 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergizing Discriminative Exemplars and Self-Refined Experience for MLLM-based In-Context Learning in Medical Diagnosis
Mar 29, 2026General Multimodal Large Language Models (MLLMs) often underperform in capturing domain-specific nuances in medical diagnosis, trailing behind fully supervised baselines. Although fine-tuning provides a remedy, the high costs of expert annotation and massive computational overhead limit its scalability. To bridge this gap without updating the weights of the pre-trained backbone of the MLLM, we propose a Clinician Mimetic Workflow. This is a novel In-Context Learning (ICL) framework designed to synergize Discriminative Exemplar Coreset Selection (DECS) and Self-Refined Experience Summarization (SRES). Specifically, DECS simulates a clinician's ability to reference "anchor cases" by selecting discriminative visual coresets from noisy data at the computational level; meanwhile, SRES mimics the cognition and reflection in clinical diagnosis by distilling diverse rollouts into a dynamic textual Experience Bank. Extensive evaluation across all 12 datasets of the MedMNIST 2D benchmark demonstrates that our method outperforms zero-shot general and medical MLLMs. Simultaneously, it achieves performance levels comparable to fully supervised vision models and domain-specific fine-tuned MLLMs, setting a new benchmark for parameter-efficient medical in-context learning. Our code is available at an anonymous repository: https://anonymous.4open.science/r/Synergizing-Discriminative-Exemplars-and-Self-Refined-Experience-ED74.
PerformRecast: Expression and Head Pose Disentanglement for Portrait Video Editing
Mar 20, 2026This paper primarily investigates the task of expression-only portrait video performance editing based on a driving video, which plays a crucial role in animation and film industries. Most existing research mainly focuses on portrait animation, which aims to animate a static portrait image according to the facial motion from the driving video. As a consequence, it remains challenging for them to disentangle the facial expression from head pose rotation and thus lack the ability to edit facial expression independently. In this paper, we propose PerformRecast, a versatile expression-only video editing method which is dedicated to recast the performance in existing film and animation. The key insight of our method comes from the characteristics of 3D Morphable Face Model (3DMM), which models the face identity, facial expression and head pose of 3D face mesh with separate parameters. Therefore, we improve the keypoints transformation formula in previous methods to make it more consistent with 3DMM model, which achieves a better disentanglement and provides users with much more fine-grained control. Furthermore, to avoid the misalignment around the boundary of face in generated results, we decouple the facial and non-facial regions of input portrait images and pre-train a teacher model to provide separate supervision for them. Extensive experiments show that our method produces high-quality results which are more faithful to the driving video, outperforming existing methods in both controllability and efficiency. Our code, data and trained models are available at https://youku-aigc.github.io/PerformRecast.
Position-Prior-Guided Network for System Matrix Super-Resolution in Magnetic Particle Imaging
Nov 08, 2025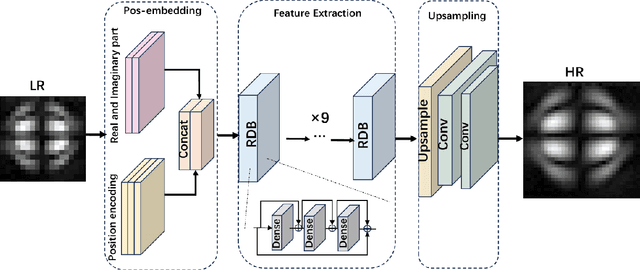
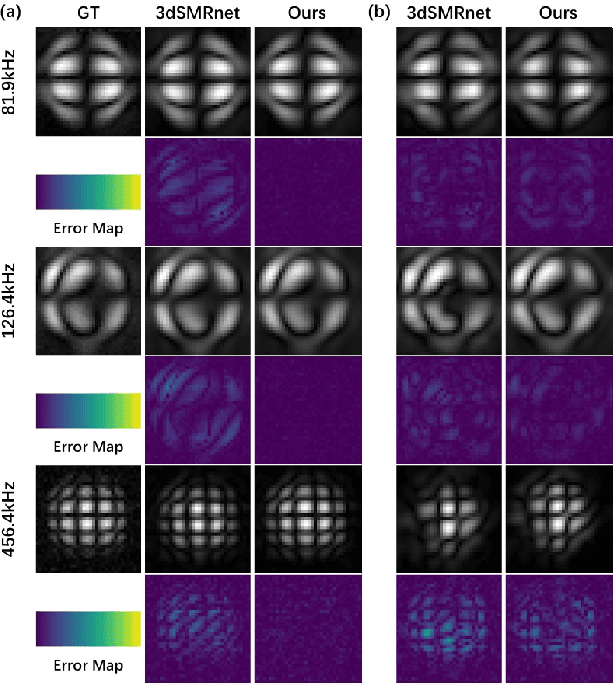
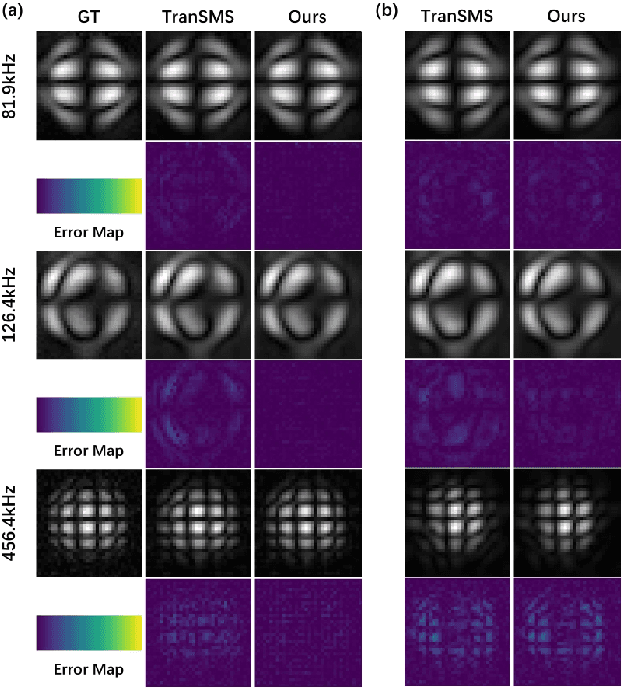
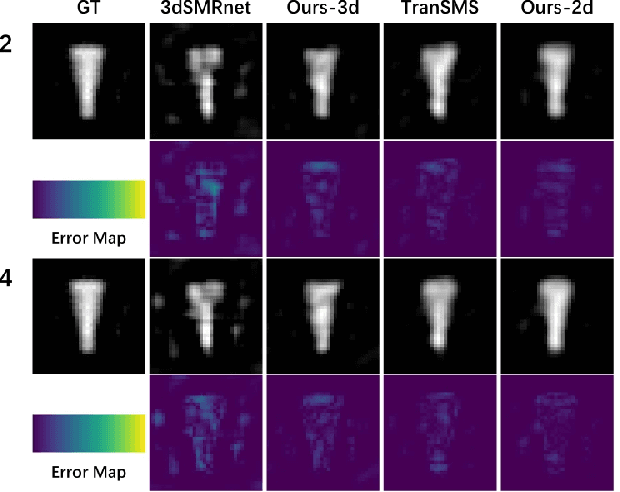
Magnetic Particle Imaging (MPI) is a novel medical imaging modality. One of the established methods for MPI reconstruction is based on the System Matrix (SM). However, the calibration of the SM is often time-consuming and requires repeated measurements whenever the system parameters change. Current methodologies utilize deep learning-based super-resolution (SR) techniques to expedite SM calibration; nevertheless, these strategies do not fully exploit physical prior knowledge associated with the SM, such as symmetric positional priors. Consequently, we integrated positional priors into existing frameworks for SM calibration. Underpinned by theoretical justification, we empirically validated the efficacy of incorporating positional priors through experiments involving both 2D and 3D SM SR methods.
Nowcast3D: Reliable precipitation nowcasting via gray-box learning
Nov 06, 2025Extreme precipitation nowcasting demands high spatiotemporal fidelity and extended lead times, yet existing approaches remain limited. Numerical Weather Prediction (NWP) and its deep-learning emulations are too slow and coarse for rapidly evolving convection, while extrapolation and purely data-driven models suffer from error accumulation and excessive smoothing. Hybrid 2D radar-based methods discard crucial vertical information, preventing accurate reconstruction of height-dependent dynamics. We introduce a gray-box, fully three-dimensional nowcasting framework that directly processes volumetric radar reflectivity and couples physically constrained neural operators with datadriven learning. The model learns vertically varying 3D advection fields under a conservative advection operator, parameterizes spatially varying diffusion, and introduces a Brownian-motion--inspired stochastic term to represent unresolved motions. A residual branch captures small-scale convective initiation and microphysical variability, while a diffusion-based stochastic module estimates uncertainty. The framework achieves more accurate forecasts up to three-hour lead time across precipitation regimes and ranked first in 57\% of cases in a blind evaluation by 160 meteorologists. By restoring full 3D dynamics with physical consistency, it offers a scalable and robust pathway for skillful and reliable nowcasting of extreme precipitation.
Chinese-Vicuna: A Chinese Instruction-following Llama-based Model
Apr 17, 2025



Chinese-Vicuna is an open-source, resource-efficient language model designed to bridge the gap in Chinese instruction-following capabilities by fine-tuning Meta's LLaMA architecture using Low-Rank Adaptation (LoRA). Targeting low-resource environments, it enables cost-effective deployment on consumer GPUs (e.g., RTX-2080Ti for 7B models) and supports domain-specific adaptation in fields like healthcare and law. By integrating hybrid datasets (BELLE and Guanaco) and 4-bit quantization (QLoRA), the model achieves competitive performance in tasks such as translation, code generation, and domain-specific Q\&A. The project provides a comprehensive toolkit for model conversion, CPU inference, and multi-turn dialogue interfaces, emphasizing accessibility for researchers and developers. Evaluations indicate competitive performance across medical tasks, multi-turn dialogue coherence, and real-time legal updates. Chinese-Vicuna's modular design, open-source ecosystem, and community-driven enhancements position it as a versatile foundation for Chinese LLM applications.
STPNet: Scale-aware Text Prompt Network for Medical Image Segmentation
Apr 02, 2025Accurate segmentation of lesions plays a critical role in medical image analysis and diagnosis. Traditional segmentation approaches that rely solely on visual features often struggle with the inherent uncertainty in lesion distribution and size. To address these issues, we propose STPNet, a Scale-aware Text Prompt Network that leverages vision-language modeling to enhance medical image segmentation. Our approach utilizes multi-scale textual descriptions to guide lesion localization and employs retrieval-segmentation joint learning to bridge the semantic gap between visual and linguistic modalities. Crucially, STPNet retrieves relevant textual information from a specialized medical text repository during training, eliminating the need for text input during inference while retaining the benefits of cross-modal learning. We evaluate STPNet on three datasets: COVID-Xray, COVID-CT, and Kvasir-SEG. Experimental results show that our vision-language approach outperforms state-of-the-art segmentation methods, demonstrating the effectiveness of incorporating textual semantic knowledge into medical image analysis. The code has been made publicly on https://github.com/HUANGLIZI/STPNet.
A Multi-Agent Framework Integrating Large Language Models and Generative AI for Accelerated Metamaterial Design
Mar 25, 2025



Metamaterials, renowned for their exceptional mechanical, electromagnetic, and thermal properties, hold transformative potential across diverse applications, yet their design remains constrained by labor-intensive trial-and-error methods and limited data interoperability. Here, we introduce CrossMatAgent--a novel multi-agent framework that synergistically integrates large language models with state-of-the-art generative AI to revolutionize metamaterial design. By orchestrating a hierarchical team of agents--each specializing in tasks such as pattern analysis, architectural synthesis, prompt engineering, and supervisory feedback--our system leverages the multimodal reasoning of GPT-4o alongside the generative precision of DALL-E 3 and a fine-tuned Stable Diffusion XL model. This integrated approach automates data augmentation, enhances design fidelity, and produces simulation- and 3D printing-ready metamaterial patterns. Comprehensive evaluations, including CLIP-based alignment, SHAP interpretability analyses, and mechanical simulations under varied load conditions, demonstrate the framework's ability to generate diverse, reproducible, and application-ready designs. CrossMatAgent thus establishes a scalable, AI-driven paradigm that bridges the gap between conceptual innovation and practical realization, paving the way for accelerated metamaterial development.
COMMA: Coordinate-aware Modulated Mamba Network for 3D Dispersed Vessel Segmentation
Mar 04, 2025



Accurate segmentation of 3D vascular structures is essential for various medical imaging applications. The dispersed nature of vascular structures leads to inherent spatial uncertainty and necessitates location awareness, yet most current 3D medical segmentation models rely on the patch-wise training strategy that usually loses this spatial context. In this study, we introduce the Coordinate-aware Modulated Mamba Network (COMMA) and contribute a manually labeled dataset of 570 cases, the largest publicly available 3D vessel dataset to date. COMMA leverages both entire and cropped patch data through global and local branches, ensuring robust and efficient spatial location awareness. Specifically, COMMA employs a channel-compressed Mamba (ccMamba) block to encode entire image data, capturing long-range dependencies while optimizing computational costs. Additionally, we propose a coordinate-aware modulated (CaM) block to enhance interactions between the global and local branches, allowing the local branch to better perceive spatial information. We evaluate COMMA on six datasets, covering two imaging modalities and five types of vascular tissues. The results demonstrate COMMA's superior performance compared to state-of-the-art methods with computational efficiency, especially in segmenting small vessels. Ablation studies further highlight the importance of our proposed modules and spatial information. The code and data will be open source at https://github.com/shigen-StoneRoot/COMMA.
Extrapolating and Decoupling Image-to-Video Generation Models: Motion Modeling is Easier Than You Think
Mar 02, 2025Image-to-Video (I2V) generation aims to synthesize a video clip according to a given image and condition (e.g., text). The key challenge of this task lies in simultaneously generating natural motions while preserving the original appearance of the images. However, current I2V diffusion models (I2V-DMs) often produce videos with limited motion degrees or exhibit uncontrollable motion that conflicts with the textual condition. To address these limitations, we propose a novel Extrapolating and Decoupling framework, which introduces model merging techniques to the I2V domain for the first time. Specifically, our framework consists of three separate stages: (1) Starting with a base I2V-DM, we explicitly inject the textual condition into the temporal module using a lightweight, learnable adapter and fine-tune the integrated model to improve motion controllability. (2) We introduce a training-free extrapolation strategy to amplify the dynamic range of the motion, effectively reversing the fine-tuning process to enhance the motion degree significantly. (3) With the above two-stage models excelling in motion controllability and degree, we decouple the relevant parameters associated with each type of motion ability and inject them into the base I2V-DM. Since the I2V-DM handles different levels of motion controllability and dynamics at various denoising time steps, we adjust the motion-aware parameters accordingly over time. Extensive qualitative and quantitative experiments have been conducted to demonstrate the superiority of our framework over existing methods.
* Accepted by CVPR2025
FSC-loss: A Frequency-domain Structure Consistency Learning Approach for Signal Data Recovery and Reconstruction
Jan 08, 2025



A core challenge for signal data recovery is to model the distribution of signal matrix (SM) data based on measured low-quality data in biomedical engineering of magnetic particle imaging (MPI). For acquiring the high-resolution (high-quality) SM, the number of meticulous measurements at numerous positions in the field-of-view proves time-consuming (measurement of a 37x37x37 SM takes about 32 hours). To improve reconstructed signal quality and shorten SM measurement time, existing methods explore to generating high-resolution SM based on time-saving measured low-resolution SM (a 9x9x9 SM just takes about 0.5 hours). However, previous methods show poor performance for high-frequency signal recovery in SM. To achieve a high-resolution SM recovery and shorten its acquisition time, we propose a frequency-domain structure consistency loss function and data component embedding strategy to model global and local structural information of SM. We adopt a transformer-based network to evaluate this function and the strategy. We evaluate our methods and state-of-the-art (SOTA) methods on the two simulation datasets and four public measured SMs in Open MPI Data. The results show that our method outperforms the SOTA methods in high-frequency structural signal recovery. Additionally, our method can recover a high-resolution SM with clear high-frequency structure based on a down-sampling factor of 16 less than 15 seconds, which accelerates the acquisition time over 60 times faster than the measurement-based HR SM with the minimum error (nRMSE=0.041). Moreover, our method is applied in our three in-house MPI systems, and boost their performance for signal reconstruction.