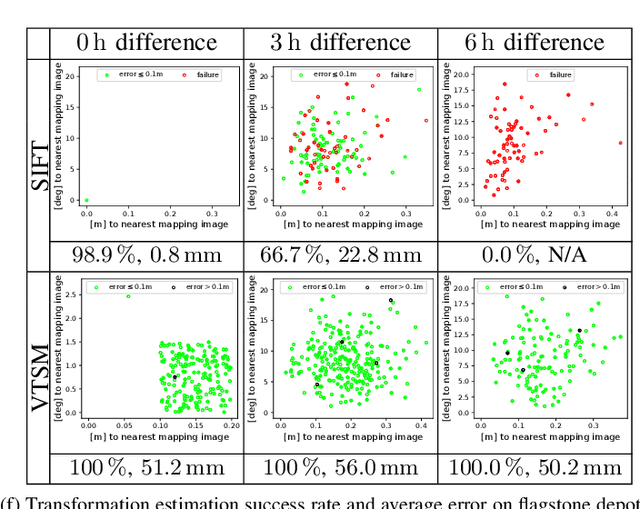
We consider the problem of rover relocalization in the context of the notional Mars Sample Return campaign. In this campaign, a rover (R1) needs to be capable of autonomously navigating and localizing itself within an area of approximately 50 x 50 m using reference images collected years earlier by another rover (R0). We propose a visual localizer that exhibits robustness to the relatively barren terrain that we expect to find in relevant areas, and to large lighting and viewpoint differences between R0 and R1. The localizer synthesizes partial renderings of a mesh built from reference R0 images and matches those to R1 images. We evaluate our method on a dataset totaling 2160 images covering the range of expected environmental conditions (terrain, lighting, approach angle). Experimental results show the effectiveness of our approach. This work informs the Mars Sample Return campaign on the choice of a site where Perseverance (R0) will place a set of sample tubes for future retrieval by another rover (R1).