 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmark Environments for Multitask Learning in Continuous Domains
Paper and Code
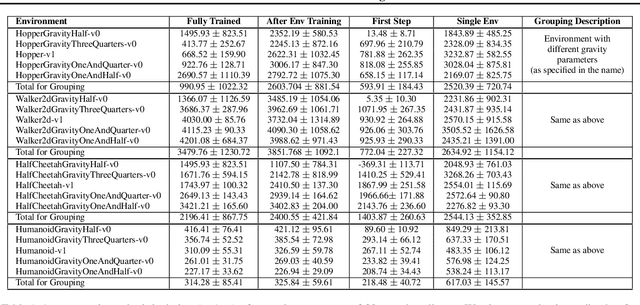

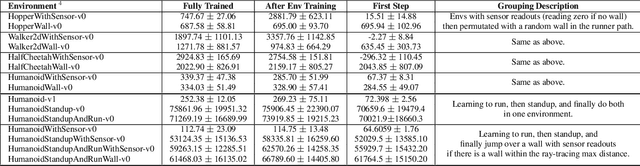
As demand drives systems to generalize to various domains and problems, the study of multitask, transfer and lifelong learning has become an increasingly important pursuit. In discrete domains, performance on the Atari game suite has emerged as the de facto benchmark for assessing multitask learning. However, in continuous domains there is a lack of agreement on standard multitask evaluation environments which makes it difficult to compare different approaches fairly. In this work, we describe a benchmark set of tasks that we have developed in an extendable framework based on OpenAI Gym. We run a simple baseline using Trust Region Policy Optimization and release the framework publicly to be expanded and used for the systematic comparison of multitask, transfer, and lifelong learning in continuous domains.