 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearest Neighbor Normalization Improves Multimodal Retrieval
Oct 31, 2024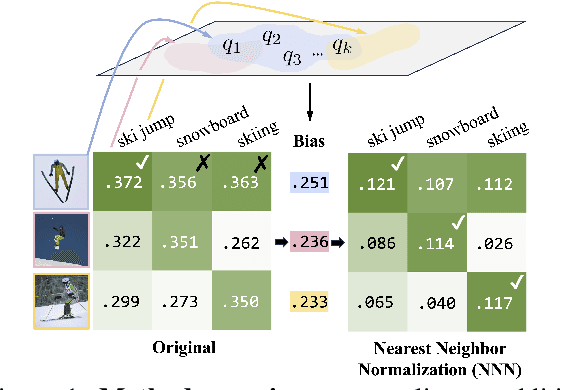



Multimodal models leverage large-scale pre-training to achieve strong but still imperfect performance on tasks such as image captioning, visual question answering, and cross-modal retrieval. In this paper, we present a simple and efficient method for correcting errors in trained contrastive image-text retrieval models with no additional training, called Nearest Neighbor Normalization (NNN). We show an improvement on retrieval metrics in both text retrieval and image retrieval for all of the contrastive models that we tested (CLIP, BLIP, ALBEF, SigLIP, BEiT) and for both of the datasets that we used (MS-COCO and Flickr30k). NNN requires a reference database, but does not require any training on this database, and can even increase the retrieval accuracy of a model after finetuning.
Improving Pretraining Data Using Perplexity Correlations
Sep 09, 2024



Quality pretraining data is often seen as the key to high-performance language models. However, progress in understanding pretraining data has been slow due to the costly pretraining runs required for data selection experiments. We present a framework that avoids these costs and selects high-quality pretraining data without any LLM training of our own. Our work is based on a simple observation: LLM losses on many pretraining texts are correlated with downstream benchmark performance, and selecting high-correlation documents is an effective pretraining data selection method. We build a new statistical framework for data selection centered around estimates of perplexity-benchmark correlations and perform data selection using a sample of 90 LLMs taken from the Open LLM Leaderboard on texts from tens of thousands of web domains. In controlled pretraining experiments at the 160M parameter scale on 8 benchmarks, our approach outperforms DSIR on every benchmark, while matching the best data selector found in DataComp-LM, a hand-engineered bigram classifier.
ColorSwap: A Color and Word Order Dataset for Multimodal Evaluation
Feb 07, 2024



This paper introduces the ColorSwap dataset, designed to assess and improve the proficiency of multimodal models in matching objects with their colors. The dataset is comprised of 2,000 unique image-caption pairs, grouped into 1,000 examples. Each example includes a caption-image pair, along with a ``color-swapped'' pair. We follow the Winoground schema: the two captions in an example have the same words, but the color words have been rearranged to modify different objects. The dataset was created through a novel blend of automated caption and image generation with humans in the loop. We evaluate image-text matching (ITM) and visual language models (VLMs) and find that even the latest ones are still not robust at this task. GPT-4V and LLaVA score 72% and 42% on our main VLM metric, although they may improve with more advanced prompting techniques. On the main ITM metric, contrastive models such as CLIP and SigLIP perform close to chance (at 12% and 30%, respectively), although the non-contrastive BLIP ITM model is stronger (87%). We also find that finetuning on fewer than 2,000 examples yields significant performance gains on this out-of-distribution word-order understanding task. The dataset is here: https://github.com/Top34051/colorswap.
I am a Strange Dataset: Metalinguistic Tests for Language Models
Jan 10, 2024



Statements involving metalinguistic self-reference ("This paper has six sections.") are prevalent in many domains. Can large language models (LLMs) handle such language? In this paper, we present "I am a Strange Dataset", a new dataset for addressing this question. There are two subtasks: generation and verification. In generation, models continue statements like "The penultimate word in this sentence is" (where a correct continuation is "is"). In verification, models judge the truth of statements like "The penultimate word in this sentence is sentence." (false). We also provide minimally different metalinguistic non-self-reference examples to complement the main dataset by probing for whether models can handle metalinguistic language at all. The dataset is hand-crafted by experts and validated by non-expert annotators. We test a variety of open-source LLMs (7B to 70B parameters) as well as closed-source LLMs through APIs. All models perform close to chance across both subtasks and even on the non-self-referential metalinguistic control data, though we find some steady improvement with model scale. GPT 4 is the only model to consistently do significantly better than chance, and it is still only in the 60% range, while our untrained human annotators score well in the 89-93% range. The dataset and evaluation toolkit are available at https://github.com/TristanThrush/i-am-a-strange-dataset.
Towards Language Models That Can See: Computer Vision Through the LENS of Natural Language
Jun 28, 2023



We propose LENS, a modular approach for tackling computer vision problems by leveraging the power of large language models (LLMs). Our system uses a language model to reason over outputs from a set of independent and highly descriptive vision modules that provide exhaustive information about an image. We evaluate the approach on pure computer vision settings such as zero- and few-shot object recognition, as well as on vision and language problems. LENS can be applied to any off-the-shelf LLM and we find that the LLMs with LENS perform highly competitively with much bigger and much more sophisticated systems, without any multimodal training whatsoever. We open-source our code at https://github.com/ContextualAI/lens and provide an interactive demo.
The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset
Mar 07, 2023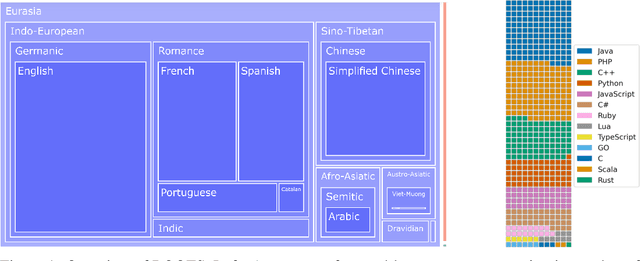


As language models grow ever larger, the need for large-scale high-quality text datasets has never been more pressing, especially in multilingual settings. The BigScience workshop, a 1-year international and multidisciplinary initiative, was formed with the goal of researching and training large language models as a values-driven undertaking, putting issues of ethics, harm, and governance in the foreground. This paper documents the data creation and curation efforts undertaken by BigScience to assemble the Responsible Open-science Open-collaboration Text Sources (ROOTS) corpus, a 1.6TB dataset spanning 59 languages that was used to train the 176-billion-parameter BigScience Large Open-science Open-access Multilingual (BLOOM) language model. We further release a large initial subset of the corpus and analyses thereof, and hope to empower large-scale monolingual and multilingual modeling projects with both the data and the processing tools, as well as stimulate research around this large multilingual corpus.
Measuring Data
Dec 09, 2022


We identify the task of measuring data to quantitatively characterize the composition of machine learning data and datasets. Similar to an object's height, width, and volume, data measurements quantify different attributes of data along common dimensions that support comparison. Several lines of research have proposed what we refer to as measurements, with differing terminology; we bring some of this work together, particularly in fields of computer vision and language, and build from it to motivate measuring data as a critical component of responsible AI development. Measuring data aids in systematically building and analyzing machine learning (ML) data towards specific goals and gaining better control of what modern ML systems will learn. We conclude with a discussion of the many avenues of future work, the limitations of data measurements, and how to leverage these measurement approaches in research and practice.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
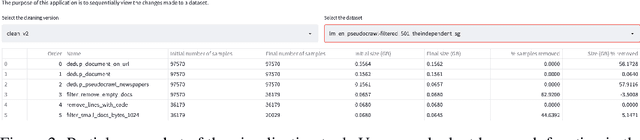
Evaluate & Evaluation on the Hub: Better Best Practices for Data and Model Measurements
Oct 06, 2022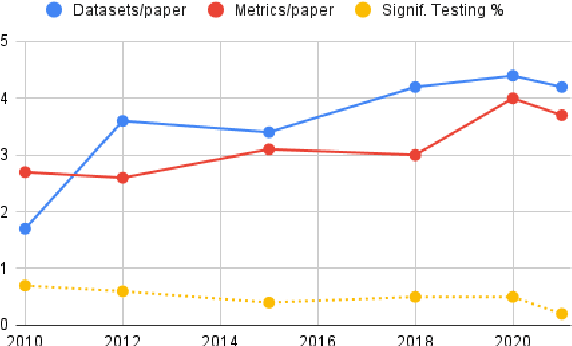
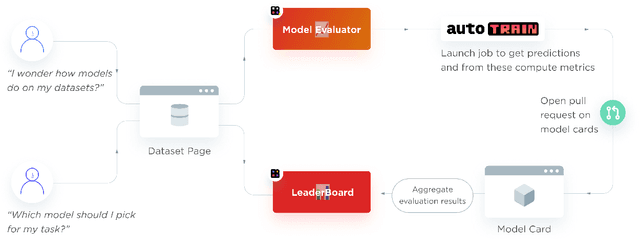
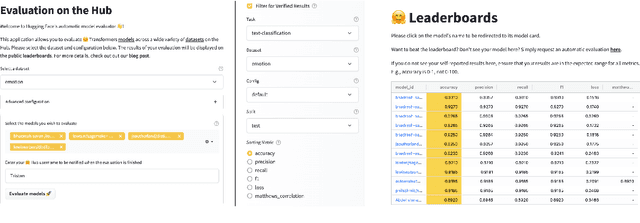
Evaluation is a key part of machine learning (ML), yet there is a lack of support and tooling to enable its informed and systematic practice. We introduce Evaluate and Evaluation on the Hub --a set of tools to facilitate the evaluation of models and datasets in ML. Evaluate is a library to support best practices for measurements, metrics, and comparisons of data and models. Its goal is to support reproducibility of evaluation, centralize and document the evaluation process, and broaden evaluation to cover more facets of model performance. It includes over 50 efficient canonical implementations for a variety of domains and scenarios, interactive documentation, and the ability to easily share implementations and outcomes. The library is available at https://github.com/huggingface/evaluate. In addition, we introduce Evaluation on the Hub, a platform that enables the large-scale evaluation of over 75,000 models and 11,000 datasets on the Hugging Face Hub, for free, at the click of a button. Evaluation on the Hub is available at https://huggingface.co/autoevaluate.
DataPerf: Benchmarks for Data-Centric AI Development
Jul 20, 2022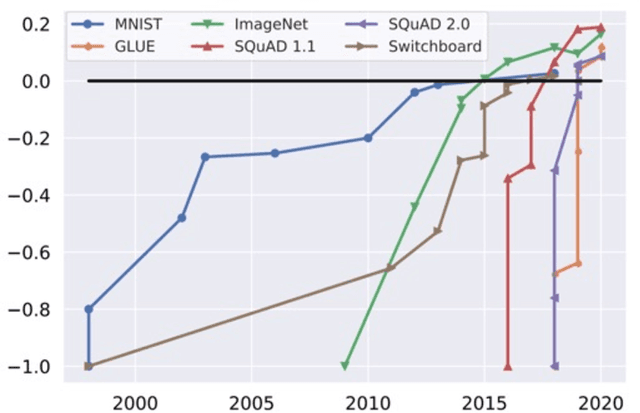
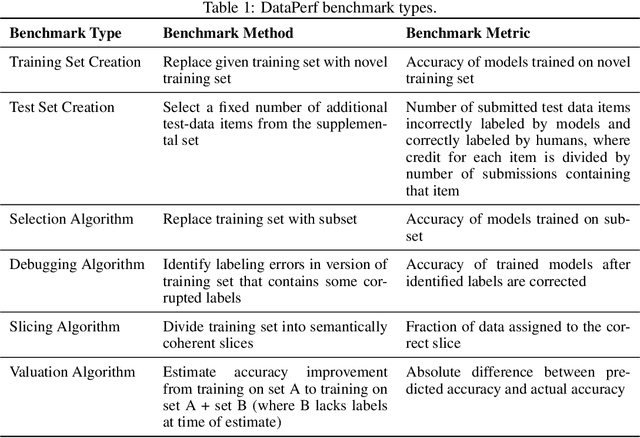
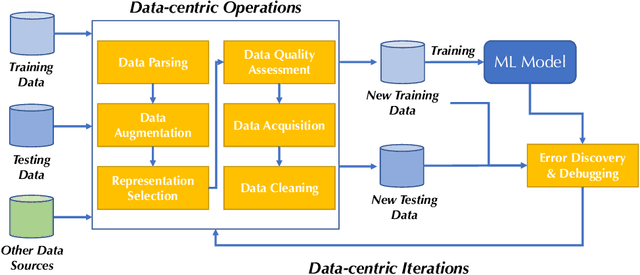
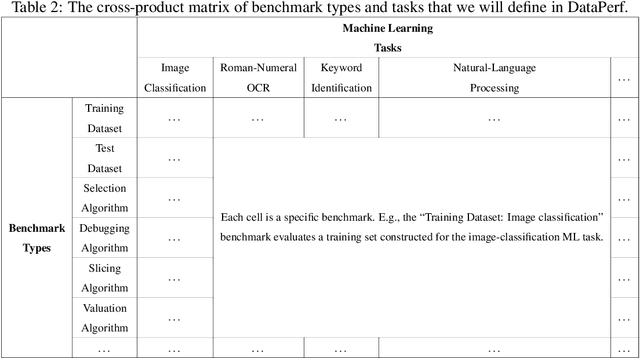
Machine learning (ML) research has generally focused on models, while the most prominent datasets have been employed for everyday ML tasks without regard for the breadth, difficulty, and faithfulness of these datasets to the underlying problem. Neglecting the fundamental importance of datasets has caused major problems involving data cascades in real-world applications and saturation of dataset-driven criteria for model quality, hindering research growth. To solve this problem, we present DataPerf, a benchmark package for evaluating ML datasets and dataset-working algorithms. We intend it to enable the "data ratchet," in which training sets will aid in evaluating test sets on the same problems, and vice versa. Such a feedback-driven strategy will generate a virtuous loop that will accelerate development of data-centric AI. The MLCommons Association will maintain DataPerf.