 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrontierScience: Evaluating AI's Ability to Perform Expert-Level Scientific Tasks
Jan 29, 2026We introduce FrontierScience, a benchmark evaluating expert-level scientific reasoning in frontier language models. Recent model progress has nearly saturated existing science benchmarks, which often rely on multiple-choice knowledge questions or already published information. FrontierScience addresses this gap through two complementary tracks: (1) Olympiad, consisting of international olympiad problems at the level of IPhO, IChO, and IBO, and (2) Research, consisting of PhD-level, open-ended problems representative of sub-tasks in scientific research. FrontierScience contains several hundred questions (including 160 in the open-sourced gold set) covering subfields across physics, chemistry, and biology, from quantum electrodynamics to synthetic organic chemistry. All Olympiad problems are originally produced by international Olympiad medalists and national team coaches to ensure standards of difficulty, originality, and factuality. All Research problems are research sub-tasks written and verified by PhD scientists (doctoral candidates, postdoctoral researchers, or professors). For Research, we introduce a granular rubric-based evaluation framework to assess model capabilities throughout the process of solving a research task, rather than judging only a standalone final answer.
Eliciting Language Model Behaviors with Investigator Agents
Feb 03, 2025Language models exhibit complex, diverse behaviors when prompted with free-form text, making it difficult to characterize the space of possible outputs. We study the problem of behavior elicitation, where the goal is to search for prompts that induce specific target behaviors (e.g., hallucinations or harmful responses) from a target language model. To navigate the exponentially large space of possible prompts, we train investigator models to map randomly-chosen target behaviors to a diverse distribution of outputs that elicit them, similar to amortized Bayesian inference. We do this through supervised fine-tuning, reinforcement learning via DPO, and a novel Frank-Wolfe training objective to iteratively discover diverse prompting strategies. Our investigator models surface a variety of effective and human-interpretable prompts leading to jailbreaks, hallucinations, and open-ended aberrant behaviors, obtaining a 100% attack success rate on a subset of AdvBench (Harmful Behaviors) and an 85% hallucination rate.
OpenAI o1 System Card
Dec 21, 2024



The o1 model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment. This leads to state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence. Our results underscore the need for building robust alignment methods, extensively stress-testing their efficacy, and maintaining meticulous risk management protocols. This report outlines the safety work carried out for the OpenAI o1 and OpenAI o1-mini models, including safety evaluations, external red teaming, and Preparedness Framework evaluations.
Nearest Neighbor Normalization Improves Multimodal Retrieval
Oct 31, 2024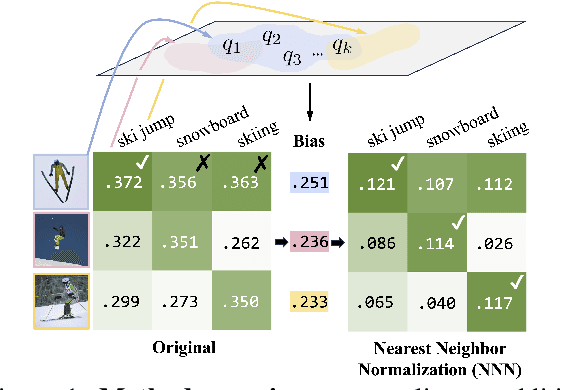



Multimodal models leverage large-scale pre-training to achieve strong but still imperfect performance on tasks such as image captioning, visual question answering, and cross-modal retrieval. In this paper, we present a simple and efficient method for correcting errors in trained contrastive image-text retrieval models with no additional training, called Nearest Neighbor Normalization (NNN). We show an improvement on retrieval metrics in both text retrieval and image retrieval for all of the contrastive models that we tested (CLIP, BLIP, ALBEF, SigLIP, BEiT) and for both of the datasets that we used (MS-COCO and Flickr30k). NNN requires a reference database, but does not require any training on this database, and can even increase the retrieval accuracy of a model after finetuning.
GPT-4o System Card
Oct 25, 2024GPT-4o is an autoregressive omni model that accepts as input any combination of text, audio, image, and video, and generates any combination of text, audio, and image outputs. It's trained end-to-end across text, vision, and audio, meaning all inputs and outputs are processed by the same neural network. GPT-4o can respond to audio inputs in as little as 232 milliseconds, with an average of 320 milliseconds, which is similar to human response time in conversation. It matches GPT-4 Turbo performance on text in English and code, with significant improvement on text in non-English languages, while also being much faster and 50\% cheaper in the API. GPT-4o is especially better at vision and audio understanding compared to existing models. In line with our commitment to building AI safely and consistent with our voluntary commitments to the White House, we are sharing the GPT-4o System Card, which includes our Preparedness Framework evaluations. In this System Card, we provide a detailed look at GPT-4o's capabilities, limitations, and safety evaluations across multiple categories, focusing on speech-to-speech while also evaluating text and image capabilities, and measures we've implemented to ensure the model is safe and aligned. We also include third-party assessments on dangerous capabilities, as well as discussion of potential societal impacts of GPT-4o's text and vision capabilities.
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Oct 09, 2024



We introduce MLE-bench, a benchmark for measuring how well AI agents perform at machine learning engineering. To this end, we curate 75 ML engineering-related competitions from Kaggle, creating a diverse set of challenging tasks that test real-world ML engineering skills such as training models, preparing datasets, and running experiments. We establish human baselines for each competition using Kaggle's publicly available leaderboards. We use open-source agent scaffolds to evaluate several frontier language models on our benchmark, finding that the best-performing setup--OpenAI's o1-preview with AIDE scaffolding--achieves at least the level of a Kaggle bronze medal in 16.9% of competitions. In addition to our main results, we investigate various forms of resource scaling for AI agents and the impact of contamination from pre-training. We open-source our benchmark code (github.com/openai/mle-bench/) to facilitate future research in understanding the ML engineering capabilities of AI agents.
Automatic Discovery of Visual Circuits
Apr 22, 2024



To date, most discoveries of network subcomponents that implement human-interpretable computations in deep vision models have involved close study of single units and large amounts of human labor. We explore scalable methods for extracting the subgraph of a vision model's computational graph that underlies recognition of a specific visual concept. We introduce a new method for identifying these subgraphs: specifying a visual concept using a few examples, and then tracing the interdependence of neuron activations across layers, or their functional connectivity. We find that our approach extracts circuits that causally affect model output, and that editing these circuits can defend large pretrained models from adversarial attacks.
A Function Interpretation Benchmark for Evaluating Interpretability Methods
Sep 07, 2023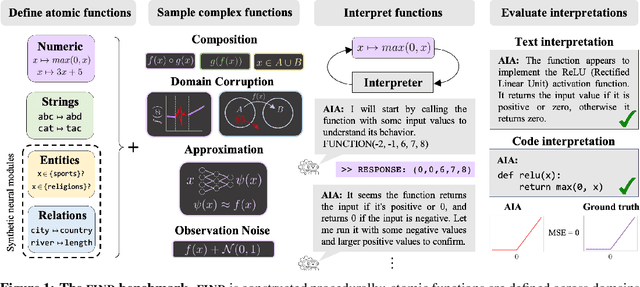



Labeling neural network submodules with human-legible descriptions is useful for many downstream tasks: such descriptions can surface failures, guide interventions, and perhaps even explain important model behaviors. To date, most mechanistic descriptions of trained networks have involved small models, narrowly delimited phenomena, and large amounts of human labor. Labeling all human-interpretable sub-computations in models of increasing size and complexity will almost certainly require tools that can generate and validate descriptions automatically. Recently, techniques that use learned models in-the-loop for labeling have begun to gain traction, but methods for evaluating their efficacy are limited and ad-hoc. How should we validate and compare open-ended labeling tools? This paper introduces FIND (Function INterpretation and Description), a benchmark suite for evaluating the building blocks of automated interpretability methods. FIND contains functions that resemble components of trained neural networks, and accompanying descriptions of the kind we seek to generate. The functions are procedurally constructed across textual and numeric domains, and involve a range of real-world complexities, including noise, composition, approximation, and bias. We evaluate new and existing methods that use language models (LMs) to produce code-based and language descriptions of function behavior. We find that an off-the-shelf LM augmented with only black-box access to functions can sometimes infer their structure, acting as a scientist by forming hypotheses, proposing experiments, and updating descriptions in light of new data. However, LM-based descriptions tend to capture global function behavior and miss local corruptions. These results show that FIND will be useful for characterizing the performance of more sophisticated interpretability methods before they are applied to real-world models.
Multimodal Neurons in Pretrained Text-Only Transformers
Aug 03, 2023Language models demonstrate remarkable capacity to generalize representations learned in one modality to downstream tasks in other modalities. Can we trace this ability to individual neurons? We study the case where a frozen text transformer is augmented with vision using a self-supervised visual encoder and a single linear projection learned on an image-to-text task. Outputs of the projection layer are not immediately decodable into language describing image content; instead, we find that translation between modalities occurs deeper within the transformer. We introduce a procedure for identifying "multimodal neurons" that convert visual representations into corresponding text, and decoding the concepts they inject into the model's residual stream. In a series of experiments, we show that multimodal neurons operate on specific visual concepts across inputs, and have a systematic causal effect on image captioning.