 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight-sparse transformers have interpretable circuits
Nov 17, 2025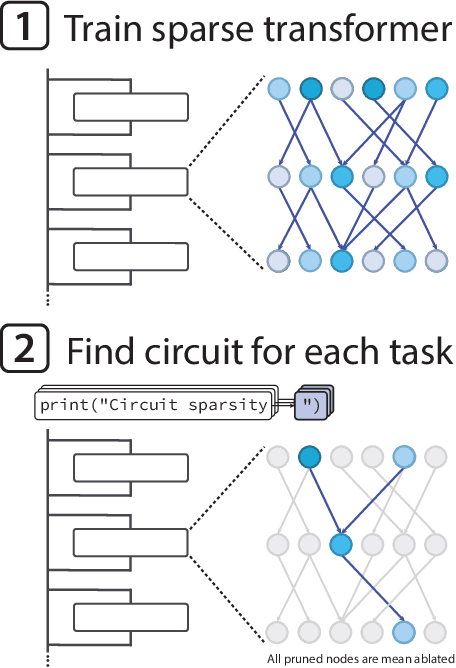

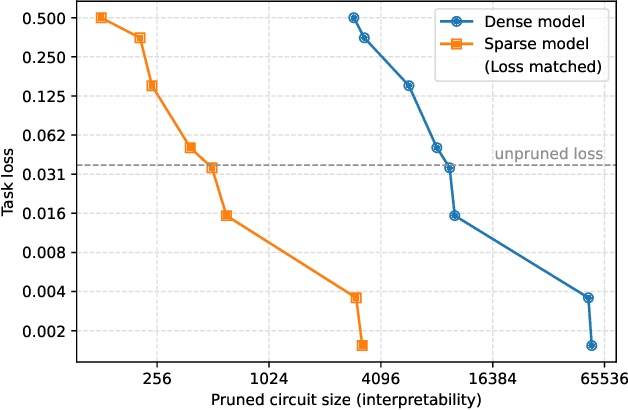

Finding human-understandable circuits in language models is a central goal of the field of mechanistic interpretability. We train models to have more understandable circuits by constraining most of their weights to be zeros, so that each neuron only has a few connections. To recover fine-grained circuits underlying each of several hand-crafted tasks, we prune the models to isolate the part responsible for the task. These circuits often contain neurons and residual channels that correspond to natural concepts, with a small number of straightforwardly interpretable connections between them. We study how these models scale and find that making weights sparser trades off capability for interpretability, and scaling model size improves the capability-interpretability frontier. However, scaling sparse models beyond tens of millions of nonzero parameters while preserving interpretability remains a challenge. In addition to training weight-sparse models de novo, we show preliminary results suggesting our method can also be adapted to explain existing dense models. Our work produces circuits that achieve an unprecedented level of human understandability and validates them with considerable rigor.
Line of Sight: On Linear Representations in VLLMs
Jun 05, 2025Language models can be equipped with multimodal capabilities by fine-tuning on embeddings of visual inputs. But how do such multimodal models represent images in their hidden activations? We explore representations of image concepts within LlaVA-Next, a popular open-source VLLM. We find a diverse set of ImageNet classes represented via linearly decodable features in the residual stream. We show that the features are causal by performing targeted edits on the model output. In order to increase the diversity of the studied linear features, we train multimodal Sparse Autoencoders (SAEs), creating a highly interpretable dictionary of text and image features. We find that although model representations across modalities are quite disjoint, they become increasingly shared in deeper layers.
A Multimodal Automated Interpretability Agent
Apr 22, 2024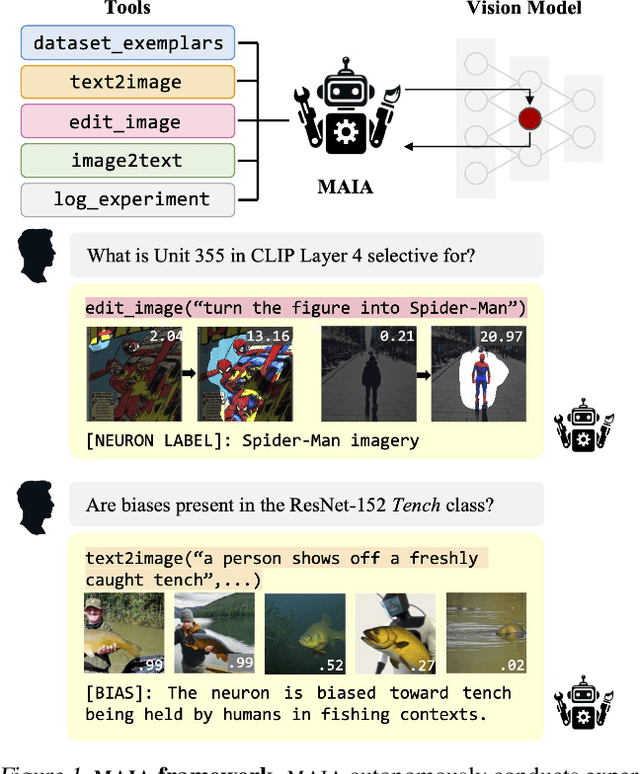



This paper describes MAIA, a Multimodal Automated Interpretability Agent. MAIA is a system that uses neural models to automate neural model understanding tasks like feature interpretation and failure mode discovery. It equips a pre-trained vision-language model with a set of tools that support iterative experimentation on subcomponents of other models to explain their behavior. These include tools commonly used by human interpretability researchers: for synthesizing and editing inputs, computing maximally activating exemplars from real-world datasets, and summarizing and describing experimental results. Interpretability experiments proposed by MAIA compose these tools to describe and explain system behavior. We evaluate applications of MAIA to computer vision models. We first characterize MAIA's ability to describe (neuron-level) features in learned representations of images. Across several trained models and a novel dataset of synthetic vision neurons with paired ground-truth descriptions, MAIA produces descriptions comparable to those generated by expert human experimenters. We then show that MAIA can aid in two additional interpretability tasks: reducing sensitivity to spurious features, and automatically identifying inputs likely to be mis-classified.
Automatic Discovery of Visual Circuits
Apr 22, 2024



To date, most discoveries of network subcomponents that implement human-interpretable computations in deep vision models have involved close study of single units and large amounts of human labor. We explore scalable methods for extracting the subgraph of a vision model's computational graph that underlies recognition of a specific visual concept. We introduce a new method for identifying these subgraphs: specifying a visual concept using a few examples, and then tracing the interdependence of neuron activations across layers, or their functional connectivity. We find that our approach extracts circuits that causally affect model output, and that editing these circuits can defend large pretrained models from adversarial attacks.
FREDSR: Fourier Residual Efficient Diffusive GAN for Single Image Super Resolution
Nov 30, 2022FREDSR is a GAN variant that aims to outperform traditional GAN models in specific tasks such as Single Image Super Resolution with extreme parameter efficiency at the cost of per-dataset generalizeability. FREDSR integrates fast Fourier transformation, residual prediction, diffusive discriminators, etc to achieve strong performance in comparisons to other models on the UHDSR4K dataset for Single Image 3x Super Resolution from 360p and 720p with only 37000 parameters. The model follows the characteristics of the given dataset, resulting in lower generalizeability but higher performance on tasks such as real time up-scaling.