 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable-DiffCoder: Pushing the Frontier of Code Diffusion Large Language Model
Jan 23, 2026Diffusion-based language models (DLLMs) offer non-sequential, block-wise generation and richer data reuse compared to autoregressive (AR) models, but existing code DLLMs still lag behind strong AR baselines under comparable budgets. We revisit this setting in a controlled study and introduce Stable-DiffCoder, a block diffusion code model that reuses the Seed-Coder architecture, data, and training pipeline. To enable efficient knowledge learning and stable training, we incorporate a block diffusion continual pretraining (CPT) stage enhanced by a tailored warmup and block-wise clipped noise schedule. Under the same data and architecture, Stable-DiffCoder overall outperforms its AR counterpart on a broad suite of code benchmarks. Moreover, relying only on the CPT and supervised fine-tuning stages, Stable-DiffCoder achieves stronger performance than a wide range of \~8B ARs and DLLMs, demonstrating that diffusion-based training can improve code modeling quality beyond AR training alone. Moreover, diffusion-based any-order modeling improves structured code modeling for editing and reasoning, and through data augmentation, benefits low-resource coding languages.
Chinese-Vicuna: A Chinese Instruction-following Llama-based Model
Apr 17, 2025



Chinese-Vicuna is an open-source, resource-efficient language model designed to bridge the gap in Chinese instruction-following capabilities by fine-tuning Meta's LLaMA architecture using Low-Rank Adaptation (LoRA). Targeting low-resource environments, it enables cost-effective deployment on consumer GPUs (e.g., RTX-2080Ti for 7B models) and supports domain-specific adaptation in fields like healthcare and law. By integrating hybrid datasets (BELLE and Guanaco) and 4-bit quantization (QLoRA), the model achieves competitive performance in tasks such as translation, code generation, and domain-specific Q\&A. The project provides a comprehensive toolkit for model conversion, CPU inference, and multi-turn dialogue interfaces, emphasizing accessibility for researchers and developers. Evaluations indicate competitive performance across medical tasks, multi-turn dialogue coherence, and real-time legal updates. Chinese-Vicuna's modular design, open-source ecosystem, and community-driven enhancements position it as a versatile foundation for Chinese LLM applications.
Make LoRA Great Again: Boosting LoRA with Adaptive Singular Values and Mixture-of-Experts Optimization Alignment
Feb 26, 2025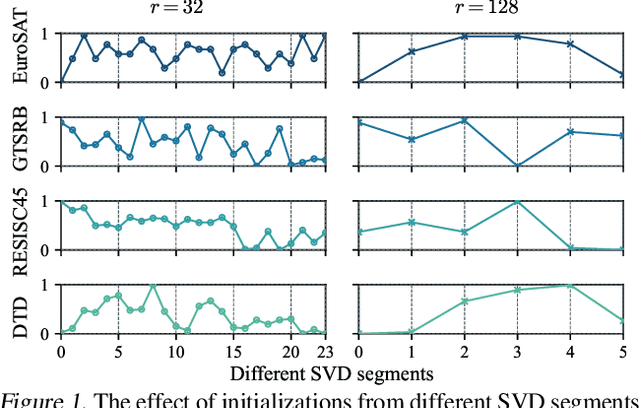
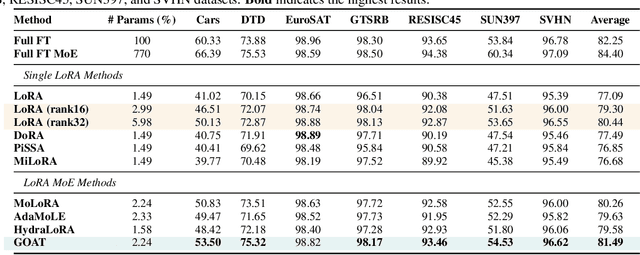
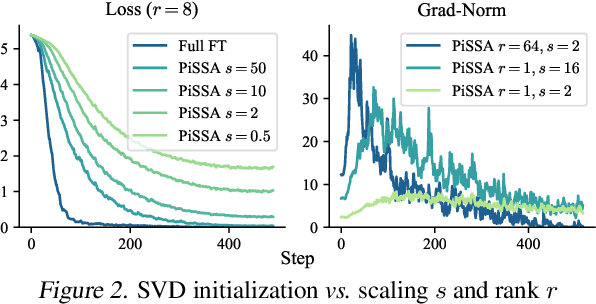
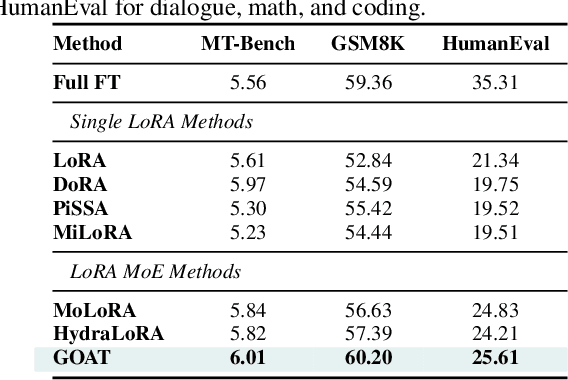
While Low-Rank Adaptation (LoRA) enables parameter-efficient fine-tuning for Large Language Models (LLMs), its performance often falls short of Full Fine-Tuning (Full FT). Current methods optimize LoRA by initializing with static singular value decomposition (SVD) subsets, leading to suboptimal leveraging of pre-trained knowledge. Another path for improving LoRA is incorporating a Mixture-of-Experts (MoE) architecture. However, weight misalignment and complex gradient dynamics make it challenging to adopt SVD prior to the LoRA MoE architecture. To mitigate these issues, we propose \underline{G}reat L\underline{o}R\underline{A} Mixture-of-Exper\underline{t} (GOAT), a framework that (1) adaptively integrates relevant priors using an SVD-structured MoE, and (2) aligns optimization with full fine-tuned MoE by deriving a theoretical scaling factor. We demonstrate that proper scaling, without modifying the architecture or training algorithms, boosts LoRA MoE's efficiency and performance. Experiments across 25 datasets, including natural language understanding, commonsense reasoning, image classification, and natural language generation, demonstrate GOAT's state-of-the-art performance, closing the gap with Full FT.
Twin-Merging: Dynamic Integration of Modular Expertise in Model Merging
Jun 17, 2024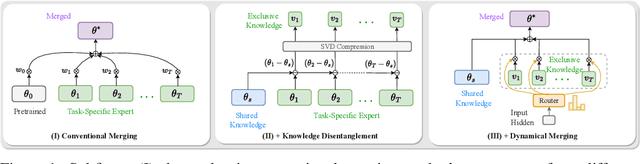
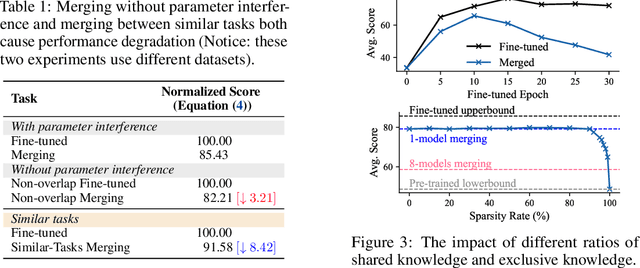
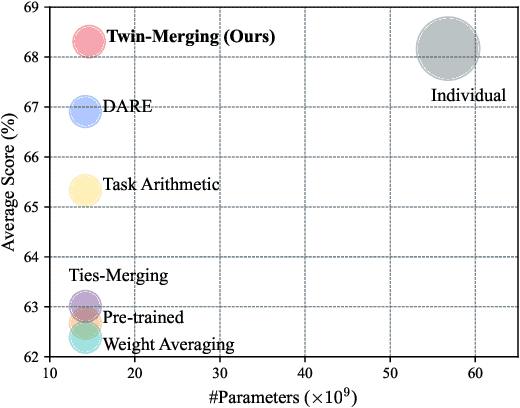
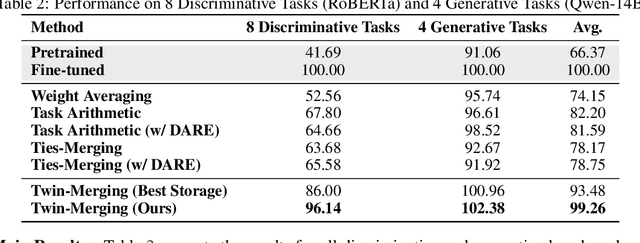
In the era of large language models, model merging is a promising way to combine multiple task-specific models into a single multitask model without extra training. However, two challenges remain: (a) interference between different models and (b) heterogeneous data during testing. Traditional model merging methods often show significant performance gaps compared to fine-tuned models due to these issues. Additionally, a one-size-fits-all model lacks flexibility for diverse test data, leading to performance degradation. We show that both shared and exclusive task-specific knowledge are crucial for merging performance, but directly merging exclusive knowledge hinders overall performance. In view of this, we propose Twin-Merging, a method that encompasses two principal stages: (1) modularizing knowledge into shared and exclusive components, with compression to reduce redundancy and enhance efficiency; (2) dynamically merging shared and task-specific knowledge based on the input. This approach narrows the performance gap between merged and fine-tuned models and improves adaptability to heterogeneous data. Extensive experiments on $12$ datasets for both discriminative and generative tasks demonstrate the effectiveness of our method, showing an average improvement of $28.34\%$ in absolute normalized score for discriminative tasks and even surpassing the fine-tuned upper bound on the generative tasks. (Our implementation is available in https://github.com/LZY-the-boys/Twin-Mergin.)
On Giant's Shoulders: Effortless Weak to Strong by Dynamic Logits Fusion
Jun 17, 2024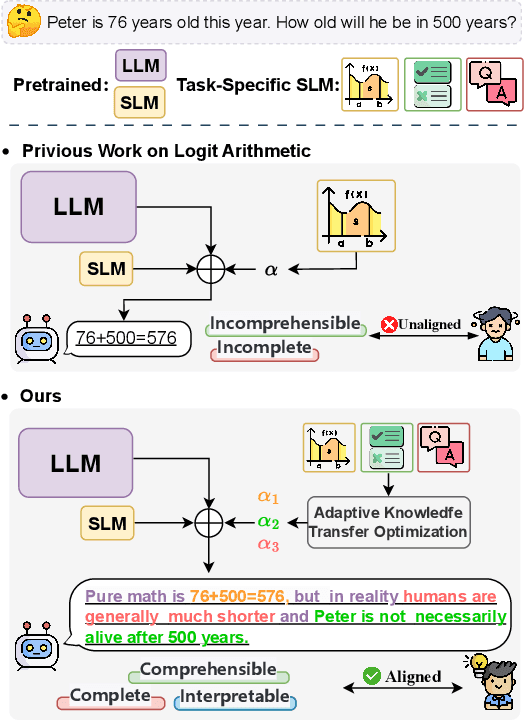
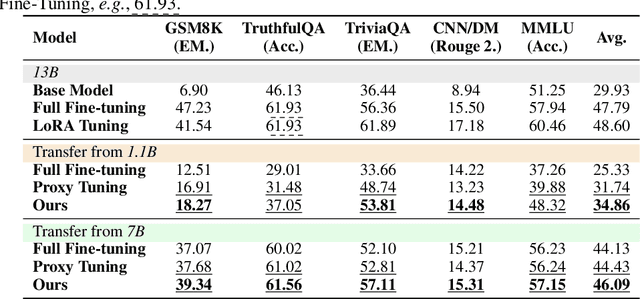
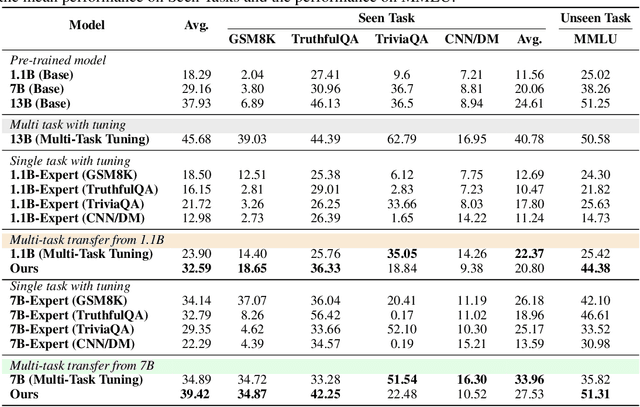
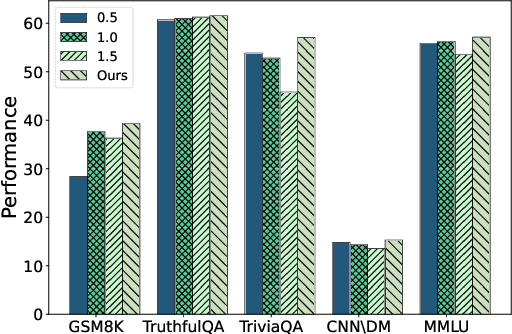
Efficient fine-tuning of large language models for task-specific applications is imperative, yet the vast number of parameters in these models makes their training increasingly challenging. Despite numerous proposals for effective methods, a substantial memory overhead remains for gradient computations during updates. \thm{Can we fine-tune a series of task-specific small models and transfer their knowledge directly to a much larger model without additional training?} In this paper, we explore weak-to-strong specialization using logit arithmetic, facilitating a direct answer to this question. Existing weak-to-strong methods often employ a static knowledge transfer ratio and a single small model for transferring complex knowledge, which leads to suboptimal performance. % To address this, To surmount these limitations, we propose a dynamic logit fusion approach that works with a series of task-specific small models, each specialized in a different task. This method adaptively allocates weights among these models at each decoding step, learning the weights through Kullback-Leibler divergence constrained optimization problems. We conduct extensive experiments across various benchmarks in both single-task and multi-task settings, achieving leading results. By transferring expertise from the 7B model to the 13B model, our method closes the performance gap by 96.4\% in single-task scenarios and by 86.3\% in multi-task scenarios compared to full fine-tuning of the 13B model. Notably, we achieve surpassing performance on unseen tasks. Moreover, we further demonstrate that our method can effortlessly integrate in-context learning for single tasks and task arithmetic for multi-task scenarios. (Our implementation is available in https://github.com/Facico/Dynamic-Logit-Fusion.)
Improving Low-resource Prompt-based Relation Representation with Multi-view Decoupling Learning
Jan 15, 2024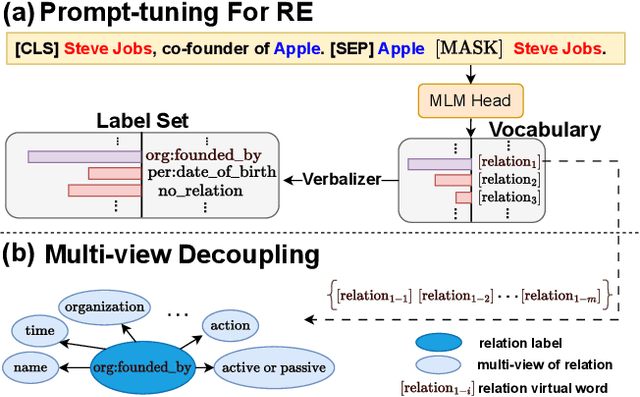
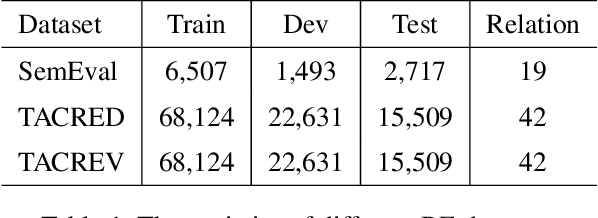
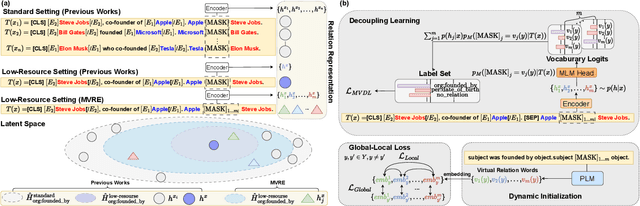
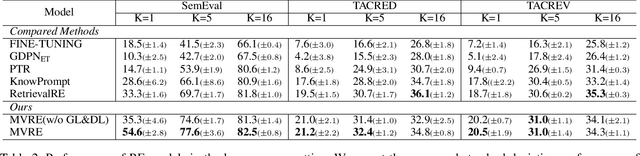
Recently, prompt-tuning with pre-trained language models (PLMs) has demonstrated the significantly enhancing ability of relation extraction (RE) tasks. However, in low-resource scenarios, where the available training data is scarce, previous prompt-based methods may still perform poorly for prompt-based representation learning due to a superficial understanding of the relation. To this end, we highlight the importance of learning high-quality relation representation in low-resource scenarios for RE, and propose a novel prompt-based relation representation method, named MVRE (\underline{M}ulti-\underline{V}iew \underline{R}elation \underline{E}xtraction), to better leverage the capacity of PLMs to improve the performance of RE within the low-resource prompt-tuning paradigm. Specifically, MVRE decouples each relation into different perspectives to encompass multi-view relation representations for maximizing the likelihood during relation inference. Furthermore, we also design a Global-Local loss and a Dynamic-Initialization method for better alignment of the multi-view relation-representing virtual words, containing the semantics of relation labels during the optimization learning process and initialization. Extensive experiments on three benchmark datasets show that our method can achieve state-of-the-art in low-resource settings.
Fusion-in-T5: Unifying Document Ranking Signals for Improved Information Retrieval
May 24, 2023



Common IR pipelines are typically cascade systems that may involve multiple rankers and/or fusion models to integrate different information step-by-step. In this paper, we propose a novel re-ranker named Fusion-in-T5 (FiT5), which integrates document text information, retrieval features, and global document information into a single unified model using templated-based input and global attention. Experiments on passage ranking benchmarks MS MARCO and TREC DL show that FiT5 significantly improves ranking performance over prior pipelines. Analyses find that through global attention, FiT5 is able to jointly utilize the ranking features via gradually attending to related documents, and thus improve the detection of subtle nuances between them. Our code will be open-sourced.
Gradient-guided Unsupervised Text Style Transfer via Contrastive Learning
Jan 23, 2022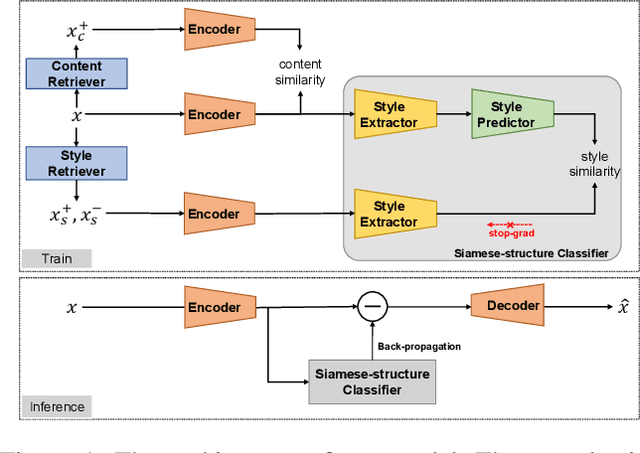


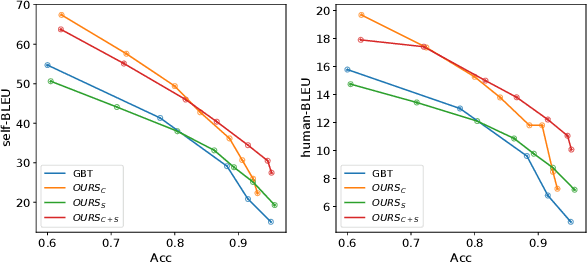
Text style transfer is a challenging text generation problem, which aims at altering the style of a given sentence to a target one while keeping its content unchanged. Since there is a natural scarcity of parallel datasets, recent works mainly focus on solving the problem in an unsupervised manner. However, previous gradient-based works generally suffer from the deficiencies as follows, namely: (1) Content migration. Previous approaches lack explicit modeling of content invariance and are thus susceptible to content shift between the original sentence and the transferred one. (2) Style misclassification. A natural drawback of the gradient-guided approaches is that the inference process is homogeneous with a line of adversarial attack, making latent optimization easily becomes an attack to the classifier due to misclassification. This leads to difficulties in achieving high transfer accuracy. To address the problems, we propose a novel gradient-guided model through a contrastive paradigm for text style transfer, to explicitly gather similar semantic sentences, and to design a siamese-structure based style classifier for alleviating such two issues, respectively. Experiments on two datasets show the effectiveness of our proposed approach, as compared to the state-of-the-arts.