 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Still Need Clinical Language Models?
Feb 16, 2023



Although recent advances in scaling large language models (LLMs) have resulted in improvements on many NLP tasks, it remains unclear whether these models trained primarily with general web text are the right tool in highly specialized, safety critical domains such as clinical text. Recent results have suggested that LLMs encode a surprising amount of medical knowledge. This raises an important question regarding the utility of smaller domain-specific language models. With the success of general-domain LLMs, is there still a need for specialized clinical models? To investigate this question, we conduct an extensive empirical analysis of 12 language models, ranging from 220M to 175B parameters, measuring their performance on 3 different clinical tasks that test their ability to parse and reason over electronic health records. As part of our experiments, we train T5-Base and T5-Large models from scratch on clinical notes from MIMIC III and IV to directly investigate the efficiency of clinical tokens. We show that relatively small specialized clinical models substantially outperform all in-context learning approaches, even when finetuned on limited annotated data. Further, we find that pretraining on clinical tokens allows for smaller, more parameter-efficient models that either match or outperform much larger language models trained on general text. We release the code and the models used under the PhysioNet Credentialed Health Data license and data use agreement.
Procedural Image Programs for Representation Learning
Nov 29, 2022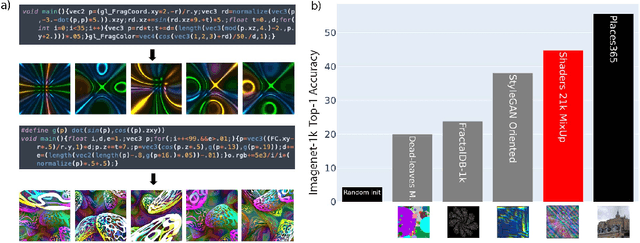
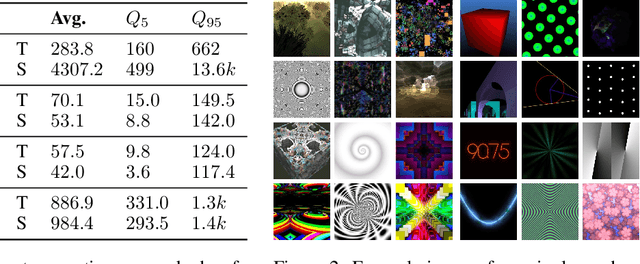
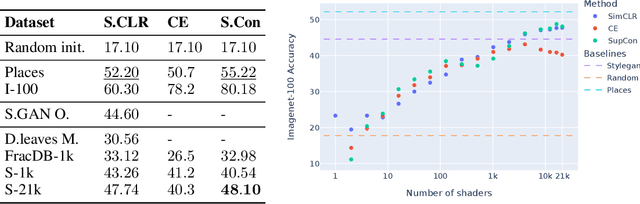
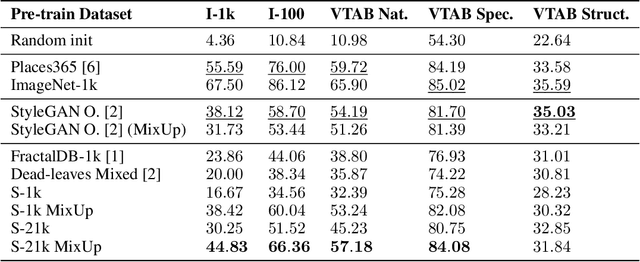
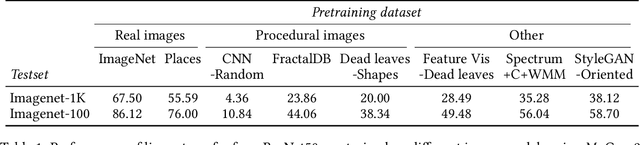
Learning image representations using synthetic data allows training neural networks without some of the concerns associated with real images, such as privacy and bias. Existing work focuses on a handful of curated generative processes which require expert knowledge to design, making it hard to scale up. To overcome this, we propose training with a large dataset of twenty-one thousand programs, each one generating a diverse set of synthetic images. These programs are short code snippets, which are easy to modify and fast to execute using OpenGL. The proposed dataset can be used for both supervised and unsupervised representation learning, and reduces the gap between pre-training with real and procedurally generated images by 38%.
* 29 pages, Accepted in the Conference on Neural Information Processing Systems 2022 (NeurIPS 2022)
Learning to See by Looking at Noise
Jun 10, 2021

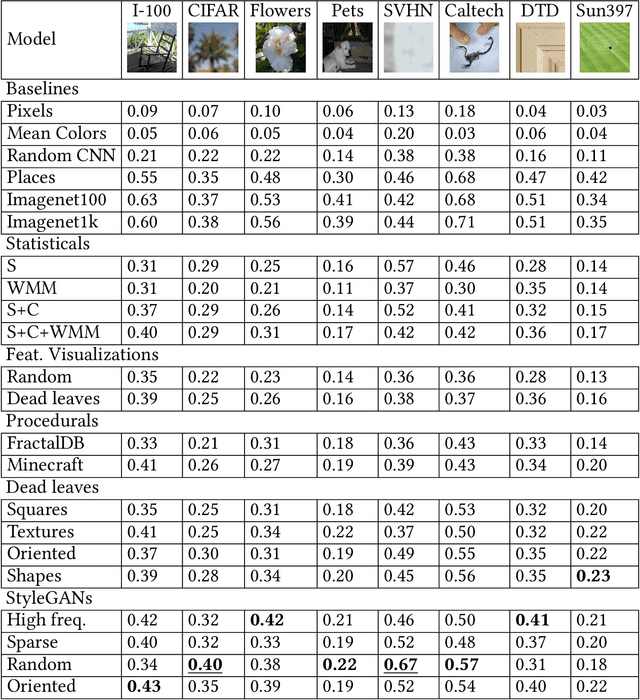
Current vision systems are trained on huge datasets, and these datasets come with costs: curation is expensive, they inherit human biases, and there are concerns over privacy and usage rights. To counter these costs, interest has surged in learning from cheaper data sources, such as unlabeled images. In this paper we go a step further and ask if we can do away with real image datasets entirely, instead learning from noise processes. We investigate a suite of image generation models that produce images from simple random processes. These are then used as training data for a visual representation learner with a contrastive loss. We study two types of noise processes, statistical image models and deep generative models under different random initializations. Our findings show that it is important for the noise to capture certain structural properties of real data but that good performance can be achieved even with processes that are far from realistic. We also find that diversity is a key property to learn good representations. Datasets, models, and code are available at https://mbaradad.github.io/learning_with_noise.
Using latent space regression to analyze and leverage compositionality in GANs
Mar 18, 2021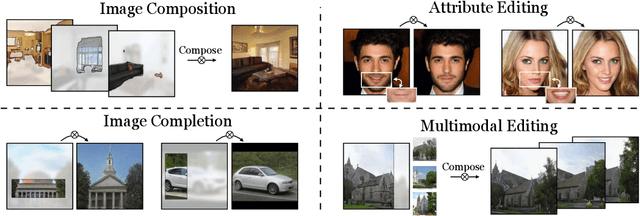



In recent years, Generative Adversarial Networks have become ubiquitous in both research and public perception, but how GANs convert an unstructured latent code to a high quality output is still an open question. In this work, we investigate regression into the latent space as a probe to understand the compositional properties of GANs. We find that combining the regressor and a pretrained generator provides a strong image prior, allowing us to create composite images from a collage of random image parts at inference time while maintaining global consistency. To compare compositional properties across different generators, we measure the trade-offs between reconstruction of the unrealistic input and image quality of the regenerated samples. We find that the regression approach enables more localized editing of individual image parts compared to direct editing in the latent space, and we conduct experiments to quantify this independence effect. Our method is agnostic to the semantics of edits, and does not require labels or predefined concepts during training. Beyond image composition, our method extends to a number of related applications, such as image inpainting or example-based image editing, which we demonstrate on several GANs and datasets, and because it uses only a single forward pass, it can operate in real-time. Code is available on our project page: https://chail.github.io/latent-composition/.
Improving Inversion and Generation Diversity in StyleGAN using a Gaussianized Latent Space
Sep 14, 2020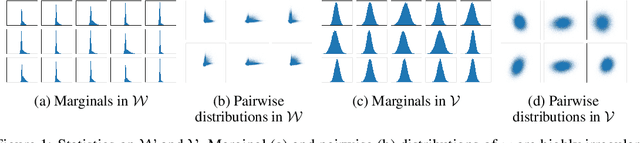
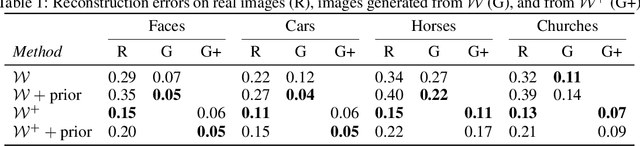
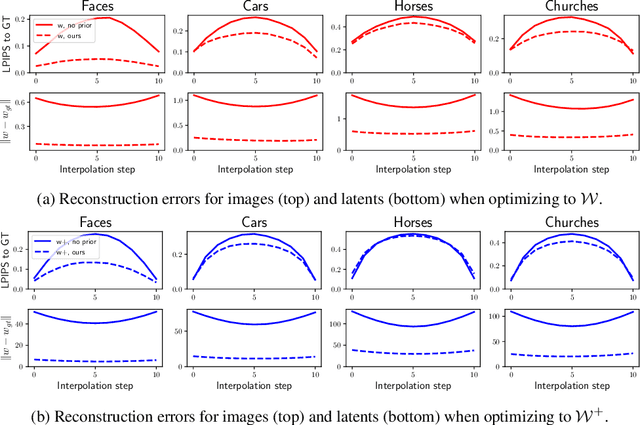

Modern Generative Adversarial Networks are capable of creating artificial, photorealistic images from latent vectors living in a low-dimensional learned latent space. It has been shown that a wide range of images can be projected into this space, including images outside of the domain that the generator was trained on. However, while in this case the generator reproduces the pixels and textures of the images, the reconstructed latent vectors are unstable and small perturbations result in significant image distortions. In this work, we propose to explicitly model the data distribution in latent space. We show that, under a simple nonlinear operation, the data distribution can be modeled as Gaussian and therefore expressed using sufficient statistics. This yields a simple Gaussian prior, which we use to regularize the projection of images into the latent space. The resulting projections lie in smoother and better behaved regions of the latent space, as shown using interpolation performance for both real and generated images. Furthermore, the Gaussian model of the distribution in latent space allows us to investigate the origins of artifacts in the generator output, and provides a method for reducing these artifacts while maintaining diversity of the generated images.
Seeing What a GAN Cannot Generate
Oct 24, 2019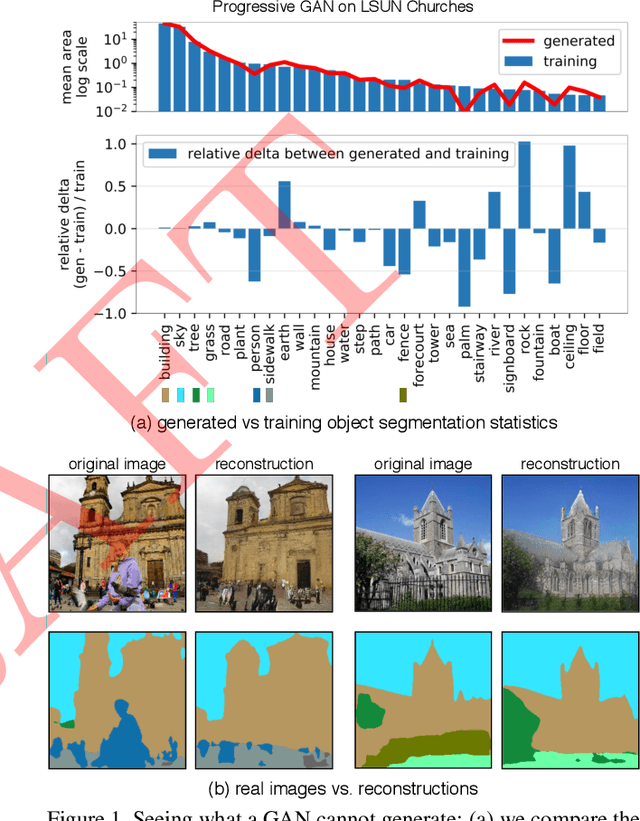

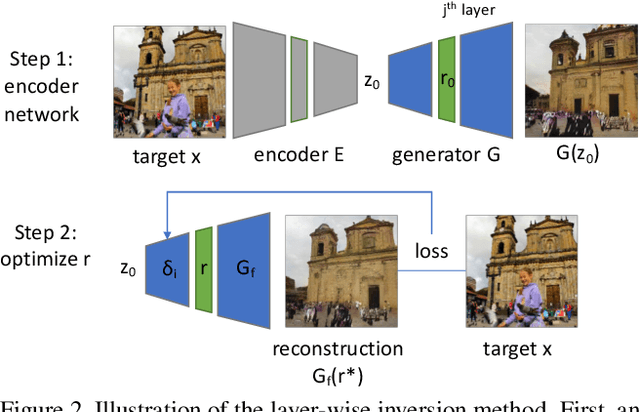
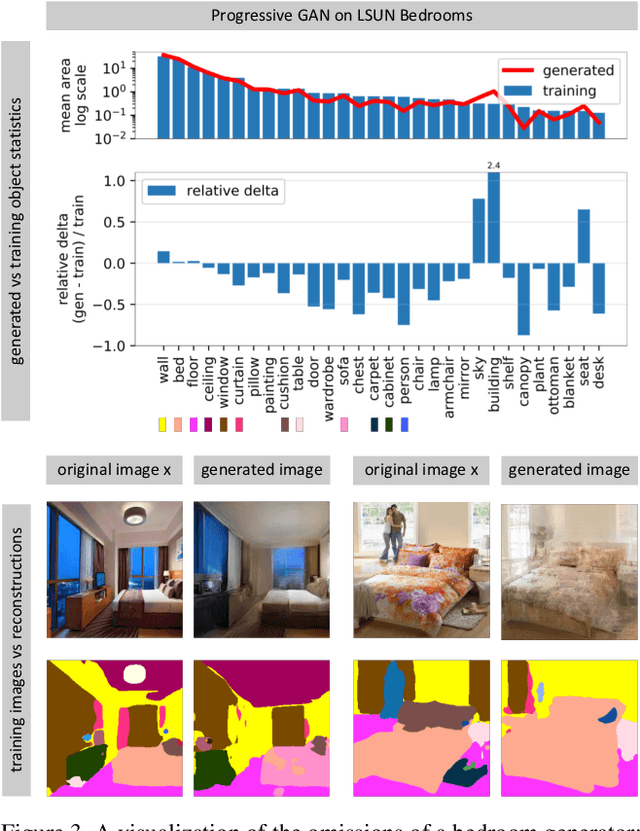
Despite the success of Generative Adversarial Networks (GANs), mode collapse remains a serious issue during GAN training. To date, little work has focused on understanding and quantifying which modes have been dropped by a model. In this work, we visualize mode collapse at both the distribution level and the instance level. First, we deploy a semantic segmentation network to compare the distribution of segmented objects in the generated images with the target distribution in the training set. Differences in statistics reveal object classes that are omitted by a GAN. Second, given the identified omitted object classes, we visualize the GAN's omissions directly. In particular, we compare specific differences between individual photos and their approximate inversions by a GAN. To this end, we relax the problem of inversion and solve the tractable problem of inverting a GAN layer instead of the entire generator. Finally, we use this framework to analyze several recent GANs trained on multiple datasets and identify their typical failure cases.
Competitive Collaboration: Joint Unsupervised Learning of Depth, Camera Motion, Optical Flow and Motion Segmentation
Oct 07, 2018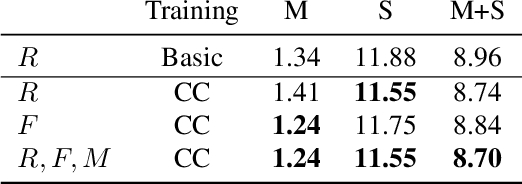
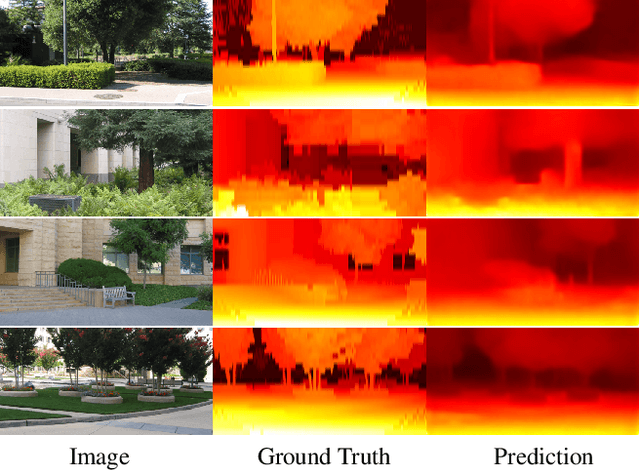
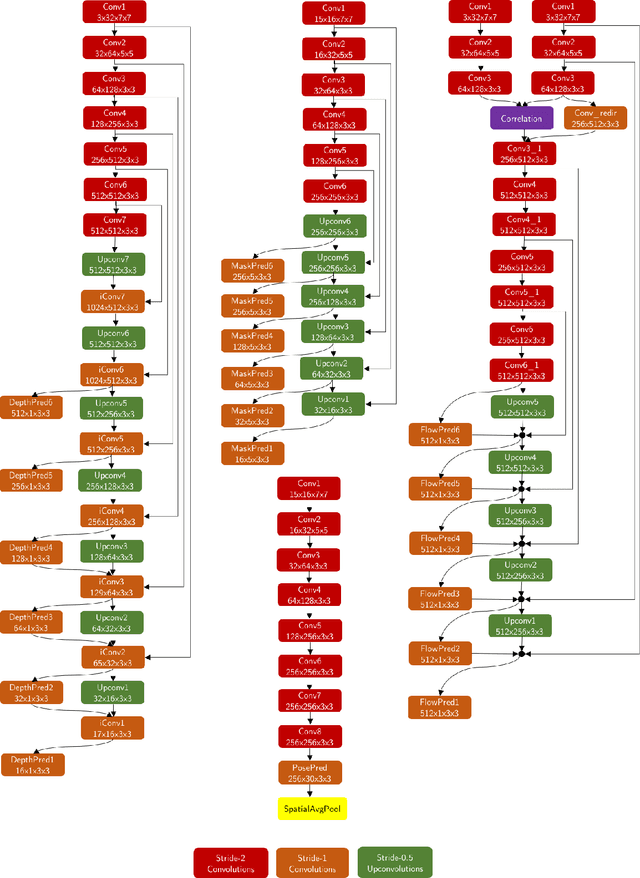
We address the unsupervised learning of several interconnected problems in low-level vision: single view depth prediction, camera motion estimation, optical flow and segmentation of a video into the static scene and moving regions. Our key insight is that these four fundamental vision problems are coupled and, consequently, learning to solve them together simplifies the problem because the solutions can reinforce each other by exploiting known geometric constraints. In order to model geometric constraints, we introduce Competitive Collaboration, a framework that facilitates competition and collaboration between neural networks. We go beyond previous work by exploiting geometry more explicitly and segmenting the scene into static and moving regions. Competitive Collaboration works much like expectation-maximization but with neural networks that act as adversaries, competing to explain pixels that correspond to static or moving regions, and as collaborators through a moderator that assigns pixels to be either static or independently moving. Our novel method integrates all these problems in a common framework and simultaneously reasons about the segmentation of the scene into moving objects and the static background, the camera motion, depth of the static scene structure, and the optical flow of moving objects. Our model is trained without any supervision and achieves state of the art results amongst unsupervised methods.
Temporal Interpolation as an Unsupervised Pretraining Task for Optical Flow Estimation
Sep 21, 2018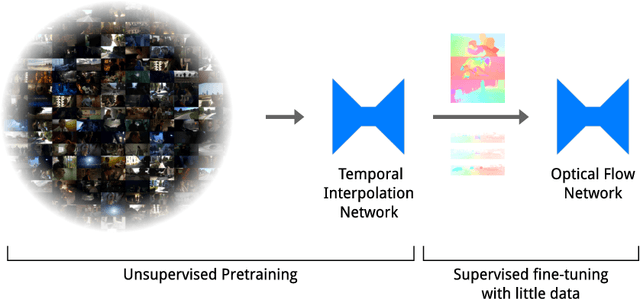

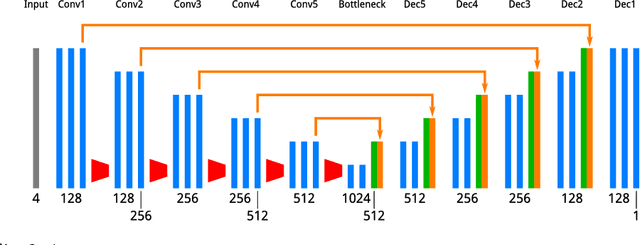
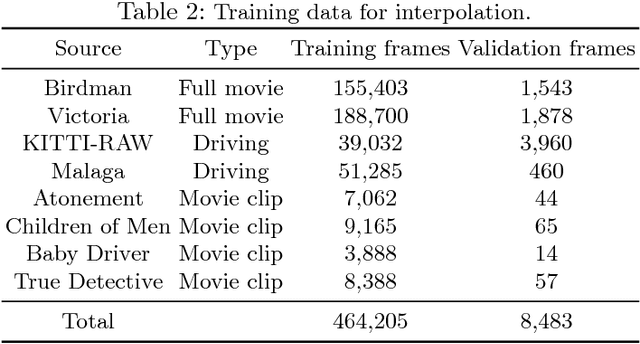
The difficulty of annotating training data is a major obstacle to using CNNs for low-level tasks in video. Synthetic data often does not generalize to real videos, while unsupervised methods require heuristic losses. Proxy tasks can overcome these issues, and start by training a network for a task for which annotation is easier or which can be trained unsupervised. The trained network is then fine-tuned for the original task using small amounts of ground truth data. Here, we investigate frame interpolation as a proxy task for optical flow. Using real movies, we train a CNN unsupervised for temporal interpolation. Such a network implicitly estimates motion, but cannot handle untextured regions. By fine-tuning on small amounts of ground truth flow, the network can learn to fill in homogeneous regions and compute full optical flow fields. Using this unsupervised pre-training, our network outperforms similar architectures that were trained supervised using synthetic optical flow.
Optical Flow in Mostly Rigid Scenes
May 03, 2017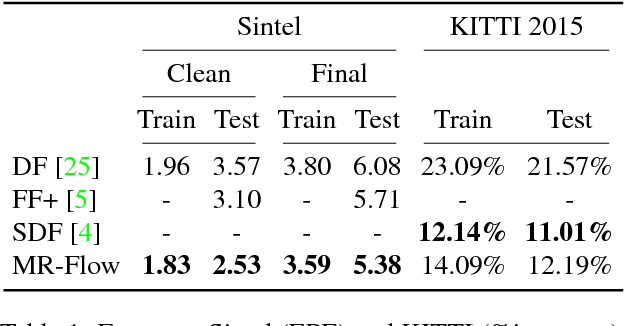
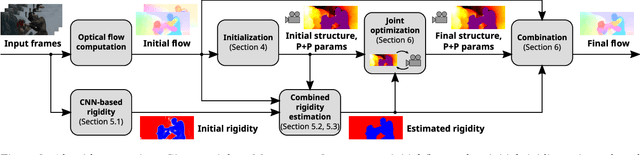


The optical flow of natural scenes is a combination of the motion of the observer and the independent motion of objects. Existing algorithms typically focus on either recovering motion and structure under the assumption of a purely static world or optical flow for general unconstrained scenes. We combine these approaches in an optical flow algorithm that estimates an explicit segmentation of moving objects from appearance and physical constraints. In static regions we take advantage of strong constraints to jointly estimate the camera motion and the 3D structure of the scene over multiple frames. This allows us to also regularize the structure instead of the motion. Our formulation uses a Plane+Parallax framework, which works even under small baselines, and reduces the motion estimation to a one-dimensional search problem, resulting in more accurate estimation. In moving regions the flow is treated as unconstrained, and computed with an existing optical flow method. The resulting Mostly-Rigid Flow (MR-Flow) method achieves state-of-the-art results on both the MPI-Sintel and KITTI-2015 benchmarks.