 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitation from Observation With Bootstrapped Contrastive Learning
Feb 13, 2023



Imitation from observation (IfO) is a learning paradigm that consists of training autonomous agents in a Markov Decision Process (MDP) by observing expert demonstrations without access to its actions. These demonstrations could be sequences of environment states or raw visual observations of the environment. Recent work in IfO has focused on this problem in the case of observations of low-dimensional environment states, however, access to these highly-specific observations is unlikely in practice. In this paper, we adopt a challenging, but more realistic problem formulation, learning control policies that operate on a learned latent space with access only to visual demonstrations of an expert completing a task. We present BootIfOL, an IfO algorithm that aims to learn a reward function that takes an agent trajectory and compares it to an expert, providing rewards based on similarity to agent behavior and implicit goal. We consider this reward function to be a distance metric between trajectories of agent behavior and learn it via contrastive learning. The contrastive learning objective aims to closely represent expert trajectories and to distance them from non-expert trajectories. The set of non-expert trajectories used in contrastive learning is made progressively more complex by bootstrapping from roll-outs of the agent learned through RL using the current reward function. We evaluate our approach on a variety of control tasks showing that we can train effective policies using a limited number of demonstrative trajectories, greatly improving on prior approaches that consider raw observations.
An Autonomous Probing System for Collecting Measurements at Depth from Small Surface Vehicles
Oct 27, 2021

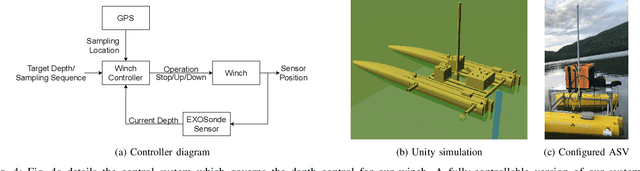
This paper presents the portable autonomous probing system (APS), a low-cost robotic design for collecting water quality measurements at targeted depths from an autonomous surface vehicle (ASV). This system fills an important but often overlooked niche in marine sampling by enabling mobile sensor observations throughout the near-surface water column without the need for advanced underwater equipment. We present a probe delivery mechanism built with commercially available components and describe the corresponding open-source simulator and winch controller. Finally, we demonstrate the system in a field deployment and discuss design trade-offs and areas for future improvement. Project details are available on https://johannah.github.io/publication/sample-at-depth our website
Rover Relocalization for Mars Sample Return by Virtual Template Synthesis and Matching
Mar 05, 2021
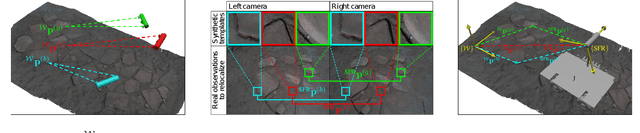

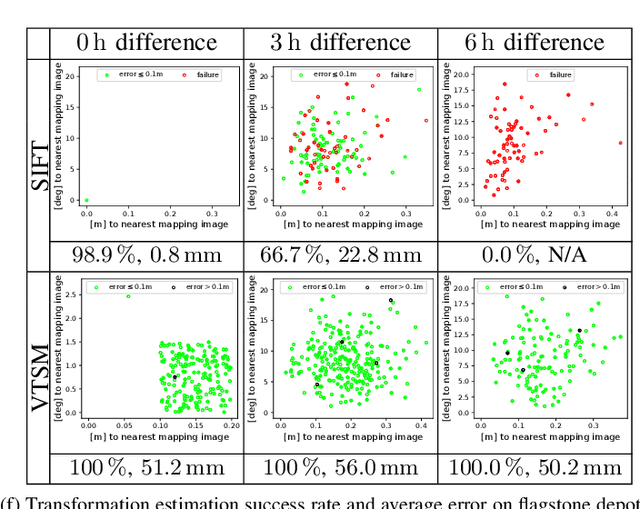
We consider the problem of rover relocalization in the context of the notional Mars Sample Return campaign. In this campaign, a rover (R1) needs to be capable of autonomously navigating and localizing itself within an area of approximately 50 x 50 m using reference images collected years earlier by another rover (R0). We propose a visual localizer that exhibits robustness to the relatively barren terrain that we expect to find in relevant areas, and to large lighting and viewpoint differences between R0 and R1. The localizer synthesizes partial renderings of a mesh built from reference R0 images and matches those to R1 images. We evaluate our method on a dataset totaling 2160 images covering the range of expected environmental conditions (terrain, lighting, approach angle). Experimental results show the effectiveness of our approach. This work informs the Mars Sample Return campaign on the choice of a site where Perseverance (R0) will place a set of sample tubes for future retrieval by another rover (R1).
Autonomous Marine Sampling Enhanced by Strategically Deployed Drifters in Marine Flow Fields
Nov 25, 2018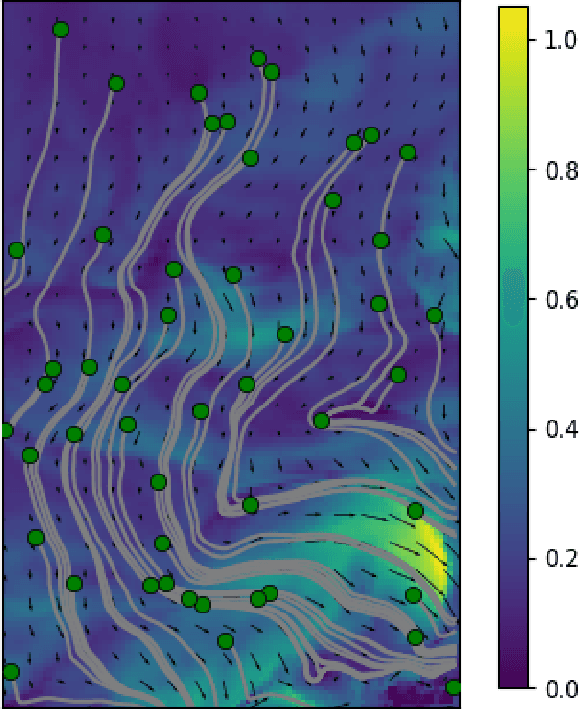
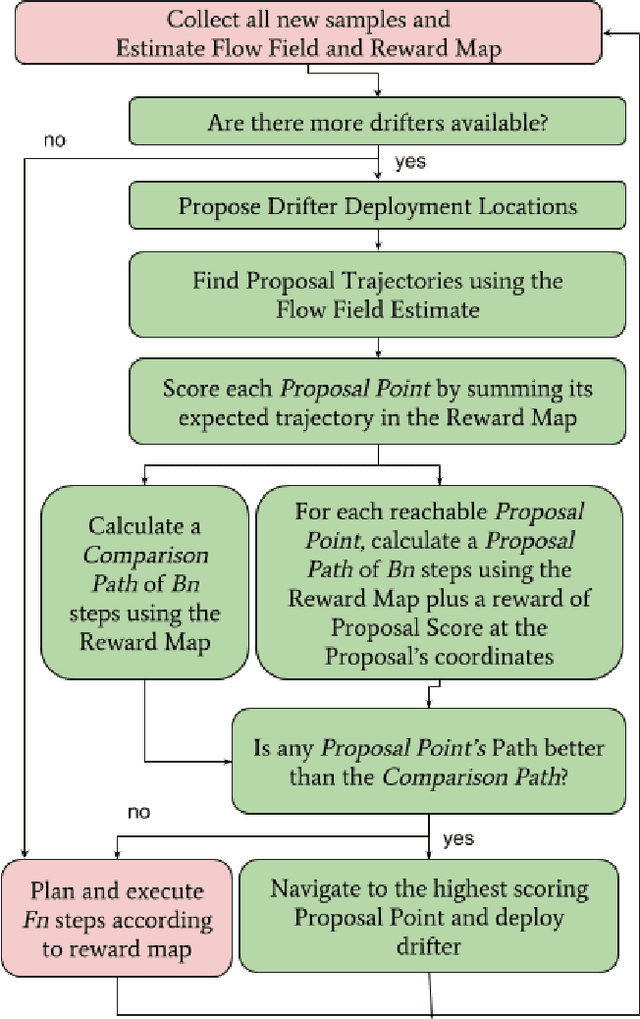

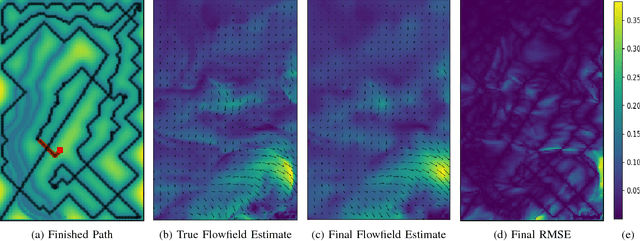
We present a transportable system for ocean observations in which a small autonomous surface vehicle (ASV) adaptively collects spatially diverse samples with aid from a team of inexpensive, passive floating sensors known as drifters. Drifters can provide an increase in spatial coverage at little cost as they are propelled about the survey area by the ambient flow field instead of with actuators. Our iterative planning approach demonstrates how we can use the ASV to strategically deploy drifters into points of the flow field for high expected information gain, while also adaptively sampling the space. In this paper, we examine the performance of this heterogeneous sensing system in simulated flow field experiments.
Planning in Dynamic Environments with Conditional Autoregressive Models
Nov 25, 2018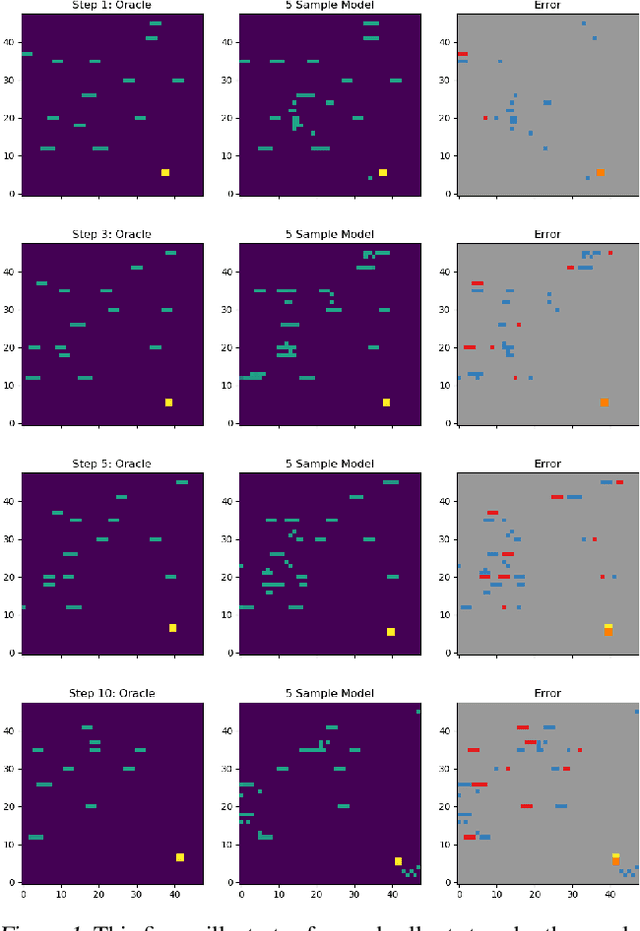
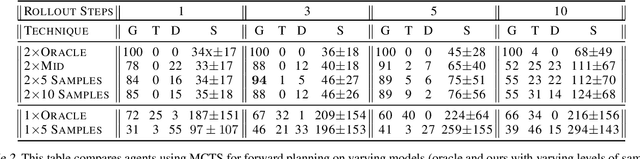
We demonstrate the use of conditional autoregressive generative models (van den Oord et al., 2016a) over a discrete latent space (van den Oord et al., 2017b) for forward planning with MCTS. In order to test this method, we introduce a new environment featuring varying difficulty levels, along with moving goals and obstacles. The combination of high-quality frame generation and classical planning approaches nearly matches true environment performance for our task, demonstrating the usefulness of this method for model-based planning in dynamic environments.
Benchmark Environments for Multitask Learning in Continuous Domains
Aug 14, 2017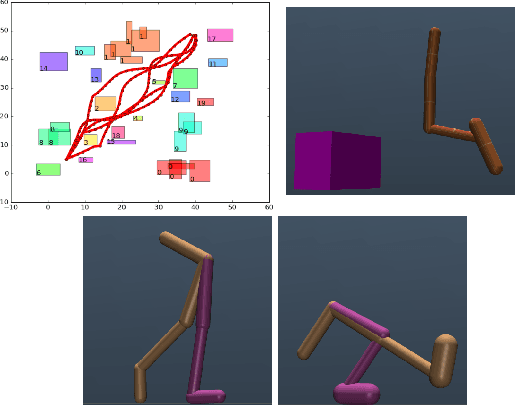
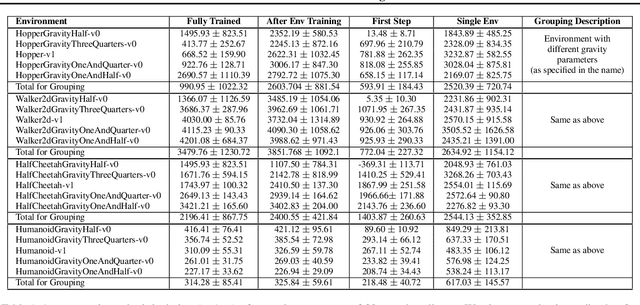

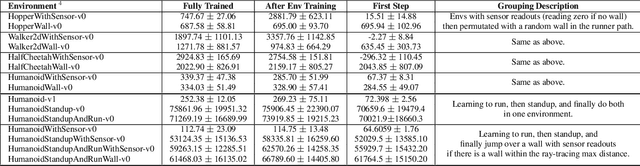
As demand drives systems to generalize to various domains and problems, the study of multitask, transfer and lifelong learning has become an increasingly important pursuit. In discrete domains, performance on the Atari game suite has emerged as the de facto benchmark for assessing multitask learning. However, in continuous domains there is a lack of agreement on standard multitask evaluation environments which makes it difficult to compare different approaches fairly. In this work, we describe a benchmark set of tasks that we have developed in an extendable framework based on OpenAI Gym. We run a simple baseline using Trust Region Policy Optimization and release the framework publicly to be expanded and used for the systematic comparison of multitask, transfer, and lifelong learning in continuous domains.