 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Autoregressive Pre-training from Videos
Jan 09, 2025



We empirically study autoregressive pre-training from videos. To perform our study, we construct a series of autoregressive video models, called Toto. We treat videos as sequences of visual tokens and train transformer models to autoregressively predict future tokens. Our models are pre-trained on a diverse dataset of videos and images comprising over 1 trillion visual tokens. We explore different architectural, training, and inference design choices. We evaluate the learned visual representations on a range of downstream tasks including image recognition, video classification, object tracking, and robotics. Our results demonstrate that, despite minimal inductive biases, autoregressive pre-training leads to competitive performance across all benchmarks. Finally, we find that scaling our video models results in similar scaling curves to those seen in language models, albeit with a different rate. More details at https://brjathu.github.io/toto/
Learning Humanoid Locomotion over Challenging Terrain
Oct 04, 2024



Humanoid robots can, in principle, use their legs to go almost anywhere. Developing controllers capable of traversing diverse terrains, however, remains a considerable challenge. Classical controllers are hard to generalize broadly while the learning-based methods have primarily focused on gentle terrains. Here, we present a learning-based approach for blind humanoid locomotion capable of traversing challenging natural and man-made terrain. Our method uses a transformer model to predict the next action based on the history of proprioceptive observations and actions. The model is first pre-trained on a dataset of flat-ground trajectories with sequence modeling, and then fine-tuned on uneven terrain using reinforcement learning. We evaluate our model on a real humanoid robot across a variety of terrains, including rough, deformable, and sloped surfaces. The model demonstrates robust performance, in-context adaptation, and emergent terrain representations. In real-world case studies, our humanoid robot successfully traversed over 4 miles of hiking trails in Berkeley and climbed some of the steepest streets in San Francisco.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
Humanoid Locomotion as Next Token Prediction
Feb 29, 2024



We cast real-world humanoid control as a next token prediction problem, akin to predicting the next word in language. Our model is a causal transformer trained via autoregressive prediction of sensorimotor trajectories. To account for the multi-modal nature of the data, we perform prediction in a modality-aligned way, and for each input token predict the next token from the same modality. This general formulation enables us to leverage data with missing modalities, like video trajectories without actions. We train our model on a collection of simulated trajectories coming from prior neural network policies, model-based controllers, motion capture data, and YouTube videos of humans. We show that our model enables a full-sized humanoid to walk in San Francisco zero-shot. Our model can transfer to the real world even when trained on only 27 hours of walking data, and can generalize to commands not seen during training like walking backward. These findings suggest a promising path toward learning challenging real-world control tasks by generative modeling of sensorimotor trajectories.
Reconstructing Hands in 3D with Transformers
Dec 08, 2023
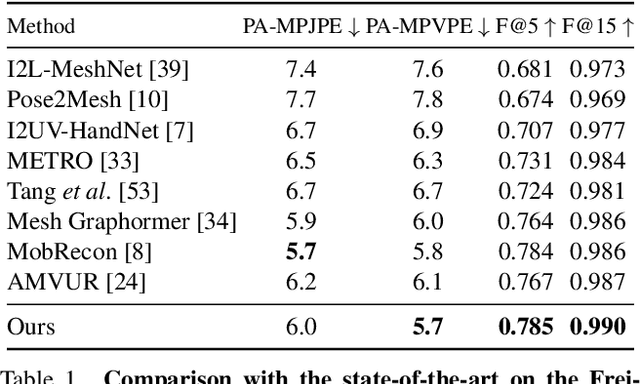
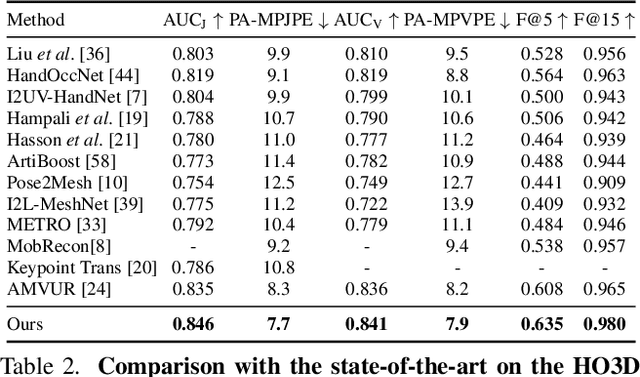
We present an approach that can reconstruct hands in 3D from monocular input. Our approach for Hand Mesh Recovery, HaMeR, follows a fully transformer-based architecture and can analyze hands with significantly increased accuracy and robustness compared to previous work. The key to HaMeR's success lies in scaling up both the data used for training and the capacity of the deep network for hand reconstruction. For training data, we combine multiple datasets that contain 2D or 3D hand annotations. For the deep model, we use a large scale Vision Transformer architecture. Our final model consistently outperforms the previous baselines on popular 3D hand pose benchmarks. To further evaluate the effect of our design in non-controlled settings, we annotate existing in-the-wild datasets with 2D hand keypoint annotations. On this newly collected dataset of annotations, HInt, we demonstrate significant improvements over existing baselines. We make our code, data and models available on the project website: https://geopavlakos.github.io/hamer/.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Robot Learning with Sensorimotor Pre-training
Jun 16, 2023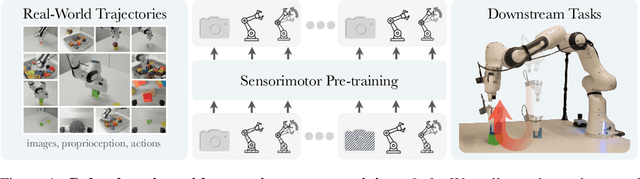



We present a self-supervised sensorimotor pre-training approach for robotics. Our model, called RPT, is a Transformer that operates on sequences of sensorimotor tokens. Given a sequence of camera images, proprioceptive robot states, and past actions, we encode the interleaved sequence into tokens, mask out a random subset, and train a model to predict the masked-out content. We hypothesize that if the robot can predict the missing content it has acquired a good model of the physical world that can enable it to act. RPT is designed to operate on latent visual representations which makes prediction tractable, enables scaling to 10x larger models, and 10 Hz inference on a real robot. To evaluate our approach, we collect a dataset of 20,000 real-world trajectories over 9 months using a combination of motion planning and model-based grasping algorithms. We find that pre-training on this data consistently outperforms training from scratch, leads to 2x improvements in the block stacking task, and has favorable scaling properties.
Learning Humanoid Locomotion with Transformers
Mar 06, 2023We present a sim-to-real learning-based approach for real-world humanoid locomotion. Our controller is a causal Transformer trained by autoregressive prediction of future actions from the history of observations and actions. We hypothesize that the observation-action history contains useful information about the world that a powerful Transformer model can use to adapt its behavior in-context, without updating its weights. We do not use state estimation, dynamics models, trajectory optimization, reference trajectories, or pre-computed gait libraries. Our controller is trained with large-scale model-free reinforcement learning on an ensemble of randomized environments in simulation and deployed to the real world in a zero-shot fashion. We evaluate our approach in high-fidelity simulation and successfully deploy it to the real robot as well. To the best of our knowledge, this is the first demonstration of a fully learning-based method for real-world full-sized humanoid locomotion.
Learning to Imitate Object Interactions from Internet Videos
Nov 23, 2022



We study the problem of imitating object interactions from Internet videos. This requires understanding the hand-object interactions in 4D, spatially in 3D and over time, which is challenging due to mutual hand-object occlusions. In this paper we make two main contributions: (1) a novel reconstruction technique RHOV (Reconstructing Hands and Objects from Videos), which reconstructs 4D trajectories of both the hand and the object using 2D image cues and temporal smoothness constraints; (2) a system for imitating object interactions in a physics simulator with reinforcement learning. We apply our reconstruction technique to 100 challenging Internet videos. We further show that we can successfully imitate a range of different object interactions in a physics simulator. Our object-centric approach is not limited to human-like end-effectors and can learn to imitate object interactions using different embodiments, like a robotic arm with a parallel jaw gripper.
Real-World Robot Learning with Masked Visual Pre-training
Oct 06, 2022

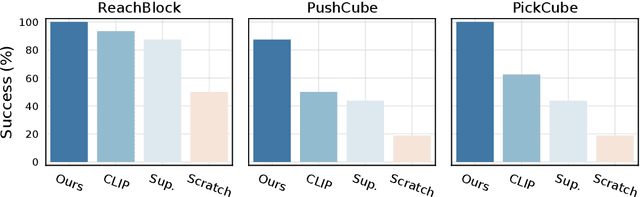
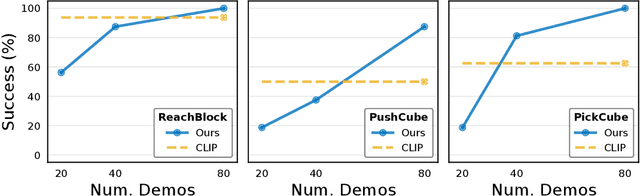
In this work, we explore self-supervised visual pre-training on images from diverse, in-the-wild videos for real-world robotic tasks. Like prior work, our visual representations are pre-trained via a masked autoencoder (MAE), frozen, and then passed into a learnable control module. Unlike prior work, we show that the pre-trained representations are effective across a range of real-world robotic tasks and embodiments. We find that our encoder consistently outperforms CLIP (up to 75%), supervised ImageNet pre-training (up to 81%), and training from scratch (up to 81%). Finally, we train a 307M parameter vision transformer on a massive collection of 4.5M images from the Internet and egocentric videos, and demonstrate clearly the benefits of scaling visual pre-training for robot learning.