 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA critical appraisal of equity in conversational AI: Evidence from auditing GPT-3's dialogues with different publics on climate change and Black Lives Matter
Paper and Code
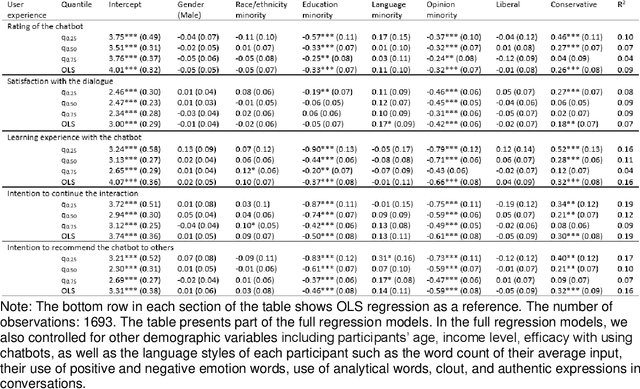
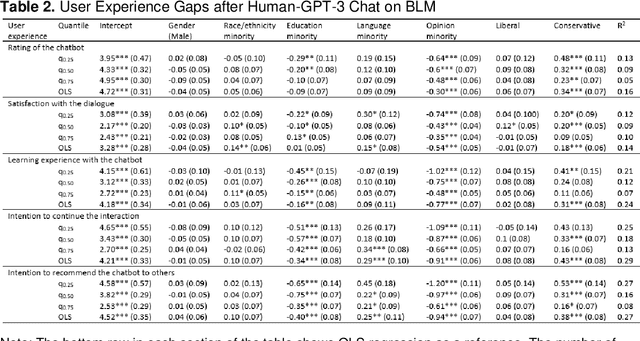
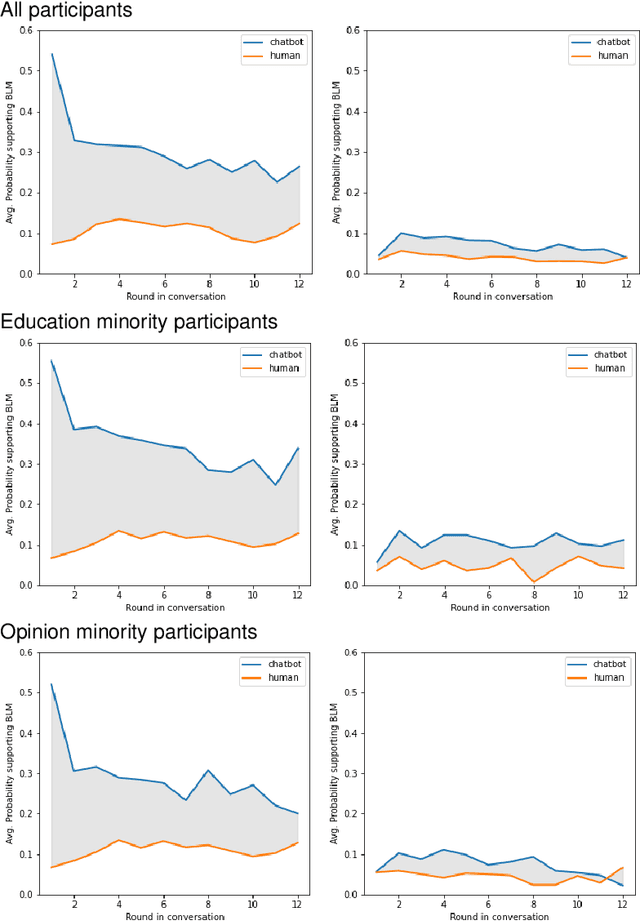
Autoregressive language models, which use deep learning to produce human-like texts, have become increasingly widespread. Such models are powering popular virtual assistants in areas like smart health, finance, and autonomous driving. While the parameters of these large language models are improving, concerns persist that these models might not work equally for all subgroups in society. Despite growing discussions of AI fairness across disciplines, there lacks systemic metrics to assess what equity means in dialogue systems and how to engage different populations in the assessment loop. Grounded in theories of deliberative democracy and science and technology studies, this paper proposes an analytical framework for unpacking the meaning of equity in human-AI dialogues. Using this framework, we conducted an auditing study to examine how GPT-3 responded to different sub-populations on crucial science and social topics: climate change and the Black Lives Matter (BLM) movement. Our corpus consists of over 20,000 rounds of dialogues between GPT-3 and 3290 individuals who vary in gender, race and ethnicity, education level, English as a first language, and opinions toward the issues. We found a substantively worse user experience with GPT-3 among the opinion and the education minority subpopulations; however, these two groups achieved the largest knowledge gain, changing attitudes toward supporting BLM and climate change efforts after the chat. We traced these user experience divides to conversational differences and found that GPT-3 used more negative expressions when it responded to the education and opinion minority groups, compared to its responses to the majority groups. We discuss the implications of our findings for a deliberative conversational AI system that centralizes diversity, equity, and inclusion.