 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTPNet: Scale-aware Text Prompt Network for Medical Image Segmentation
Apr 02, 2025Accurate segmentation of lesions plays a critical role in medical image analysis and diagnosis. Traditional segmentation approaches that rely solely on visual features often struggle with the inherent uncertainty in lesion distribution and size. To address these issues, we propose STPNet, a Scale-aware Text Prompt Network that leverages vision-language modeling to enhance medical image segmentation. Our approach utilizes multi-scale textual descriptions to guide lesion localization and employs retrieval-segmentation joint learning to bridge the semantic gap between visual and linguistic modalities. Crucially, STPNet retrieves relevant textual information from a specialized medical text repository during training, eliminating the need for text input during inference while retaining the benefits of cross-modal learning. We evaluate STPNet on three datasets: COVID-Xray, COVID-CT, and Kvasir-SEG. Experimental results show that our vision-language approach outperforms state-of-the-art segmentation methods, demonstrating the effectiveness of incorporating textual semantic knowledge into medical image analysis. The code has been made publicly on https://github.com/HUANGLIZI/STPNet.
ScribFormer: Transformer Makes CNN Work Better for Scribble-based Medical Image Segmentation
Feb 03, 2024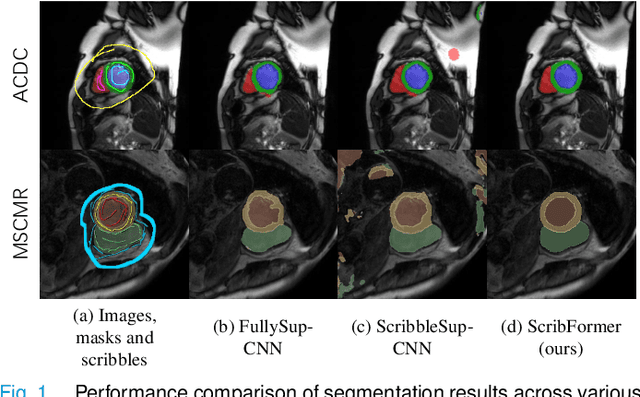
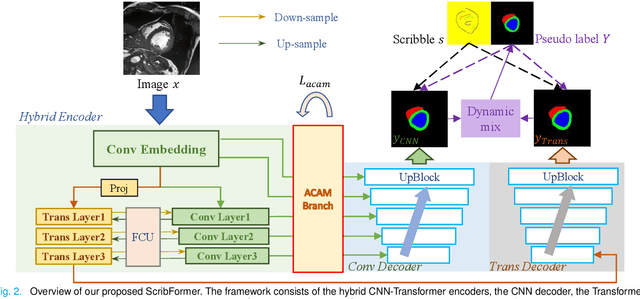
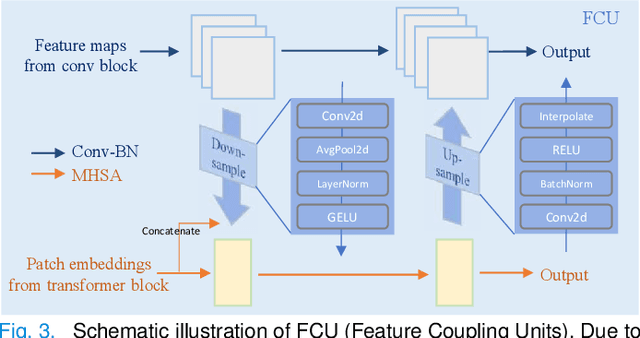
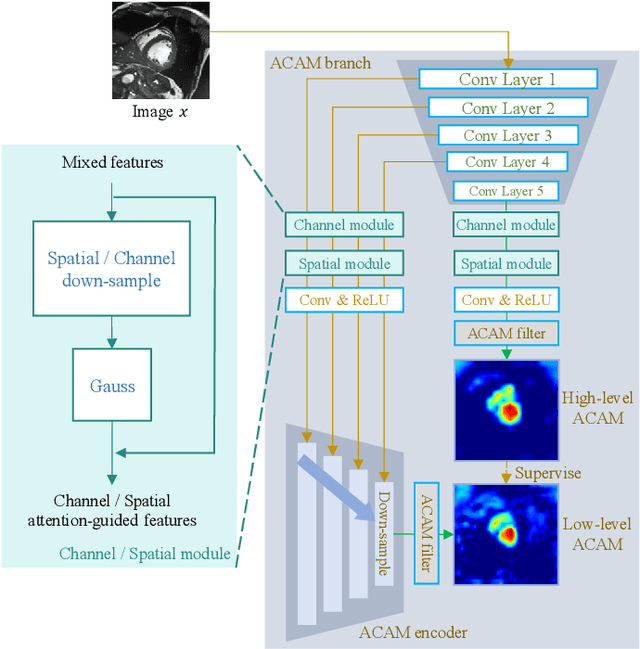
Most recent scribble-supervised segmentation methods commonly adopt a CNN framework with an encoder-decoder architecture. Despite its multiple benefits, this framework generally can only capture small-range feature dependency for the convolutional layer with the local receptive field, which makes it difficult to learn global shape information from the limited information provided by scribble annotations. To address this issue, this paper proposes a new CNN-Transformer hybrid solution for scribble-supervised medical image segmentation called ScribFormer. The proposed ScribFormer model has a triple-branch structure, i.e., the hybrid of a CNN branch, a Transformer branch, and an attention-guided class activation map (ACAM) branch. Specifically, the CNN branch collaborates with the Transformer branch to fuse the local features learned from CNN with the global representations obtained from Transformer, which can effectively overcome limitations of existing scribble-supervised segmentation methods. Furthermore, the ACAM branch assists in unifying the shallow convolution features and the deep convolution features to improve model's performance further. Extensive experiments on two public datasets and one private dataset show that our ScribFormer has superior performance over the state-of-the-art scribble-supervised segmentation methods, and achieves even better results than the fully-supervised segmentation methods. The code is released at https://github.com/HUANGLIZI/ScribFormer.
Coarse-to-Fine Covid-19 Segmentation via Vision-Language Alignment
Mar 01, 2023Segmentation of COVID-19 lesions can assist physicians in better diagnosis and treatment of COVID-19. However, there are few relevant studies due to the lack of detailed information and high-quality annotation in the COVID-19 dataset. To solve the above problem, we propose C2FVL, a Coarse-to-Fine segmentation framework via Vision-Language alignment to merge text information containing the number of lesions and specific locations of image information. The introduction of text information allows the network to achieve better prediction results on challenging datasets. We conduct extensive experiments on two COVID-19 datasets including chest X-ray and CT, and the results demonstrate that our proposed method outperforms other state-of-the-art segmentation methods.
TFCNs: A CNN-Transformer Hybrid Network for Medical Image Segmentation
Jul 07, 2022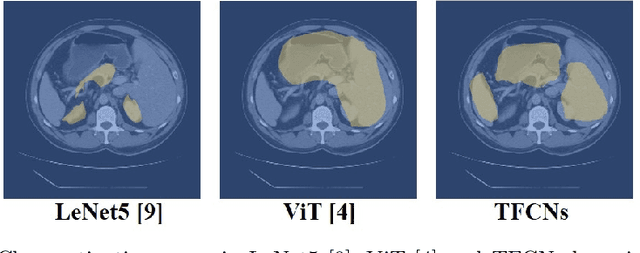
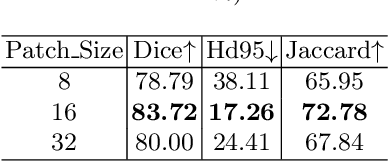
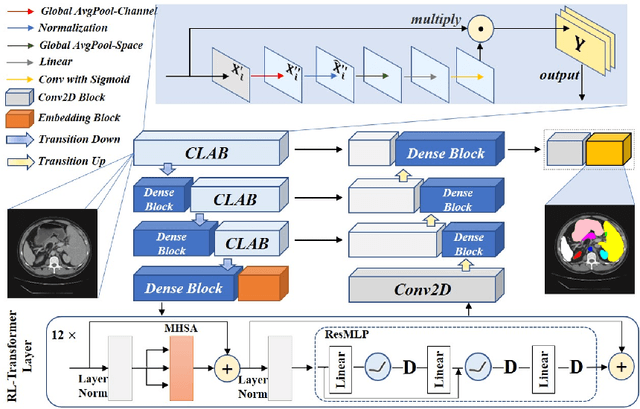
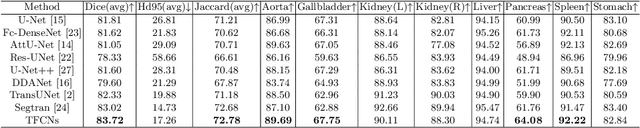
Medical image segmentation is one of the most fundamental tasks concerning medical information analysis. Various solutions have been proposed so far, including many deep learning-based techniques, such as U-Net, FC-DenseNet, etc. However, high-precision medical image segmentation remains a highly challenging task due to the existence of inherent magnification and distortion in medical images as well as the presence of lesions with similar density to normal tissues. In this paper, we propose TFCNs (Transformers for Fully Convolutional denseNets) to tackle the problem by introducing ResLinear-Transformer (RL-Transformer) and Convolutional Linear Attention Block (CLAB) to FC-DenseNet. TFCNs is not only able to utilize more latent information from the CT images for feature extraction, but also can capture and disseminate semantic features and filter non-semantic features more effectively through the CLAB module. Our experimental results show that TFCNs can achieve state-of-the-art performance with dice scores of 83.72\% on the Synapse dataset. In addition, we evaluate the robustness of TFCNs for lesion area effects on the COVID-19 public datasets. The Python code will be made publicly available on https://github.com/HUANGLIZI/TFCNs.
LViT: Language meets Vision Transformer in Medical Image Segmentation
Jun 29, 2022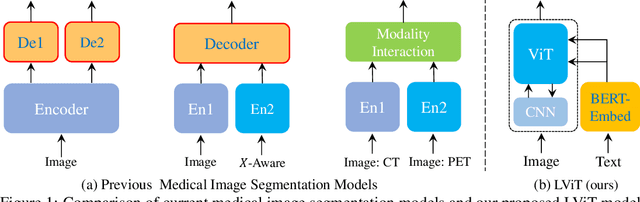
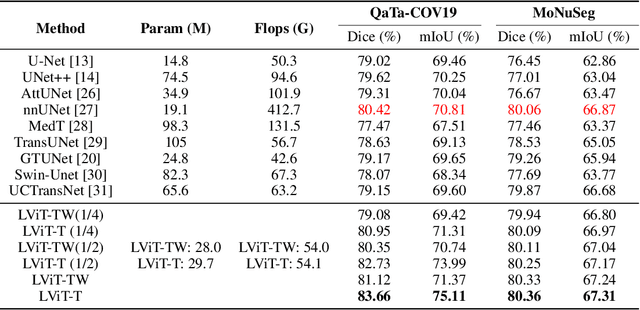
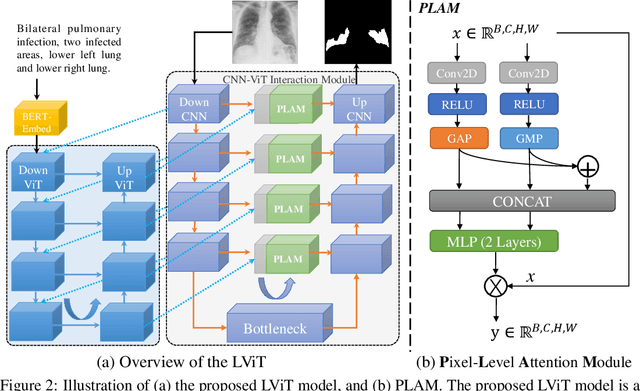
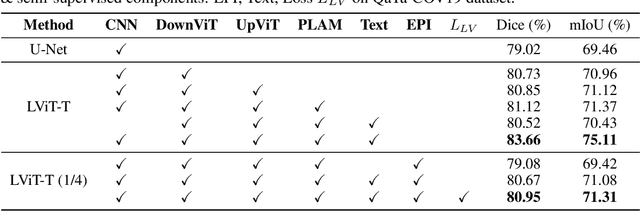
Deep learning has been widely used in medical image segmentation and other aspects. However, the performance of existing medical image segmentation models has been limited by the challenge of obtaining sufficient number of high-quality data with the high cost of data annotation. To overcome the limitation, we propose a new vision-language medical image segmentation model LViT (Language meets Vision Transformer). In our model, medical text annotation is introduced to compensate for the quality deficiency in image data. In addition, the text information can guide the generation of pseudo labels to a certain extent and further guarantee the quality of pseudo labels in semi-supervised learning. We also propose the Exponential Pseudo label Iteration mechanism (EPI) to help extend the semi-supervised version of LViT and the Pixel-Level Attention Module (PLAM) to preserve local features of images. In our model, LV (Language-Vision) loss is designed to supervise the training of unlabeled images using text information directly. To validate the performance of LViT, we construct multimodal medical segmentation datasets (image + text) containing pathological images, X-rays,etc. Experimental results show that our proposed LViT has better segmentation performance in both fully and semi-supervised conditions. Code and datasets are available at https://github.com/HUANGLIZI/LViT.