 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal Automated Interpretability Agent
Apr 22, 2024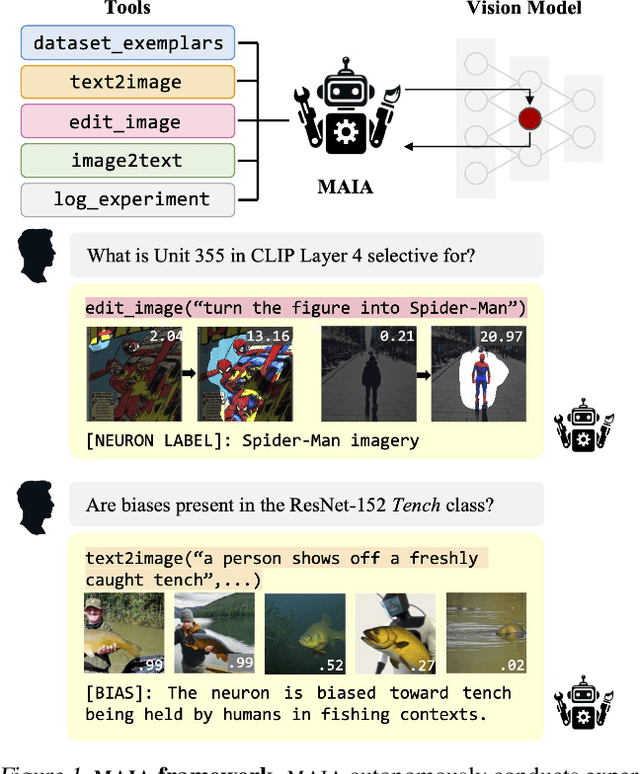



This paper describes MAIA, a Multimodal Automated Interpretability Agent. MAIA is a system that uses neural models to automate neural model understanding tasks like feature interpretation and failure mode discovery. It equips a pre-trained vision-language model with a set of tools that support iterative experimentation on subcomponents of other models to explain their behavior. These include tools commonly used by human interpretability researchers: for synthesizing and editing inputs, computing maximally activating exemplars from real-world datasets, and summarizing and describing experimental results. Interpretability experiments proposed by MAIA compose these tools to describe and explain system behavior. We evaluate applications of MAIA to computer vision models. We first characterize MAIA's ability to describe (neuron-level) features in learned representations of images. Across several trained models and a novel dataset of synthetic vision neurons with paired ground-truth descriptions, MAIA produces descriptions comparable to those generated by expert human experimenters. We then show that MAIA can aid in two additional interpretability tasks: reducing sensitivity to spurious features, and automatically identifying inputs likely to be mis-classified.
Linearity of Relation Decoding in Transformer Language Models
Aug 17, 2023Much of the knowledge encoded in transformer language models (LMs) may be expressed in terms of relations: relations between words and their synonyms, entities and their attributes, etc. We show that, for a subset of relations, this computation is well-approximated by a single linear transformation on the subject representation. Linear relation representations may be obtained by constructing a first-order approximation to the LM from a single prompt, and they exist for a variety of factual, commonsense, and linguistic relations. However, we also identify many cases in which LM predictions capture relational knowledge accurately, but this knowledge is not linearly encoded in their representations. Our results thus reveal a simple, interpretable, but heterogeneously deployed knowledge representation strategy in transformer LMs.
Measuring and Manipulating Knowledge Representations in Language Models
Apr 03, 2023
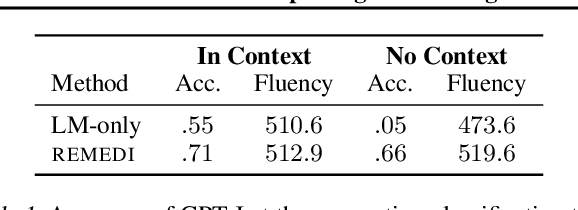
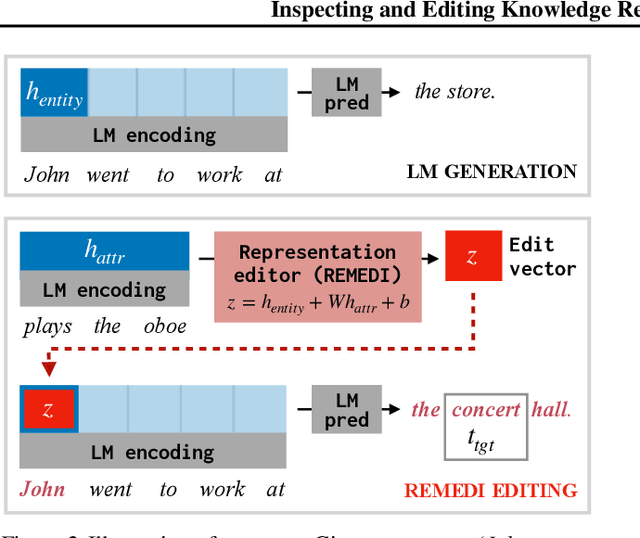
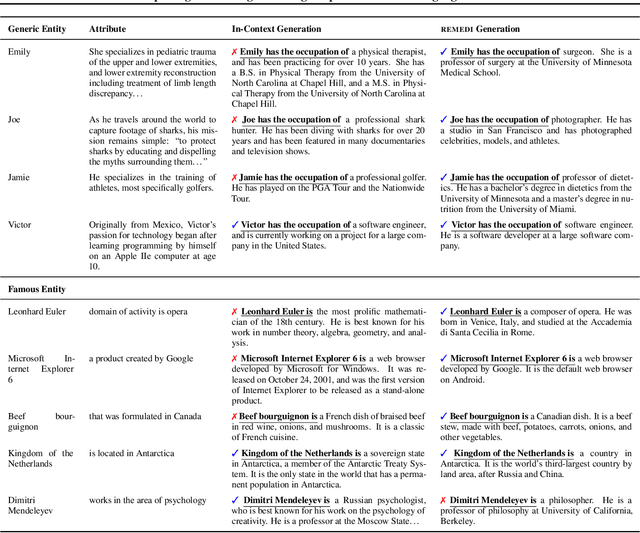
Neural language models (LMs) represent facts about the world described by text. Sometimes these facts derive from training data (in most LMs, a representation of the word banana encodes the fact that bananas are fruits). Sometimes facts derive from input text itself (a representation of the sentence "I poured out the bottle" encodes the fact that the bottle became empty). Tools for inspecting and modifying LM fact representations would be useful almost everywhere LMs are used: making it possible to update them when the world changes, to localize and remove sources of bias, and to identify errors in generated text. We describe REMEDI, an approach for querying and modifying factual knowledge in LMs. REMEDI learns a map from textual queries to fact encodings in an LM's internal representation system. These encodings can be used as knowledge editors: by adding them to LM hidden representations, we can modify downstream generation to be consistent with new facts. REMEDI encodings can also be used as model probes: by comparing them to LM representations, we can ascertain what properties LMs attribute to mentioned entities, and predict when they will generate outputs that conflict with background knowledge or input text. REMEDI thus links work on probing, prompting, and model editing, and offers steps toward general tools for fine-grained inspection and control of knowledge in LMs.
Do We Still Need Clinical Language Models?
Feb 16, 2023



Although recent advances in scaling large language models (LLMs) have resulted in improvements on many NLP tasks, it remains unclear whether these models trained primarily with general web text are the right tool in highly specialized, safety critical domains such as clinical text. Recent results have suggested that LLMs encode a surprising amount of medical knowledge. This raises an important question regarding the utility of smaller domain-specific language models. With the success of general-domain LLMs, is there still a need for specialized clinical models? To investigate this question, we conduct an extensive empirical analysis of 12 language models, ranging from 220M to 175B parameters, measuring their performance on 3 different clinical tasks that test their ability to parse and reason over electronic health records. As part of our experiments, we train T5-Base and T5-Large models from scratch on clinical notes from MIMIC III and IV to directly investigate the efficiency of clinical tokens. We show that relatively small specialized clinical models substantially outperform all in-context learning approaches, even when finetuned on limited annotated data. Further, we find that pretraining on clinical tokens allows for smaller, more parameter-efficient models that either match or outperform much larger language models trained on general text. We release the code and the models used under the PhysioNet Credentialed Health Data license and data use agreement.
Natural Language Descriptions of Deep Visual Features
Jan 26, 2022
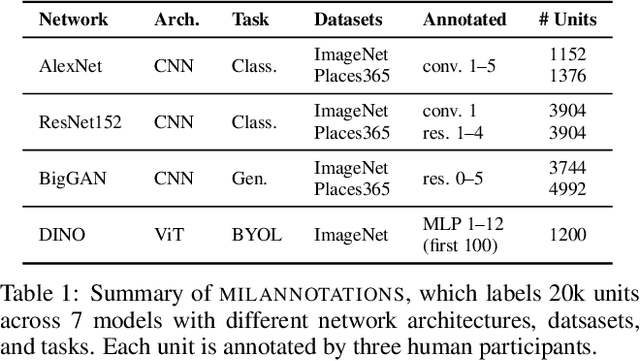
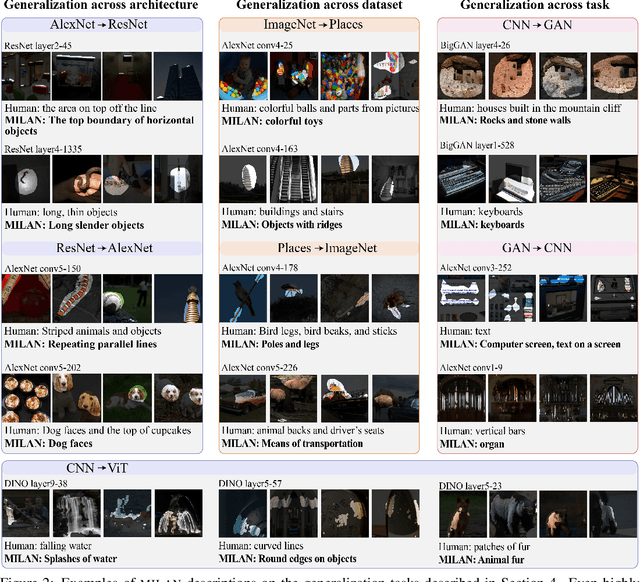
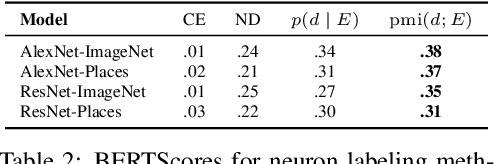
Some neurons in deep networks specialize in recognizing highly specific perceptual, structural, or semantic features of inputs. In computer vision, techniques exist for identifying neurons that respond to individual concept categories like colors, textures, and object classes. But these techniques are limited in scope, labeling only a small subset of neurons and behaviors in any network. Is a richer characterization of neuron-level computation possible? We introduce a procedure (called MILAN, for mutual-information-guided linguistic annotation of neurons) that automatically labels neurons with open-ended, compositional, natural language descriptions. Given a neuron, MILAN generates a description by searching for a natural language string that maximizes pointwise mutual information with the image regions in which the neuron is active. MILAN produces fine-grained descriptions that capture categorical, relational, and logical structure in learned features. These descriptions obtain high agreement with human-generated feature descriptions across a diverse set of model architectures and tasks, and can aid in understanding and controlling learned models. We highlight three applications of natural language neuron descriptions. First, we use MILAN for analysis, characterizing the distribution and importance of neurons selective for attribute, category, and relational information in vision models. Second, we use MILAN for auditing, surfacing neurons sensitive to protected categories like race and gender in models trained on datasets intended to obscure these features. Finally, we use MILAN for editing, improving robustness in an image classifier by deleting neurons sensitive to text features spuriously correlated with class labels.
Toward a Visual Concept Vocabulary for GAN Latent Space
Oct 08, 2021
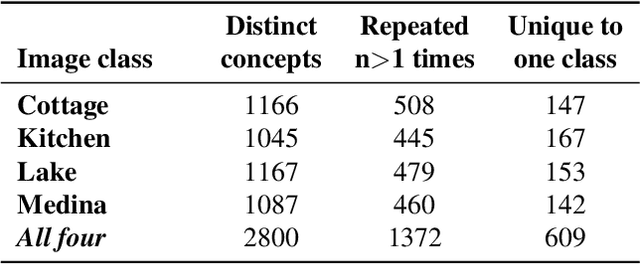

A large body of recent work has identified transformations in the latent spaces of generative adversarial networks (GANs) that consistently and interpretably transform generated images. But existing techniques for identifying these transformations rely on either a fixed vocabulary of pre-specified visual concepts, or on unsupervised disentanglement techniques whose alignment with human judgments about perceptual salience is unknown. This paper introduces a new method for building open-ended vocabularies of primitive visual concepts represented in a GAN's latent space. Our approach is built from three components: (1) automatic identification of perceptually salient directions based on their layer selectivity; (2) human annotation of these directions with free-form, compositional natural language descriptions; and (3) decomposition of these annotations into a visual concept vocabulary, consisting of distilled directions labeled with single words. Experiments show that concepts learned with our approach are reliable and composable -- generalizing across classes, contexts, and observers, and enabling fine-grained manipulation of image style and content.
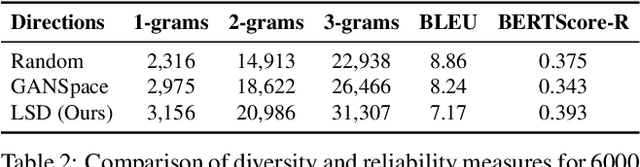
The Low-Dimensional Linear Geometry of Contextualized Word Representations
May 15, 2021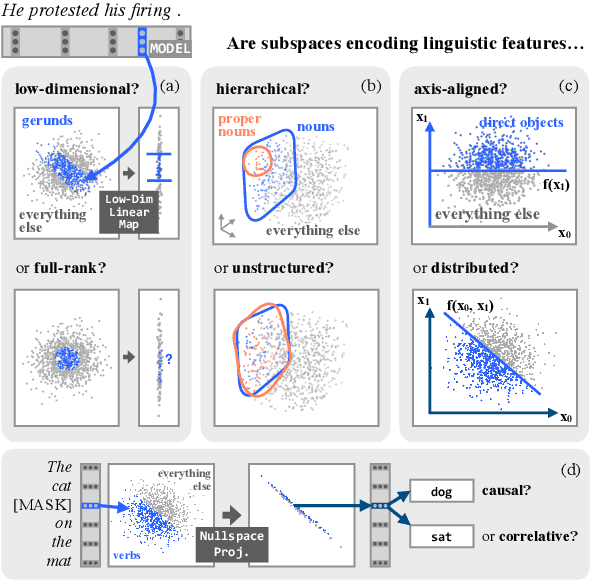
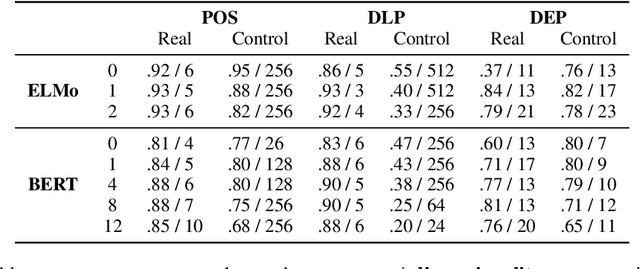
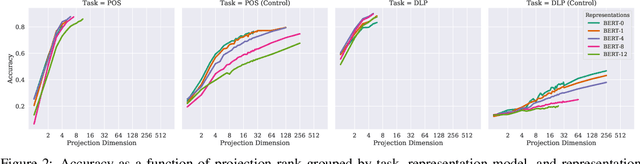

Black-box probing models can reliably extract linguistic features like tense, number, and syntactic role from pretrained word representations. However, the manner in which these features are encoded in representations remains poorly understood. We present a systematic study of the linear geometry of contextualized word representations in ELMO and BERT. We show that a variety of linguistic features (including structured dependency relationships) are encoded in low-dimensional subspaces. We then refine this geometric picture, showing that there are hierarchical relations between the subspaces encoding general linguistic categories and more specific ones, and that low-dimensional feature encodings are distributed rather than aligned to individual neurons. Finally, we demonstrate that these linear subspaces are causally related to model behavior, and can be used to perform fine-grained manipulation of BERT's output distribution.
Program Synthesis from Visual Specification
Jun 04, 2018
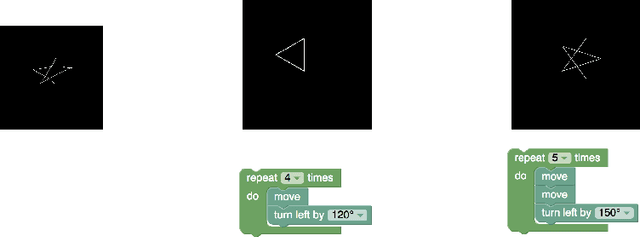


Program synthesis is the process of automatically translating a specification into computer code. Traditional synthesis settings require a formal, precise specification. Motivated by computer education applications where a student learns to code simple turtle-style drawing programs, we study a novel synthesis setting where only a noisy user-intention drawing is specified. This allows students to sketch their intended output, optionally together with their own incomplete program, to automatically produce a completed program. We formulate this synthesis problem as search in the space of programs, with the score of a state being the Hausdorff distance between the program output and the user drawing. We compare several search algorithms on a corpus consisting of real user drawings and the corresponding programs, and demonstrate that our algorithms can synthesize programs optimally satisfying the specification.