 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Simulate Human Dialogue
Jan 07, 2026To predict what someone will say is to model how they think. We study this through next-turn dialogue prediction: given a conversation, predict the next utterance produced by a person. We compare learning approaches along two dimensions: (1) whether the model is allowed to think before responding, and (2) how learning is rewarded either through an LLM-as-a-judge that scores semantic similarity and information completeness relative to the ground-truth response, or by directly maximizing the log-probability of the true human dialogue. We find that optimizing for judge-based rewards indeed increases judge scores throughout training, however it decreases the likelihood assigned to ground truth human responses and decreases the win rate when human judges choose the most human-like response among a real and synthetic option. This failure is amplified when the model is allowed to think before answering. In contrast, by directly maximizing the log-probability of observed human responses, the model learns to better predict what people actually say, improving on both log-probability and win rate evaluations. Treating chain-of-thought as a latent variable, we derive a lower bound on the log-probability. Optimizing this objective yields the best results on all our evaluations. These results suggest that thinking helps primarily when trained with a distribution-matching objective grounded in real human dialogue, and that scaling this approach to broader conversational data may produce models with a more nuanced understanding of human behavior.
Hypothetical Minds: Scaffolding Theory of Mind for Multi-Agent Tasks with Large Language Models
Jul 09, 2024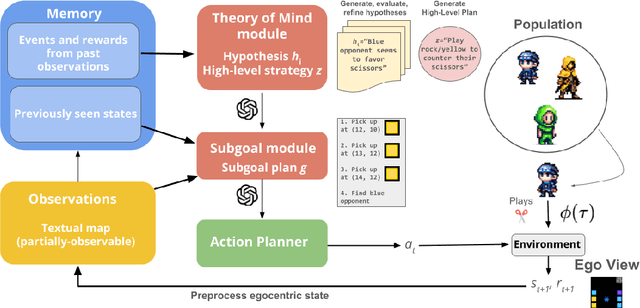
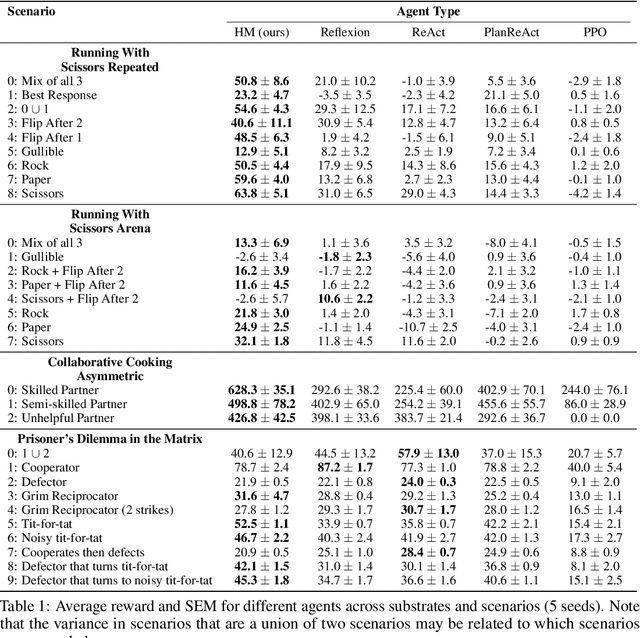
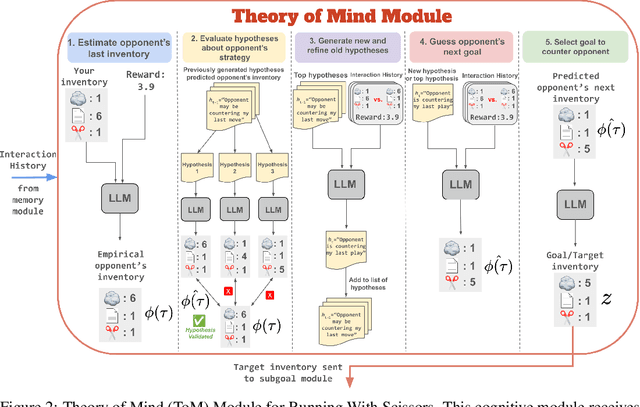
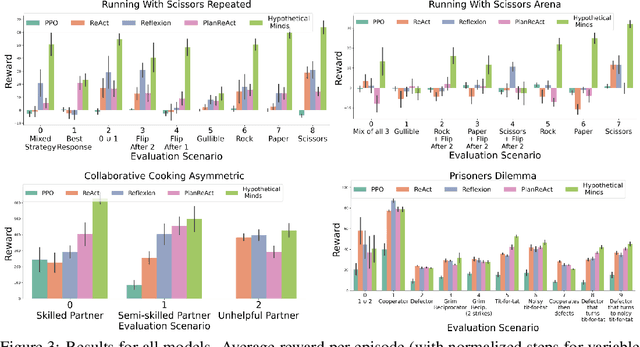
Multi-agent reinforcement learning (MARL) methods struggle with the non-stationarity of multi-agent systems and fail to adaptively learn online when tested with novel agents. Here, we leverage large language models (LLMs) to create an autonomous agent that can handle these challenges. Our agent, Hypothetical Minds, consists of a cognitively-inspired architecture, featuring modular components for perception, memory, and hierarchical planning over two levels of abstraction. We introduce the Theory of Mind module that scaffolds the high-level planning process by generating hypotheses about other agents' strategies in natural language. It then evaluates and iteratively refines these hypotheses by reinforcing hypotheses that make correct predictions about the other agents' behavior. Hypothetical Minds significantly improves performance over previous LLM-agent and RL baselines on a range of competitive, mixed motive, and collaborative domains in the Melting Pot benchmark, including both dyadic and population-based environments. Additionally, comparisons against LLM-agent baselines and ablations reveal the importance of hypothesis evaluation and refinement for succeeding on complex scenarios.
ColorSwap: A Color and Word Order Dataset for Multimodal Evaluation
Feb 07, 2024



This paper introduces the ColorSwap dataset, designed to assess and improve the proficiency of multimodal models in matching objects with their colors. The dataset is comprised of 2,000 unique image-caption pairs, grouped into 1,000 examples. Each example includes a caption-image pair, along with a ``color-swapped'' pair. We follow the Winoground schema: the two captions in an example have the same words, but the color words have been rearranged to modify different objects. The dataset was created through a novel blend of automated caption and image generation with humans in the loop. We evaluate image-text matching (ITM) and visual language models (VLMs) and find that even the latest ones are still not robust at this task. GPT-4V and LLaVA score 72% and 42% on our main VLM metric, although they may improve with more advanced prompting techniques. On the main ITM metric, contrastive models such as CLIP and SigLIP perform close to chance (at 12% and 30%, respectively), although the non-contrastive BLIP ITM model is stronger (87%). We also find that finetuning on fewer than 2,000 examples yields significant performance gains on this out-of-distribution word-order understanding task. The dataset is here: https://github.com/Top34051/colorswap.