 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-aware Adaptive Supervised Network with Limited Medical Annotations
Jan 02, 2026Medical image segmentation faces critical challenges in semi-supervised learning scenarios due to severe annotation scarcity requiring expert radiological knowledge, significant inter-annotator variability across different viewpoints and expertise levels, and inadequate multi-scale feature integration for precise boundary delineation in complex anatomical structures. Existing semi-supervised methods demonstrate substantial performance degradation compared to fully supervised approaches, particularly in small target segmentation and boundary refinement tasks. To address these fundamental challenges, we propose SASNet (Scale-aware Adaptive Supervised Network), a dual-branch architecture that leverages both low-level and high-level feature representations through novel scale-aware adaptive reweight mechanisms. Our approach introduces three key methodological innovations, including the Scale-aware Adaptive Reweight strategy that dynamically weights pixel-wise predictions using temporal confidence accumulation, the View Variance Enhancement mechanism employing 3D Fourier domain transformations to simulate annotation variability, and segmentation-regression consistency learning through signed distance map algorithms for enhanced boundary precision. These innovations collectively address the core limitations of existing semi-supervised approaches by integrating spatial, temporal, and geometric consistency principles within a unified optimization framework. Comprehensive evaluation across LA, Pancreas-CT, and BraTS datasets demonstrates that SASNet achieves superior performance with limited labeled data, surpassing state-of-the-art semi-supervised methods while approaching fully supervised performance levels. The source code for SASNet is available at https://github.com/HUANGLIZI/SASNet.
FoundationMotion: Auto-Labeling and Reasoning about Spatial Movement in Videos
Dec 11, 2025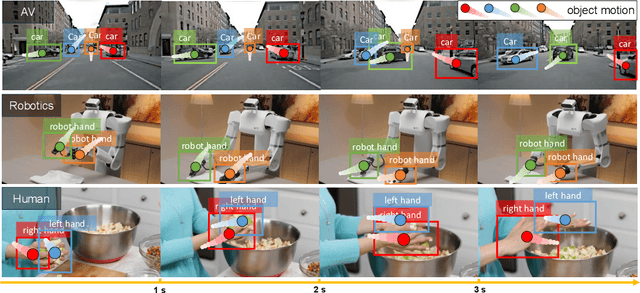
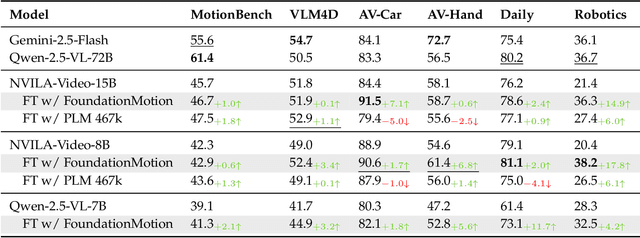
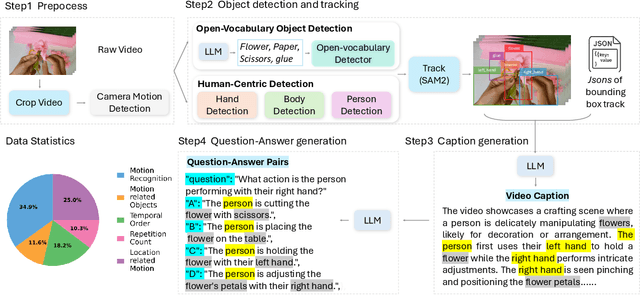

Motion understanding is fundamental to physical reasoning, enabling models to infer dynamics and predict future states. However, state-of-the-art models still struggle on recent motion benchmarks, primarily due to the scarcity of large-scale, fine-grained motion datasets. Existing motion datasets are often constructed from costly manual annotation, severely limiting scalability. To address this challenge, we introduce FoundationMotion, a fully automated data curation pipeline that constructs large-scale motion datasets. Our approach first detects and tracks objects in videos to extract their trajectories, then leverages these trajectories and video frames with Large Language Models (LLMs) to generate fine-grained captions and diverse question-answer pairs about motion and spatial reasoning. Using datasets produced by this pipeline, we fine-tune open-source models including NVILA-Video-15B and Qwen2.5-7B, achieving substantial improvements in motion understanding without compromising performance on other tasks. Notably, our models outperform strong closed-source baselines like Gemini-2.5 Flash and large open-source models such as Qwen2.5-VL-72B across diverse motion understanding datasets and benchmarks. FoundationMotion thus provides a scalable solution for curating fine-grained motion datasets that enable effective fine-tuning of diverse models to enhance motion understanding and spatial reasoning capabilities.
Slot-Level Robotic Placement via Visual Imitation from Single Human Video
Apr 02, 2025



The majority of modern robot learning methods focus on learning a set of pre-defined tasks with limited or no generalization to new tasks. Extending the robot skillset to novel tasks involves gathering an extensive amount of training data for additional tasks. In this paper, we address the problem of teaching new tasks to robots using human demonstration videos for repetitive tasks (e.g., packing). This task requires understanding the human video to identify which object is being manipulated (the pick object) and where it is being placed (the placement slot). In addition, it needs to re-identify the pick object and the placement slots during inference along with the relative poses to enable robot execution of the task. To tackle this, we propose SLeRP, a modular system that leverages several advanced visual foundation models and a novel slot-level placement detector Slot-Net, eliminating the need for expensive video demonstrations for training. We evaluate our system using a new benchmark of real-world videos. The evaluation results show that SLeRP outperforms several baselines and can be deployed on a real robot.
STPNet: Scale-aware Text Prompt Network for Medical Image Segmentation
Apr 02, 2025Accurate segmentation of lesions plays a critical role in medical image analysis and diagnosis. Traditional segmentation approaches that rely solely on visual features often struggle with the inherent uncertainty in lesion distribution and size. To address these issues, we propose STPNet, a Scale-aware Text Prompt Network that leverages vision-language modeling to enhance medical image segmentation. Our approach utilizes multi-scale textual descriptions to guide lesion localization and employs retrieval-segmentation joint learning to bridge the semantic gap between visual and linguistic modalities. Crucially, STPNet retrieves relevant textual information from a specialized medical text repository during training, eliminating the need for text input during inference while retaining the benefits of cross-modal learning. We evaluate STPNet on three datasets: COVID-Xray, COVID-CT, and Kvasir-SEG. Experimental results show that our vision-language approach outperforms state-of-the-art segmentation methods, demonstrating the effectiveness of incorporating textual semantic knowledge into medical image analysis. The code has been made publicly on https://github.com/HUANGLIZI/STPNet.
A topology-preserving three-stage framework for fully-connected coronary artery extraction
Apr 02, 2025Coronary artery extraction is a crucial prerequisite for computer-aided diagnosis of coronary artery disease. Accurately extracting the complete coronary tree remains challenging due to several factors, including presence of thin distal vessels, tortuous topological structures, and insufficient contrast. These issues often result in over-segmentation and under-segmentation in current segmentation methods. To address these challenges, we propose a topology-preserving three-stage framework for fully-connected coronary artery extraction. This framework includes vessel segmentation, centerline reconnection, and missing vessel reconstruction. First, we introduce a new centerline enhanced loss in the segmentation process. Second, for the broken vessel segments, we further propose a regularized walk algorithm to integrate distance, probabilities predicted by a centerline classifier, and directional cosine similarity, for reconnecting the centerlines. Third, we apply implicit neural representation and implicit modeling, to reconstruct the geometric model of the missing vessels. Experimental results show that our proposed framework outperforms existing methods, achieving Dice scores of 88.53\% and 85.07\%, with Hausdorff Distances (HD) of 1.07mm and 1.63mm on ASOCA and PDSCA datasets, respectively. Code will be available at https://github.com/YH-Qiu/CorSegRec.
An Intra- and Cross-frame Topological Consistency Scheme for Semi-supervised Atherosclerotic Coronary Plaque Segmentation
Jan 14, 2025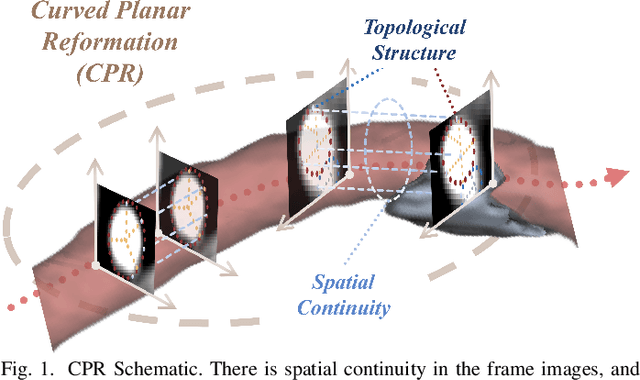
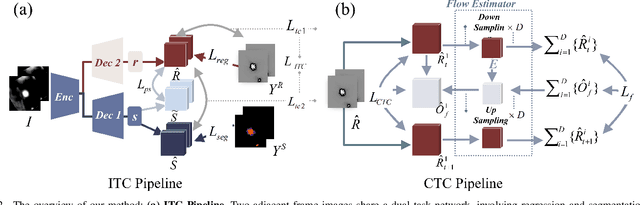
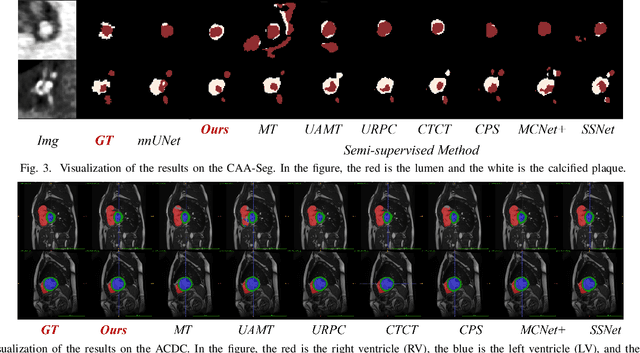
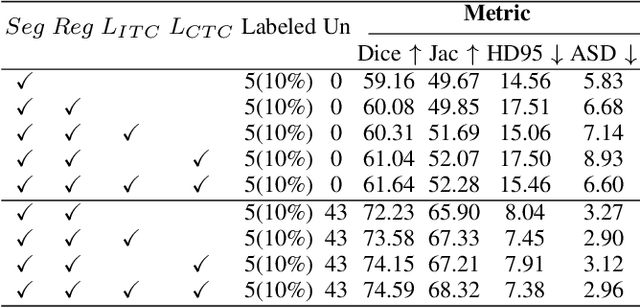
Enhancing the precision of segmenting coronary atherosclerotic plaques from CT Angiography (CTA) images is pivotal for advanced Coronary Atherosclerosis Analysis (CAA), which distinctively relies on the analysis of vessel cross-section images reconstructed via Curved Planar Reformation. This task presents significant challenges due to the indistinct boundaries and structures of plaques and blood vessels, leading to the inadequate performance of current deep learning models, compounded by the inherent difficulty in annotating such complex data. To address these issues, we propose a novel dual-consistency semi-supervised framework that integrates Intra-frame Topological Consistency (ITC) and Cross-frame Topological Consistency (CTC) to leverage labeled and unlabeled data. ITC employs a dual-task network for simultaneous segmentation mask and Skeleton-aware Distance Transform (SDT) prediction, achieving similar prediction of topology structure through consistency constraint without additional annotations. Meanwhile, CTC utilizes an unsupervised estimator for analyzing pixel flow between skeletons and boundaries of adjacent frames, ensuring spatial continuity. Experiments on two CTA datasets show that our method surpasses existing semi-supervised methods and approaches the performance of supervised methods on CAA. In addition, our method also performs better than other methods on the ACDC dataset, demonstrating its generalization.
ScribFormer: Transformer Makes CNN Work Better for Scribble-based Medical Image Segmentation
Feb 03, 2024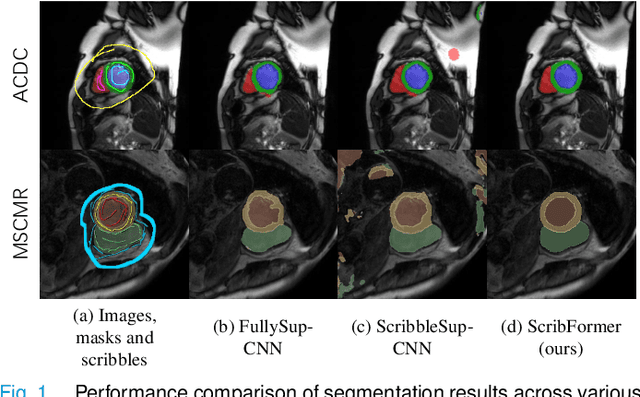
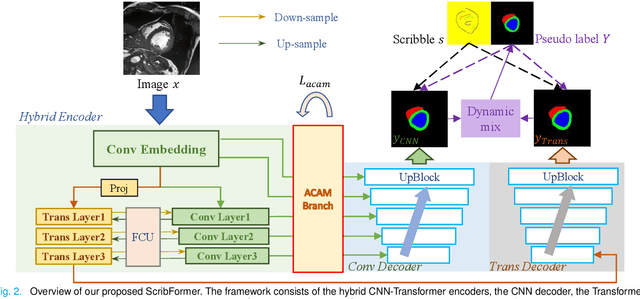
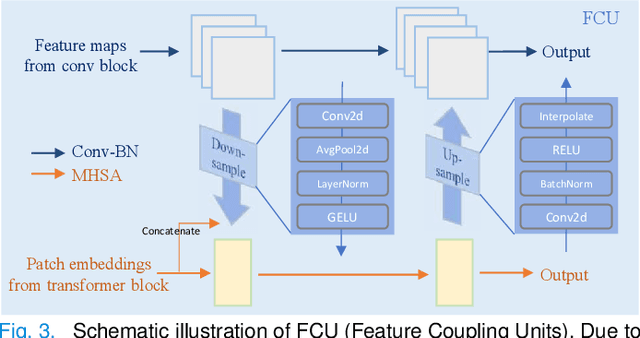
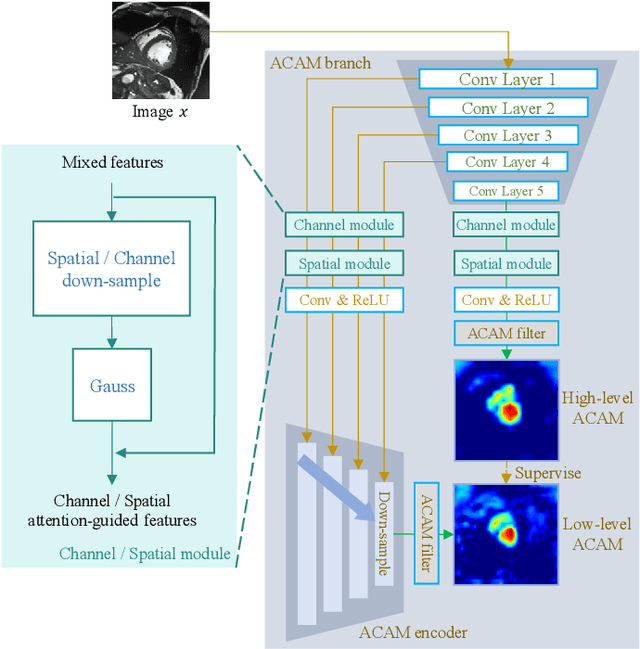
Most recent scribble-supervised segmentation methods commonly adopt a CNN framework with an encoder-decoder architecture. Despite its multiple benefits, this framework generally can only capture small-range feature dependency for the convolutional layer with the local receptive field, which makes it difficult to learn global shape information from the limited information provided by scribble annotations. To address this issue, this paper proposes a new CNN-Transformer hybrid solution for scribble-supervised medical image segmentation called ScribFormer. The proposed ScribFormer model has a triple-branch structure, i.e., the hybrid of a CNN branch, a Transformer branch, and an attention-guided class activation map (ACAM) branch. Specifically, the CNN branch collaborates with the Transformer branch to fuse the local features learned from CNN with the global representations obtained from Transformer, which can effectively overcome limitations of existing scribble-supervised segmentation methods. Furthermore, the ACAM branch assists in unifying the shallow convolution features and the deep convolution features to improve model's performance further. Extensive experiments on two public datasets and one private dataset show that our ScribFormer has superior performance over the state-of-the-art scribble-supervised segmentation methods, and achieves even better results than the fully-supervised segmentation methods. The code is released at https://github.com/HUANGLIZI/ScribFormer.
Reconstructing Hands in 3D with Transformers
Dec 08, 2023
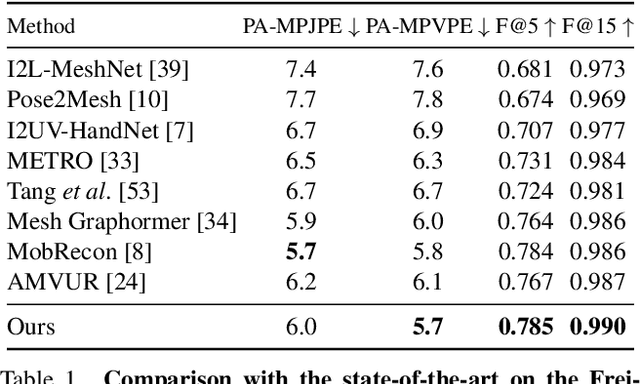
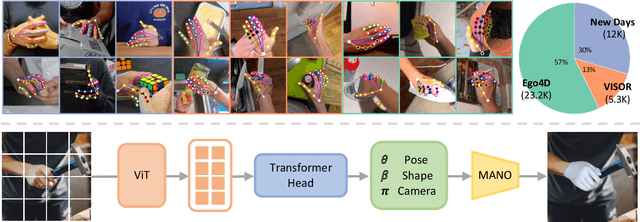
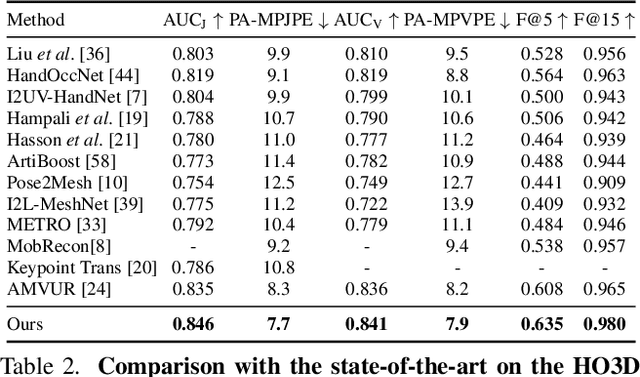
We present an approach that can reconstruct hands in 3D from monocular input. Our approach for Hand Mesh Recovery, HaMeR, follows a fully transformer-based architecture and can analyze hands with significantly increased accuracy and robustness compared to previous work. The key to HaMeR's success lies in scaling up both the data used for training and the capacity of the deep network for hand reconstruction. For training data, we combine multiple datasets that contain 2D or 3D hand annotations. For the deep model, we use a large scale Vision Transformer architecture. Our final model consistently outperforms the previous baselines on popular 3D hand pose benchmarks. To further evaluate the effect of our design in non-controlled settings, we annotate existing in-the-wild datasets with 2D hand keypoint annotations. On this newly collected dataset of annotations, HInt, we demonstrate significant improvements over existing baselines. We make our code, data and models available on the project website: https://geopavlakos.github.io/hamer/.
ScribbleVC: Scribble-supervised Medical Image Segmentation with Vision-Class Embedding
Jul 30, 2023Medical image segmentation plays a critical role in clinical decision-making, treatment planning, and disease monitoring. However, accurate segmentation of medical images is challenging due to several factors, such as the lack of high-quality annotation, imaging noise, and anatomical differences across patients. In addition, there is still a considerable gap in performance between the existing label-efficient methods and fully-supervised methods. To address the above challenges, we propose ScribbleVC, a novel framework for scribble-supervised medical image segmentation that leverages vision and class embeddings via the multimodal information enhancement mechanism. In addition, ScribbleVC uniformly utilizes the CNN features and Transformer features to achieve better visual feature extraction. The proposed method combines a scribble-based approach with a segmentation network and a class-embedding module to produce accurate segmentation masks. We evaluate ScribbleVC on three benchmark datasets and compare it with state-of-the-art methods. The experimental results demonstrate that our method outperforms existing approaches in terms of accuracy, robustness, and efficiency. The datasets and code are released on GitHub.
Coarse-to-Fine Covid-19 Segmentation via Vision-Language Alignment
Mar 01, 2023Segmentation of COVID-19 lesions can assist physicians in better diagnosis and treatment of COVID-19. However, there are few relevant studies due to the lack of detailed information and high-quality annotation in the COVID-19 dataset. To solve the above problem, we propose C2FVL, a Coarse-to-Fine segmentation framework via Vision-Language alignment to merge text information containing the number of lesions and specific locations of image information. The introduction of text information allows the network to achieve better prediction results on challenging datasets. We conduct extensive experiments on two COVID-19 datasets including chest X-ray and CT, and the results demonstrate that our proposed method outperforms other state-of-the-art segmentation methods.