 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYour Classifier Can Be Secretly a Likelihood-Based OOD Detector
Aug 09, 2024The ability to detect out-of-distribution (OOD) inputs is critical to guarantee the reliability of classification models deployed in an open environment. A fundamental challenge in OOD detection is that a discriminative classifier is typically trained to estimate the posterior probability p(y|z) for class y given an input z, but lacks the explicit likelihood estimation of p(z) ideally needed for OOD detection. While numerous OOD scoring functions have been proposed for classification models, these estimate scores are often heuristic-driven and cannot be rigorously interpreted as likelihood. To bridge the gap, we propose Intrinsic Likelihood (INK), which offers rigorous likelihood interpretation to modern discriminative-based classifiers. Specifically, our proposed INK score operates on the constrained latent embeddings of a discriminative classifier, which are modeled as a mixture of hyperspherical embeddings with constant norm. We draw a novel connection between the hyperspherical distribution and the intrinsic likelihood, which can be effectively optimized in modern neural networks. Extensive experiments on the OpenOOD benchmark empirically demonstrate that INK establishes a new state-of-the-art in a variety of OOD detection setups, including both far-OOD and near-OOD. Code is available at https://github.com/deeplearning-wisc/ink.
ColorSwap: A Color and Word Order Dataset for Multimodal Evaluation
Feb 07, 2024



This paper introduces the ColorSwap dataset, designed to assess and improve the proficiency of multimodal models in matching objects with their colors. The dataset is comprised of 2,000 unique image-caption pairs, grouped into 1,000 examples. Each example includes a caption-image pair, along with a ``color-swapped'' pair. We follow the Winoground schema: the two captions in an example have the same words, but the color words have been rearranged to modify different objects. The dataset was created through a novel blend of automated caption and image generation with humans in the loop. We evaluate image-text matching (ITM) and visual language models (VLMs) and find that even the latest ones are still not robust at this task. GPT-4V and LLaVA score 72% and 42% on our main VLM metric, although they may improve with more advanced prompting techniques. On the main ITM metric, contrastive models such as CLIP and SigLIP perform close to chance (at 12% and 30%, respectively), although the non-contrastive BLIP ITM model is stronger (87%). We also find that finetuning on fewer than 2,000 examples yields significant performance gains on this out-of-distribution word-order understanding task. The dataset is here: https://github.com/Top34051/colorswap.
ARGS: Alignment as Reward-Guided Search
Jan 23, 2024Aligning large language models with human objectives is paramount, yet common approaches including RLHF suffer from unstable and resource-intensive training. In response to this challenge, we introduce ARGS, Alignment as Reward-Guided Search, a novel framework that integrates alignment into the decoding process, eliminating the need for expensive RL training. By adjusting the model's probabilistic predictions using a reward signal, ARGS generates texts with semantic diversity while being aligned with human preferences, offering a promising and flexible solution for aligning language models. Notably, ARGS demonstrates consistent enhancements in average reward compared to baselines across diverse alignment tasks and various model dimensions. For example, under the same greedy-based decoding strategy, our method improves the average reward by 19.56% relative to the baseline and secures a preference or tie score of 64.33% in GPT-4 evaluation. We believe that our framework, emphasizing decoding-time alignment, paves the way for more responsive language models in the future. Code is publicly available at: \url{https://github.com/deeplearning-wisc/args}.
A critical appraisal of equity in conversational AI: Evidence from auditing GPT-3's dialogues with different publics on climate change and Black Lives Matter
Sep 27, 2022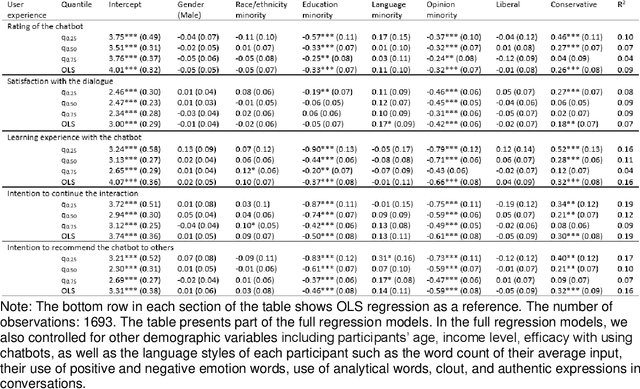
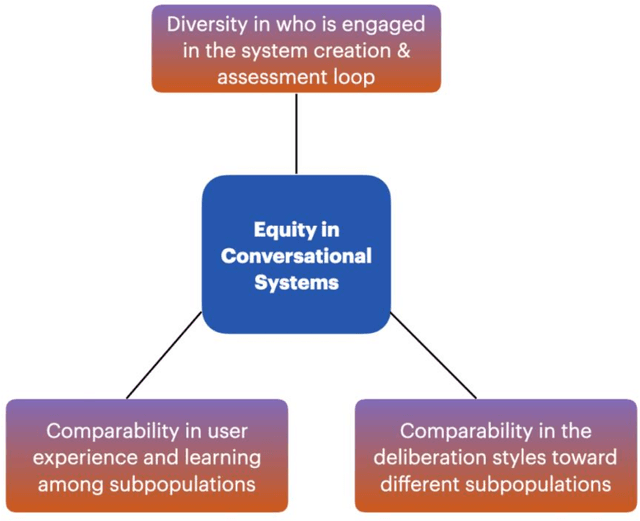
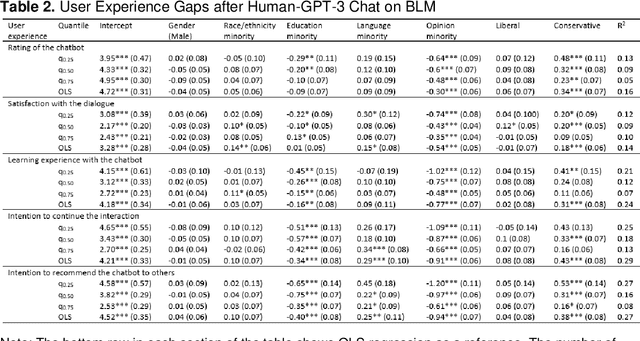
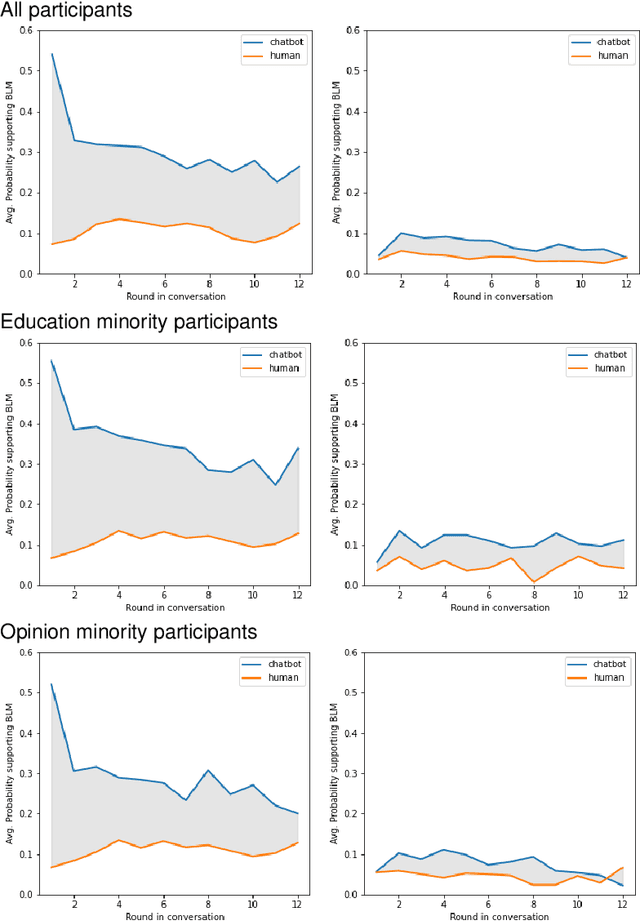
Autoregressive language models, which use deep learning to produce human-like texts, have become increasingly widespread. Such models are powering popular virtual assistants in areas like smart health, finance, and autonomous driving. While the parameters of these large language models are improving, concerns persist that these models might not work equally for all subgroups in society. Despite growing discussions of AI fairness across disciplines, there lacks systemic metrics to assess what equity means in dialogue systems and how to engage different populations in the assessment loop. Grounded in theories of deliberative democracy and science and technology studies, this paper proposes an analytical framework for unpacking the meaning of equity in human-AI dialogues. Using this framework, we conducted an auditing study to examine how GPT-3 responded to different sub-populations on crucial science and social topics: climate change and the Black Lives Matter (BLM) movement. Our corpus consists of over 20,000 rounds of dialogues between GPT-3 and 3290 individuals who vary in gender, race and ethnicity, education level, English as a first language, and opinions toward the issues. We found a substantively worse user experience with GPT-3 among the opinion and the education minority subpopulations; however, these two groups achieved the largest knowledge gain, changing attitudes toward supporting BLM and climate change efforts after the chat. We traced these user experience divides to conversational differences and found that GPT-3 used more negative expressions when it responded to the education and opinion minority groups, compared to its responses to the majority groups. We discuss the implications of our findings for a deliberative conversational AI system that centralizes diversity, equity, and inclusion.