 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Diffusion Models with Transformers
Dec 19, 2022We explore a new class of diffusion models based on the transformer architecture. We train latent diffusion models of images, replacing the commonly-used U-Net backbone with a transformer that operates on latent patches. We analyze the scalability of our Diffusion Transformers (DiTs) through the lens of forward pass complexity as measured by Gflops. We find that DiTs with higher Gflops -- through increased transformer depth/width or increased number of input tokens -- consistently have lower FID. In addition to possessing good scalability properties, our largest DiT-XL/2 models outperform all prior diffusion models on the class-conditional ImageNet 512x512 and 256x256 benchmarks, achieving a state-of-the-art FID of 2.27 on the latter.
Learning to Learn with Generative Models of Neural Network Checkpoints
Sep 26, 2022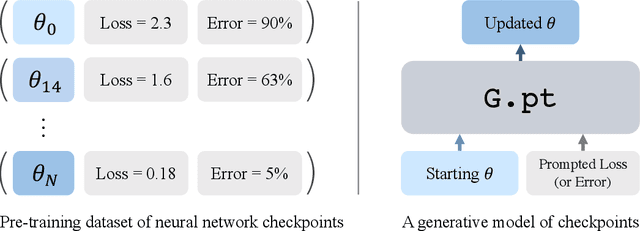
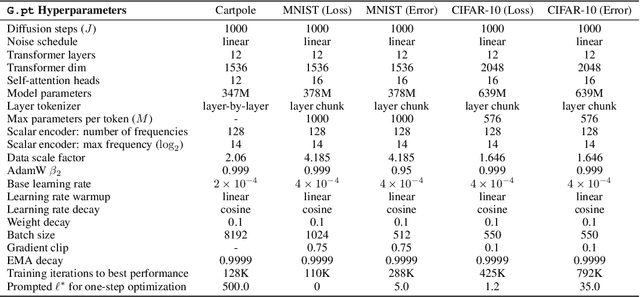
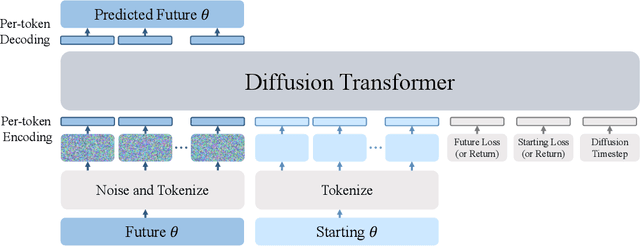

We explore a data-driven approach for learning to optimize neural networks. We construct a dataset of neural network checkpoints and train a generative model on the parameters. In particular, our model is a conditional diffusion transformer that, given an initial input parameter vector and a prompted loss, error, or return, predicts the distribution over parameter updates that achieve the desired metric. At test time, it can optimize neural networks with unseen parameters for downstream tasks in just one update. We find that our approach successfully generates parameters for a wide range of loss prompts. Moreover, it can sample multimodal parameter solutions and has favorable scaling properties. We apply our method to different neural network architectures and tasks in supervised and reinforcement learning.
GAN-Supervised Dense Visual Alignment
Dec 09, 2021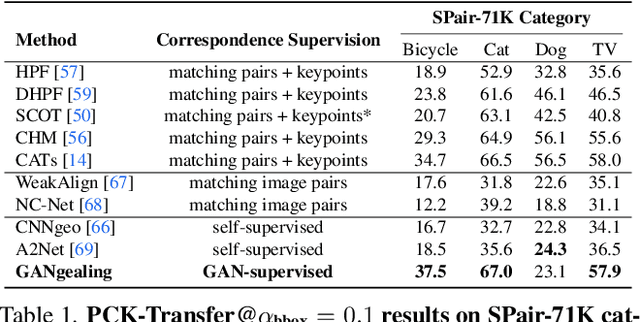
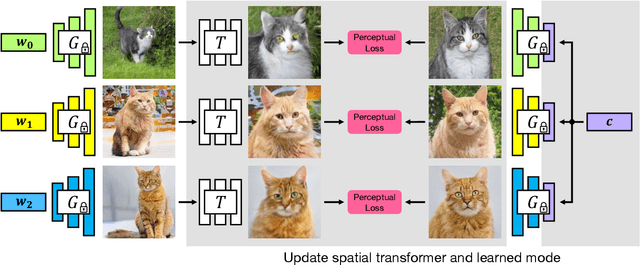


We propose GAN-Supervised Learning, a framework for learning discriminative models and their GAN-generated training data jointly end-to-end. We apply our framework to the dense visual alignment problem. Inspired by the classic Congealing method, our GANgealing algorithm trains a Spatial Transformer to map random samples from a GAN trained on unaligned data to a common, jointly-learned target mode. We show results on eight datasets, all of which demonstrate our method successfully aligns complex data and discovers dense correspondences. GANgealing significantly outperforms past self-supervised correspondence algorithms and performs on-par with (and sometimes exceeds) state-of-the-art supervised correspondence algorithms on several datasets -- without making use of any correspondence supervision or data augmentation and despite being trained exclusively on GAN-generated data. For precise correspondence, we improve upon state-of-the-art supervised methods by as much as $3\times$. We show applications of our method for augmented reality, image editing and automated pre-processing of image datasets for downstream GAN training.
The Hessian Penalty: A Weak Prior for Unsupervised Disentanglement
Aug 24, 2020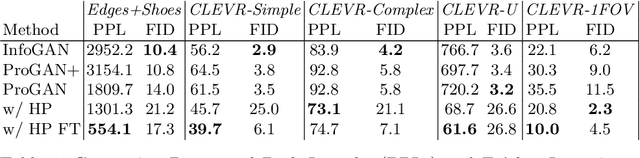

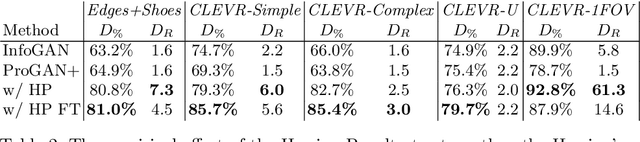

Existing disentanglement methods for deep generative models rely on hand-picked priors and complex encoder-based architectures. In this paper, we propose the Hessian Penalty, a simple regularization term that encourages the Hessian of a generative model with respect to its input to be diagonal. We introduce a model-agnostic, unbiased stochastic approximation of this term based on Hutchinson's estimator to compute it efficiently during training. Our method can be applied to a wide range of deep generators with just a few lines of code. We show that training with the Hessian Penalty often causes axis-aligned disentanglement to emerge in latent space when applied to ProGAN on several datasets. Additionally, we use our regularization term to identify interpretable directions in BigGAN's latent space in an unsupervised fashion. Finally, we provide empirical evidence that the Hessian Penalty encourages substantial shrinkage when applied to over-parameterized latent spaces.
Semantic Photo Manipulation with a Generative Image Prior
May 15, 2020

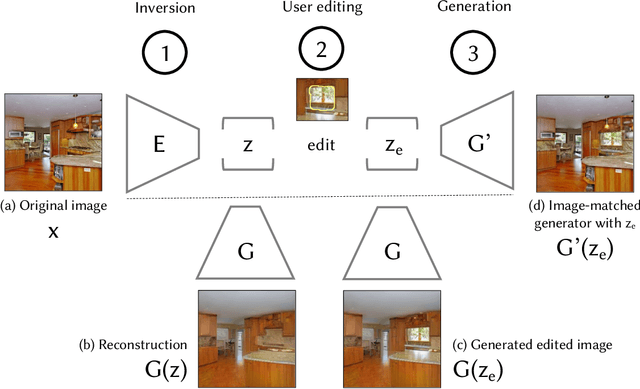
Despite the recent success of GANs in synthesizing images conditioned on inputs such as a user sketch, text, or semantic labels, manipulating the high-level attributes of an existing natural photograph with GANs is challenging for two reasons. First, it is hard for GANs to precisely reproduce an input image. Second, after manipulation, the newly synthesized pixels often do not fit the original image. In this paper, we address these issues by adapting the image prior learned by GANs to image statistics of an individual image. Our method can accurately reconstruct the input image and synthesize new content, consistent with the appearance of the input image. We demonstrate our interactive system on several semantic image editing tasks, including synthesizing new objects consistent with background, removing unwanted objects, and changing the appearance of an object. Quantitative and qualitative comparisons against several existing methods demonstrate the effectiveness of our method.
* SIGGRAPH 2019
Seeing What a GAN Cannot Generate
Oct 24, 2019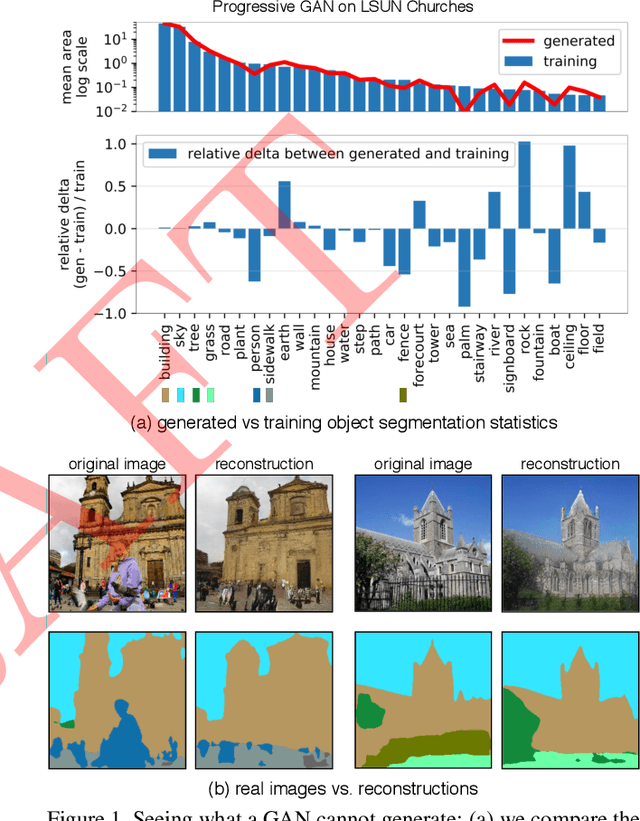

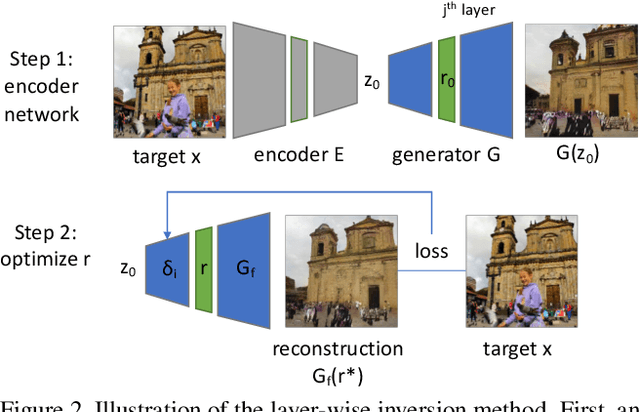
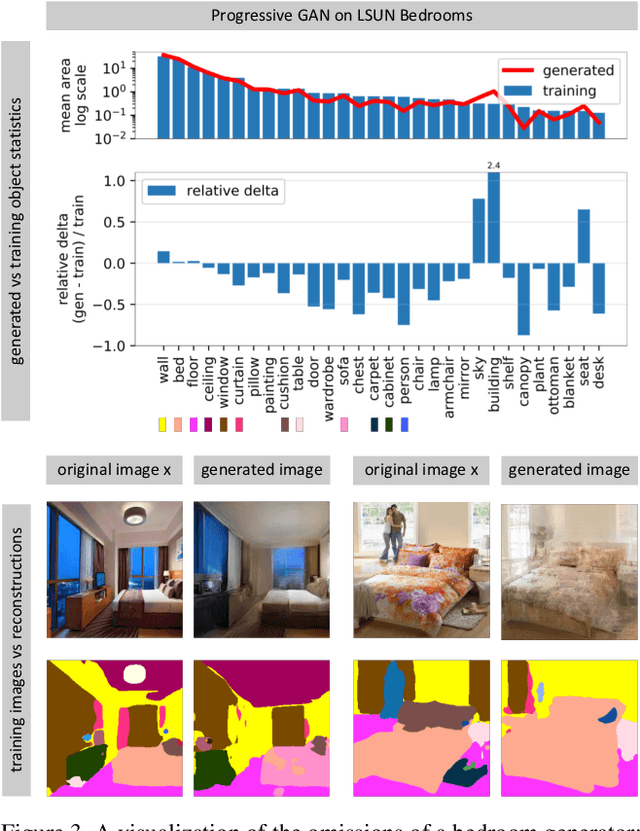
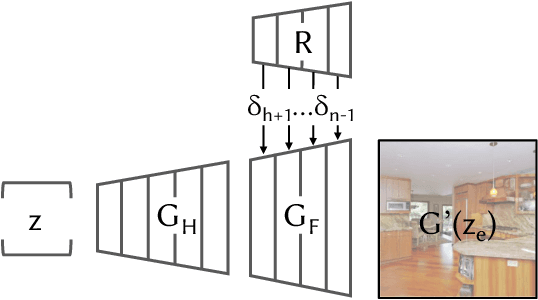
Despite the success of Generative Adversarial Networks (GANs), mode collapse remains a serious issue during GAN training. To date, little work has focused on understanding and quantifying which modes have been dropped by a model. In this work, we visualize mode collapse at both the distribution level and the instance level. First, we deploy a semantic segmentation network to compare the distribution of segmented objects in the generated images with the target distribution in the training set. Differences in statistics reveal object classes that are omitted by a GAN. Second, given the identified omitted object classes, we visualize the GAN's omissions directly. In particular, we compare specific differences between individual photos and their approximate inversions by a GAN. To this end, we relax the problem of inversion and solve the tractable problem of inverting a GAN layer instead of the entire generator. Finally, we use this framework to analyze several recent GANs trained on multiple datasets and identify their typical failure cases.