 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Giant's Shoulders: Effortless Weak to Strong by Dynamic Logits Fusion
Paper and Code
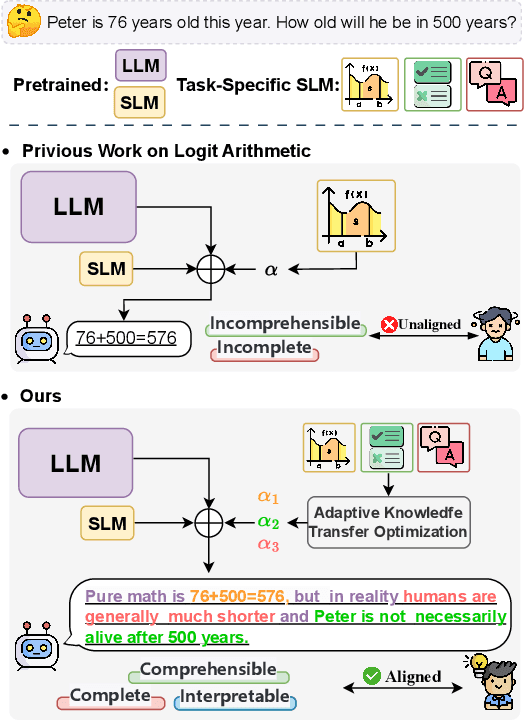
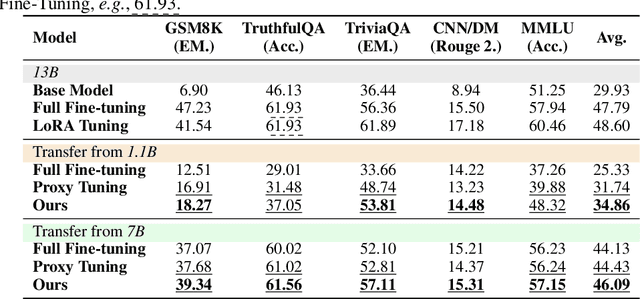
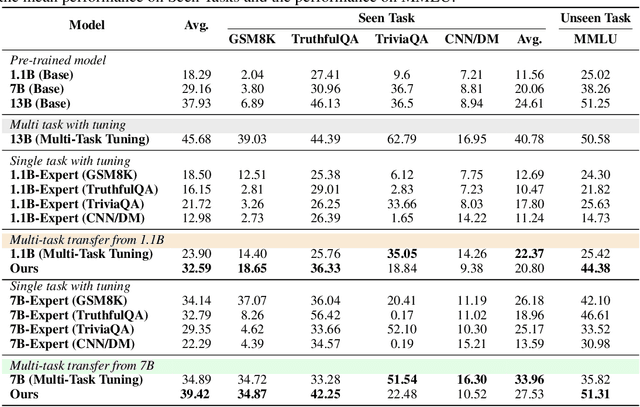
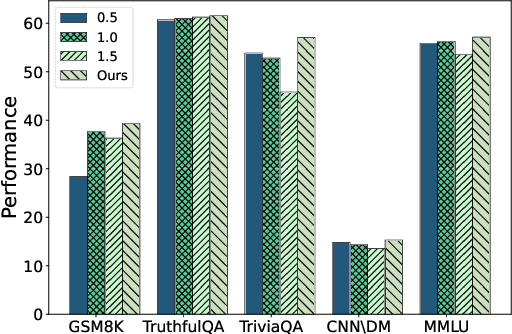
Efficient fine-tuning of large language models for task-specific applications is imperative, yet the vast number of parameters in these models makes their training increasingly challenging. Despite numerous proposals for effective methods, a substantial memory overhead remains for gradient computations during updates. \thm{Can we fine-tune a series of task-specific small models and transfer their knowledge directly to a much larger model without additional training?} In this paper, we explore weak-to-strong specialization using logit arithmetic, facilitating a direct answer to this question. Existing weak-to-strong methods often employ a static knowledge transfer ratio and a single small model for transferring complex knowledge, which leads to suboptimal performance. % To address this, To surmount these limitations, we propose a dynamic logit fusion approach that works with a series of task-specific small models, each specialized in a different task. This method adaptively allocates weights among these models at each decoding step, learning the weights through Kullback-Leibler divergence constrained optimization problems. We conduct extensive experiments across various benchmarks in both single-task and multi-task settings, achieving leading results. By transferring expertise from the 7B model to the 13B model, our method closes the performance gap by 96.4\% in single-task scenarios and by 86.3\% in multi-task scenarios compared to full fine-tuning of the 13B model. Notably, we achieve surpassing performance on unseen tasks. Moreover, we further demonstrate that our method can effortlessly integrate in-context learning for single tasks and task arithmetic for multi-task scenarios. (Our implementation is available in https://github.com/Facico/Dynamic-Logit-Fusion.)