 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
Chinese-Vicuna: A Chinese Instruction-following Llama-based Model
Apr 17, 2025



Chinese-Vicuna is an open-source, resource-efficient language model designed to bridge the gap in Chinese instruction-following capabilities by fine-tuning Meta's LLaMA architecture using Low-Rank Adaptation (LoRA). Targeting low-resource environments, it enables cost-effective deployment on consumer GPUs (e.g., RTX-2080Ti for 7B models) and supports domain-specific adaptation in fields like healthcare and law. By integrating hybrid datasets (BELLE and Guanaco) and 4-bit quantization (QLoRA), the model achieves competitive performance in tasks such as translation, code generation, and domain-specific Q\&A. The project provides a comprehensive toolkit for model conversion, CPU inference, and multi-turn dialogue interfaces, emphasizing accessibility for researchers and developers. Evaluations indicate competitive performance across medical tasks, multi-turn dialogue coherence, and real-time legal updates. Chinese-Vicuna's modular design, open-source ecosystem, and community-driven enhancements position it as a versatile foundation for Chinese LLM applications.
Extrapolating and Decoupling Image-to-Video Generation Models: Motion Modeling is Easier Than You Think
Mar 02, 2025Image-to-Video (I2V) generation aims to synthesize a video clip according to a given image and condition (e.g., text). The key challenge of this task lies in simultaneously generating natural motions while preserving the original appearance of the images. However, current I2V diffusion models (I2V-DMs) often produce videos with limited motion degrees or exhibit uncontrollable motion that conflicts with the textual condition. To address these limitations, we propose a novel Extrapolating and Decoupling framework, which introduces model merging techniques to the I2V domain for the first time. Specifically, our framework consists of three separate stages: (1) Starting with a base I2V-DM, we explicitly inject the textual condition into the temporal module using a lightweight, learnable adapter and fine-tune the integrated model to improve motion controllability. (2) We introduce a training-free extrapolation strategy to amplify the dynamic range of the motion, effectively reversing the fine-tuning process to enhance the motion degree significantly. (3) With the above two-stage models excelling in motion controllability and degree, we decouple the relevant parameters associated with each type of motion ability and inject them into the base I2V-DM. Since the I2V-DM handles different levels of motion controllability and dynamics at various denoising time steps, we adjust the motion-aware parameters accordingly over time. Extensive qualitative and quantitative experiments have been conducted to demonstrate the superiority of our framework over existing methods.
* Accepted by CVPR2025
Make LoRA Great Again: Boosting LoRA with Adaptive Singular Values and Mixture-of-Experts Optimization Alignment
Feb 26, 2025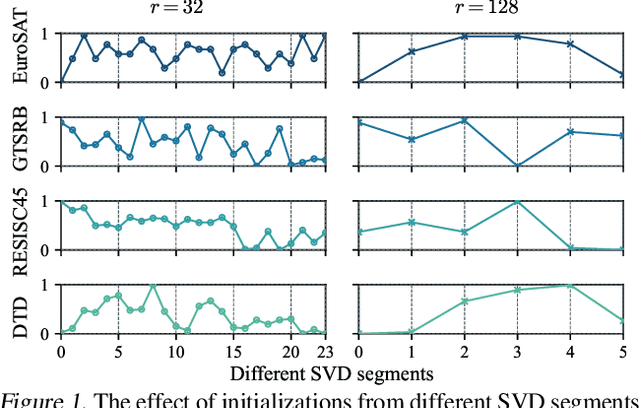
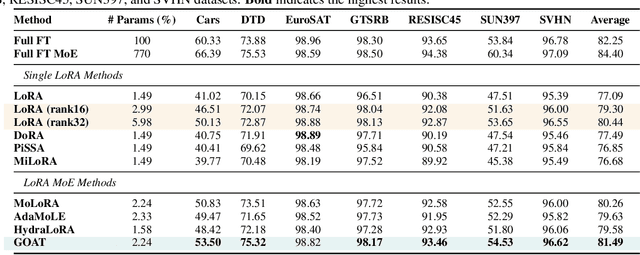
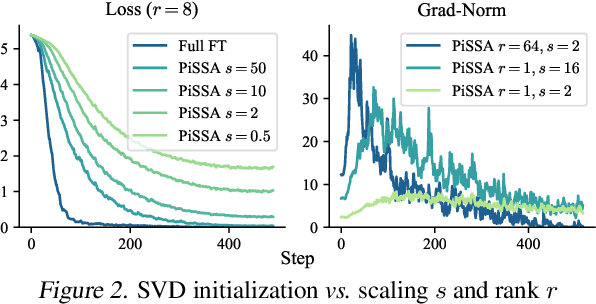
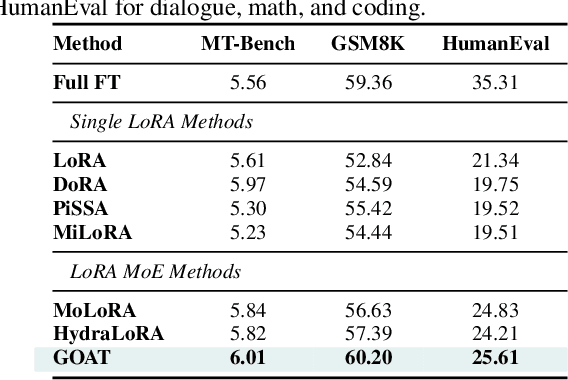
While Low-Rank Adaptation (LoRA) enables parameter-efficient fine-tuning for Large Language Models (LLMs), its performance often falls short of Full Fine-Tuning (Full FT). Current methods optimize LoRA by initializing with static singular value decomposition (SVD) subsets, leading to suboptimal leveraging of pre-trained knowledge. Another path for improving LoRA is incorporating a Mixture-of-Experts (MoE) architecture. However, weight misalignment and complex gradient dynamics make it challenging to adopt SVD prior to the LoRA MoE architecture. To mitigate these issues, we propose \underline{G}reat L\underline{o}R\underline{A} Mixture-of-Exper\underline{t} (GOAT), a framework that (1) adaptively integrates relevant priors using an SVD-structured MoE, and (2) aligns optimization with full fine-tuned MoE by deriving a theoretical scaling factor. We demonstrate that proper scaling, without modifying the architecture or training algorithms, boosts LoRA MoE's efficiency and performance. Experiments across 25 datasets, including natural language understanding, commonsense reasoning, image classification, and natural language generation, demonstrate GOAT's state-of-the-art performance, closing the gap with Full FT.
On Giant's Shoulders: Effortless Weak to Strong by Dynamic Logits Fusion
Jun 17, 2024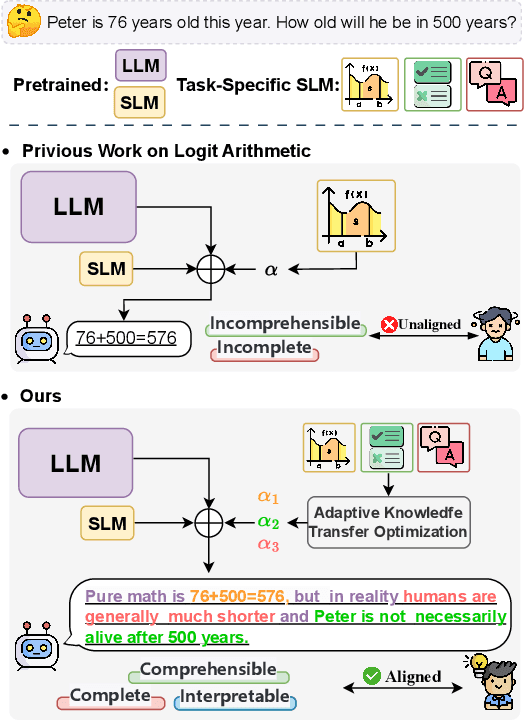
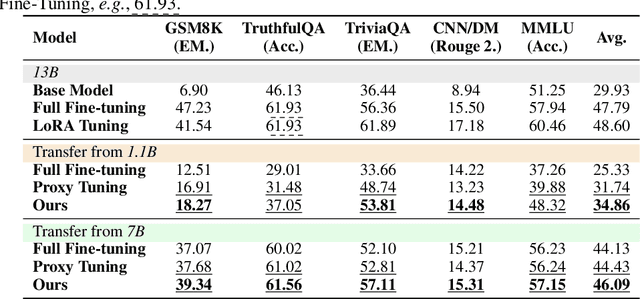
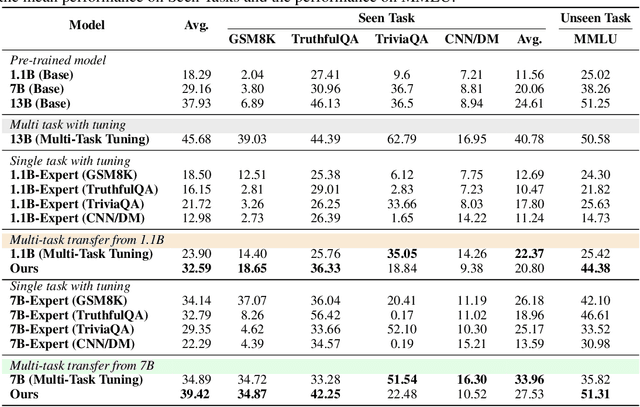
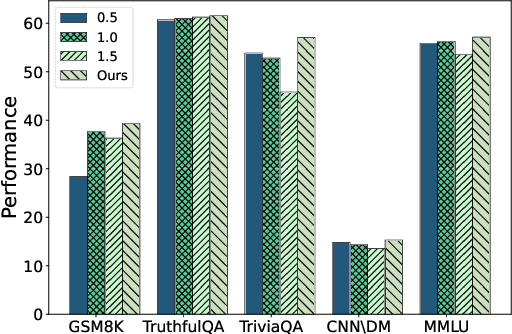
Efficient fine-tuning of large language models for task-specific applications is imperative, yet the vast number of parameters in these models makes their training increasingly challenging. Despite numerous proposals for effective methods, a substantial memory overhead remains for gradient computations during updates. \thm{Can we fine-tune a series of task-specific small models and transfer their knowledge directly to a much larger model without additional training?} In this paper, we explore weak-to-strong specialization using logit arithmetic, facilitating a direct answer to this question. Existing weak-to-strong methods often employ a static knowledge transfer ratio and a single small model for transferring complex knowledge, which leads to suboptimal performance. % To address this, To surmount these limitations, we propose a dynamic logit fusion approach that works with a series of task-specific small models, each specialized in a different task. This method adaptively allocates weights among these models at each decoding step, learning the weights through Kullback-Leibler divergence constrained optimization problems. We conduct extensive experiments across various benchmarks in both single-task and multi-task settings, achieving leading results. By transferring expertise from the 7B model to the 13B model, our method closes the performance gap by 96.4\% in single-task scenarios and by 86.3\% in multi-task scenarios compared to full fine-tuning of the 13B model. Notably, we achieve surpassing performance on unseen tasks. Moreover, we further demonstrate that our method can effortlessly integrate in-context learning for single tasks and task arithmetic for multi-task scenarios. (Our implementation is available in https://github.com/Facico/Dynamic-Logit-Fusion.)
Twin-Merging: Dynamic Integration of Modular Expertise in Model Merging
Jun 17, 2024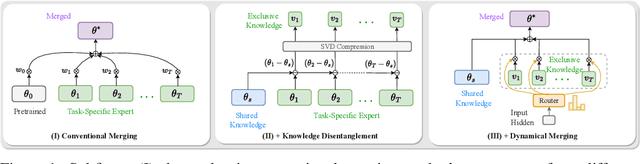
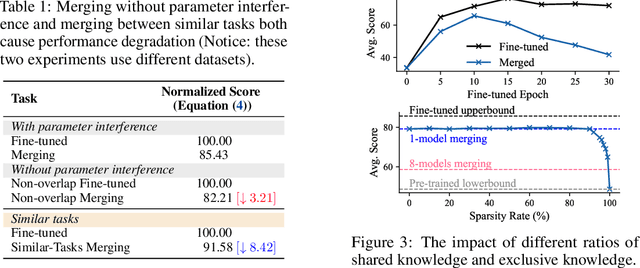
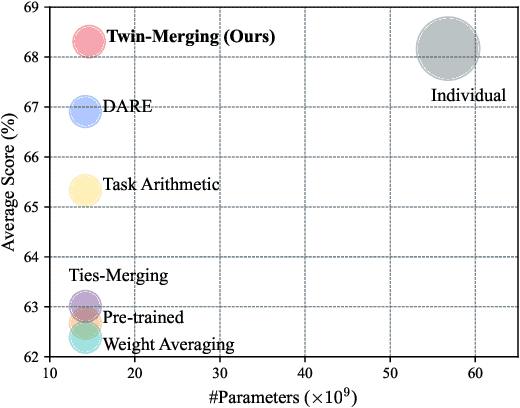
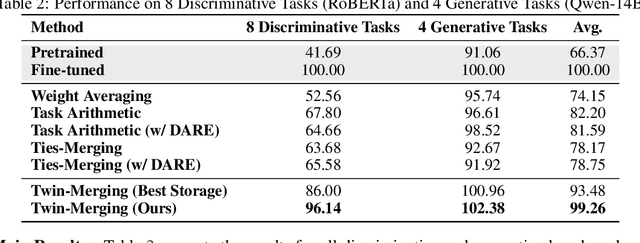
In the era of large language models, model merging is a promising way to combine multiple task-specific models into a single multitask model without extra training. However, two challenges remain: (a) interference between different models and (b) heterogeneous data during testing. Traditional model merging methods often show significant performance gaps compared to fine-tuned models due to these issues. Additionally, a one-size-fits-all model lacks flexibility for diverse test data, leading to performance degradation. We show that both shared and exclusive task-specific knowledge are crucial for merging performance, but directly merging exclusive knowledge hinders overall performance. In view of this, we propose Twin-Merging, a method that encompasses two principal stages: (1) modularizing knowledge into shared and exclusive components, with compression to reduce redundancy and enhance efficiency; (2) dynamically merging shared and task-specific knowledge based on the input. This approach narrows the performance gap between merged and fine-tuned models and improves adaptability to heterogeneous data. Extensive experiments on $12$ datasets for both discriminative and generative tasks demonstrate the effectiveness of our method, showing an average improvement of $28.34\%$ in absolute normalized score for discriminative tasks and even surpassing the fine-tuned upper bound on the generative tasks. (Our implementation is available in https://github.com/LZY-the-boys/Twin-Mergin.)
Mitigating Boundary Ambiguity and Inherent Bias for Text Classification in the Era of Large Language Models
Jun 11, 2024



Text classification is a crucial task encountered frequently in practical scenarios, yet it is still under-explored in the era of large language models (LLMs). This study shows that LLMs are vulnerable to changes in the number and arrangement of options in text classification. Our extensive empirical analyses reveal that the key bottleneck arises from ambiguous decision boundaries and inherent biases towards specific tokens and positions. To mitigate these issues, we make the first attempt and propose a novel two-stage classification framework for LLMs. Our approach is grounded in the empirical observation that pairwise comparisons can effectively alleviate boundary ambiguity and inherent bias. Specifically, we begin with a self-reduction technique to efficiently narrow down numerous options, which contributes to reduced decision space and a faster comparison process. Subsequently, pairwise contrastive comparisons are employed in a chain-of-thought manner to draw out nuances and distinguish confusable options, thus refining the ambiguous decision boundary. Extensive experiments on four datasets (Banking77, HWU64, LIU54, and Clinic150) verify the effectiveness of our framework. Furthermore, benefitting from our framework, various LLMs can achieve consistent improvements. Our code and data are available in \url{https://github.com/Chuge0335/PC-CoT}.
Improving Low-resource Prompt-based Relation Representation with Multi-view Decoupling Learning
Jan 15, 2024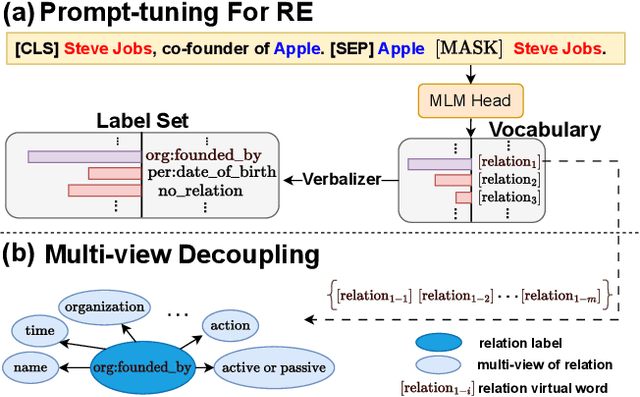
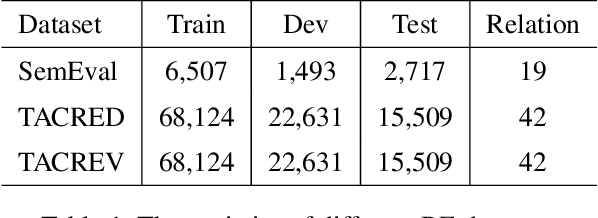
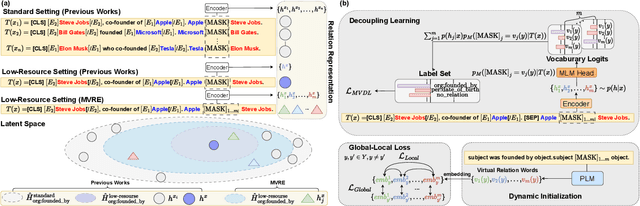
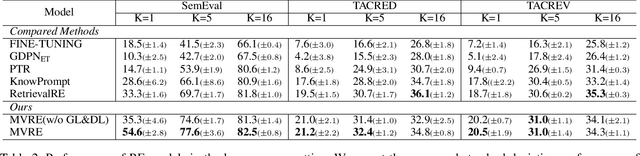
Recently, prompt-tuning with pre-trained language models (PLMs) has demonstrated the significantly enhancing ability of relation extraction (RE) tasks. However, in low-resource scenarios, where the available training data is scarce, previous prompt-based methods may still perform poorly for prompt-based representation learning due to a superficial understanding of the relation. To this end, we highlight the importance of learning high-quality relation representation in low-resource scenarios for RE, and propose a novel prompt-based relation representation method, named MVRE (\underline{M}ulti-\underline{V}iew \underline{R}elation \underline{E}xtraction), to better leverage the capacity of PLMs to improve the performance of RE within the low-resource prompt-tuning paradigm. Specifically, MVRE decouples each relation into different perspectives to encompass multi-view relation representations for maximizing the likelihood during relation inference. Furthermore, we also design a Global-Local loss and a Dynamic-Initialization method for better alignment of the multi-view relation-representing virtual words, containing the semantics of relation labels during the optimization learning process and initialization. Extensive experiments on three benchmark datasets show that our method can achieve state-of-the-art in low-resource settings.
MIRACLE: Towards Personalized Dialogue Generation with Latent-Space Multiple Personal Attribute Control
Oct 22, 2023Personalized dialogue systems aim to endow the chatbot agent with more anthropomorphic traits for human-like interactions. Previous approaches have explored explicitly user profile modeling using text descriptions, implicit derivation of user embeddings, or utilizing handicraft prompts for ChatGPT-like models. However, textual personas are limited in describing multi-faceted attributes (\emph{e.g.}, \emph{language style, inner character nuances}), implicit embedding suffers from personality sparsity, and handicraft prompts lack fine-grained and stable controllability. Hence, these approaches may struggle with complex personalized dialogue generation tasks that require generating controllable responses with multiple personal attributes. To this end, we propose \textbf{\textsc{Miracle}}, a novel personalized dialogue generation method through \textbf{M}ult\textbf{I}ple Pe\textbf{R}sonal \textbf{A}ttributes \textbf{C}ontrol within \textbf{L}atent-Space \textbf{E}nergy-based Models. ttributes \textbf{C}ontrol within \textbf{L}atent-Space \textbf{E}nergy-based Models. Specifically, our approach first disentangles complex personality into multi-faceted attributes. Subsequently, we employ a conditional variational auto-encoder to align with the dense personalized responses within a latent joint attribute space. We have also tailored a dedicated energy function and customized the ordinary differential equations sampling method to offer flexible attribute composition and precise attribute control. Extensive experiments demonstrate that \textsc{Miracle} outperforms several strong baselines in terms of personality controllability and response generation quality. Our dataset and code are available at \url{https://github.com/LZY-the-boys/MIRACLE}