 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemGovern: Enhancing Code Agents through Learning from Governed Human Experiences
Jan 13, 2026While autonomous software engineering (SWE) agents are reshaping programming paradigms, they currently suffer from a "closed-world" limitation: they attempt to fix bugs from scratch or solely using local context, ignoring the immense historical human experience available on platforms like GitHub. Accessing this open-world experience is hindered by the unstructured and fragmented nature of real-world issue-tracking data. In this paper, we introduce MemGovern, a framework designed to govern and transform raw GitHub data into actionable experiential memory for agents. MemGovern employs experience governance to convert human experience into agent-friendly experience cards and introduces an agentic experience search strategy that enables logic-driven retrieval of human expertise. By producing 135K governed experience cards, MemGovern achieves a significant performance boost, improving resolution rates on the SWE-bench Verified by 4.65%. As a plug-in approach, MemGovern provides a solution for agent-friendly memory infrastructure.
LogicLens: Visual-Logical Co-Reasoning for Text-Centric Forgery Analysis
Dec 25, 2025Sophisticated text-centric forgeries, fueled by rapid AIGC advancements, pose a significant threat to societal security and information authenticity. Current methods for text-centric forgery analysis are often limited to coarse-grained visual analysis and lack the capacity for sophisticated reasoning. Moreover, they typically treat detection, grounding, and explanation as discrete sub-tasks, overlooking their intrinsic relationships for holistic performance enhancement. To address these challenges, we introduce LogicLens, a unified framework for Visual-Textual Co-reasoning that reformulates these objectives into a joint task. The deep reasoning of LogicLens is powered by our novel Cross-Cues-aware Chain of Thought (CCT) mechanism, which iteratively cross-validates visual cues against textual logic. To ensure robust alignment across all tasks, we further propose a weighted multi-task reward function for GRPO-based optimization. Complementing this framework, we first designed the PR$^2$ (Perceiver, Reasoner, Reviewer) pipeline, a hierarchical and iterative multi-agent system that generates high-quality, cognitively-aligned annotations. Then, we constructed RealText, a diverse dataset comprising 5,397 images with fine-grained annotations, including textual explanations, pixel-level segmentation, and authenticity labels for model training. Extensive experiments demonstrate the superiority of LogicLens across multiple benchmarks. In a zero-shot evaluation on T-IC13, it surpasses the specialized framework by 41.4% and GPT-4o by 23.4% in macro-average F1 score. Moreover, on the challenging dense-text T-SROIE dataset, it establishes a significant lead over other MLLM-based methods in mF1, CSS, and the macro-average F1. Our dataset, model, and code will be made publicly available.
Training a Utility-based Retriever Through Shared Context Attribution for Retrieval-Augmented Language Models
Apr 01, 2025Retrieval-Augmented Language Models boost task performance, owing to the retriever that provides external knowledge. Although crucial, the retriever primarily focuses on semantics relevance, which may not always be effective for generation. Thus, utility-based retrieval has emerged as a promising topic, prioritizing passages that provides valid benefits for downstream tasks. However, due to insufficient understanding, capturing passage utility accurately remains unexplored. This work proposes SCARLet, a framework for training utility-based retrievers in RALMs, which incorporates two key factors, multi-task generalization and inter-passage interaction. First, SCARLet constructs shared context on which training data for various tasks is synthesized. This mitigates semantic bias from context differences, allowing retrievers to focus on learning task-specific utility for better task generalization. Next, SCARLet uses a perturbation-based attribution method to estimate passage-level utility for shared context, which reflects interactions between passages and provides more accurate feedback. We evaluate our approach on ten datasets across various tasks, both in-domain and out-of-domain, showing that retrievers trained by SCARLet consistently improve the overall performance of RALMs.
An Analysis for Image-to-Image Translation and Style Transfer
Aug 12, 2024



With the development of generative technologies in deep learning, a large number of image-to-image translation and style transfer models have emerged at an explosive rate in recent years. These two technologies have made significant progress and can generate realistic images. However, many communities tend to confuse the two, because both generate the desired image based on the input image and both cover the two definitions of content and style. In fact, there are indeed significant differences between the two, and there is currently a lack of clear explanations to distinguish the two technologies, which is not conducive to the advancement of technology. We hope to serve the entire community by introducing the differences and connections between image-to-image translation and style transfer. The entire discussion process involves the concepts, forms, training modes, evaluation processes, and visualization results of the two technologies. Finally, we conclude that image-to-image translation divides images by domain, and the types of images in the domain are limited, and the scope involved is small, but the conversion ability is strong and can achieve strong semantic changes. Style transfer divides image types by single image, and the scope involved is large, but the transfer ability is limited, and it transfers more texture and color of the image.
ALiiCE: Evaluating Positional Fine-grained Citation Generation
Jun 19, 2024



Large Language Models (LLMs) can enhance the credibility and verifiability by generating text with citations. However, existing tasks and evaluation methods are predominantly limited to sentence-level statement, neglecting the significance of positional fine-grained citations that can appear anywhere within sentences. To facilitate further exploration of the fine-grained citation generation, we propose ALiiCE, the first automatic evaluation framework for this task. Our framework first parses the sentence claim into atomic claims via dependency analysis and then calculates citation quality at the atomic claim level. ALiiCE introduces three novel metrics for positional fined-grained citation quality assessment, including positional fine-grained citation recall and precision, and coefficient of variation of citation positions. We evaluate the positional fine-grained citation generation performance of several LLMs on two long-form QA datasets. Our experiments and analyses demonstrate the effectiveness and reasonableness of ALiiCE. The results also indicate that existing LLMs still struggle to provide positional fine-grained citations.
REPARO: Compositional 3D Assets Generation with Differentiable 3D Layout Alignment
May 28, 2024



Traditional image-to-3D models often struggle with scenes containing multiple objects due to biases and occlusion complexities. To address this challenge, we present REPARO, a novel approach for compositional 3D asset generation from single images. REPARO employs a two-step process: first, it extracts individual objects from the scene and reconstructs their 3D meshes using off-the-shelf image-to-3D models; then, it optimizes the layout of these meshes through differentiable rendering techniques, ensuring coherent scene composition. By integrating optimal transport-based long-range appearance loss term and high-level semantic loss term in the differentiable rendering, REPARO can effectively recover the layout of 3D assets. The proposed method can significantly enhance object independence, detail accuracy, and overall scene coherence. Extensive evaluation of multi-object scenes demonstrates that our REPARO offers a comprehensive approach to address the complexities of multi-object 3D scene generation from single images.
Toward Zero-Shot Unsupervised Image-to-Image Translation
Jul 28, 2020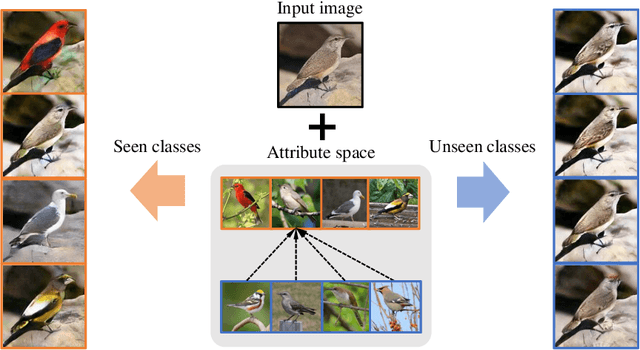
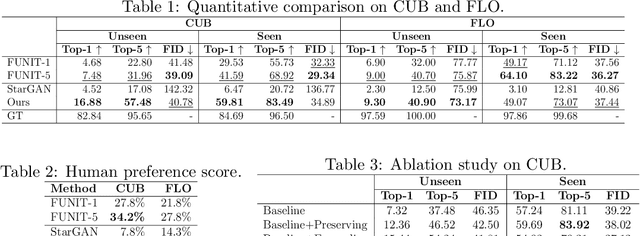
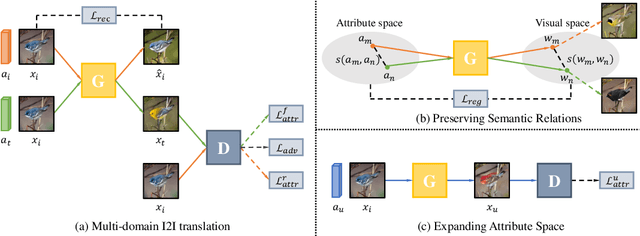

Recent studies have shown remarkable success in unsupervised image-to-image translation. However, if there has no access to enough images in target classes, learning a mapping from source classes to the target classes always suffers from mode collapse, which limits the application of the existing methods. In this work, we propose a zero-shot unsupervised image-to-image translation framework to address this limitation, by associating categories with their side information like attributes. To generalize the translator to previous unseen classes, we introduce two strategies for exploiting the space spanned by the semantic attributes. Specifically, we propose to preserve semantic relations to the visual space and expand attribute space by utilizing attribute vectors of unseen classes, thus encourage the translator to explore the modes of unseen classes. Quantitative and qualitative results on different datasets demonstrate the effectiveness of our proposed approach. Moreover, we demonstrate that our framework can be applied to many tasks, such as zero-shot classification and fashion design.
Deep Image Spatial Transformation for Person Image Generation
Mar 18, 2020



Pose-guided person image generation is to transform a source person image to a target pose. This task requires spatial manipulations of source data. However, Convolutional Neural Networks are limited by the lack of ability to spatially transform the inputs. In this paper, we propose a differentiable global-flow local-attention framework to reassemble the inputs at the feature level. Specifically, our model first calculates the global correlations between sources and targets to predict flow fields. Then, the flowed local patch pairs are extracted from the feature maps to calculate the local attention coefficients. Finally, we warp the source features using a content-aware sampling method with the obtained local attention coefficients. The results of both subjective and objective experiments demonstrate the superiority of our model. Besides, additional results in video animation and view synthesis show that our model is applicable to other tasks requiring spatial transformation. Our source code is available at https://github.com/RenYurui/Global-Flow-Local-Attention.
Multi-mapping Image-to-Image Translation via Learning Disentanglement
Sep 17, 2019
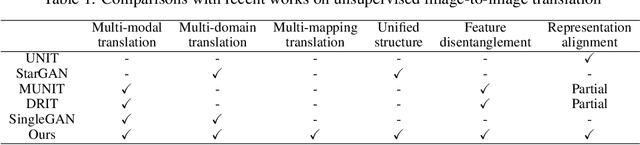


Recent advances of image-to-image translation focus on learning the one-to-many mapping from two aspects: multi-modal translation and multi-domain translation. However, the existing methods only consider one of the two perspectives, which makes them unable to solve each other's problem. To address this issue, we propose a novel unified model, which bridges these two objectives. First, we disentangle the input images into the latent representations by an encoder-decoder architecture with a conditional adversarial training in the feature space. Then, we encourage the generator to learn multi-mappings by a random cross-domain translation. As a result, we can manipulate different parts of the latent representations to perform multi-modal and multi-domain translations simultaneously. Experiments demonstrate that our method outperforms state-of-the-art methods.
StructureFlow: Image Inpainting via Structure-aware Appearance Flow
Aug 11, 2019
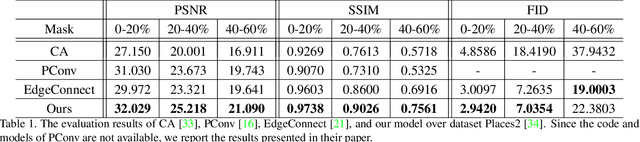
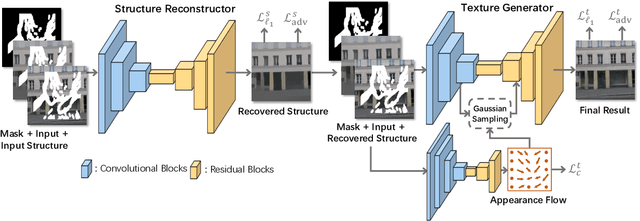
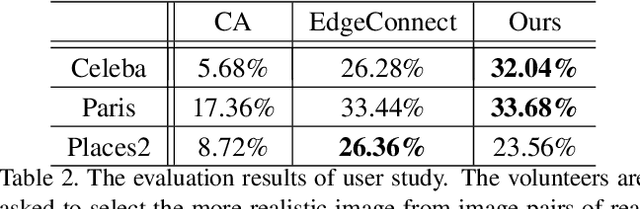
Image inpainting techniques have shown significant improvements by using deep neural networks recently. However, most of them may either fail to reconstruct reasonable structures or restore fine-grained textures. In order to solve this problem, in this paper, we propose a two-stage model which splits the inpainting task into two parts: structure reconstruction and texture generation. In the first stage, edge-preserved smooth images are employed to train a structure reconstructor which completes the missing structures of the inputs. In the second stage, based on the reconstructed structures, a texture generator using appearance flow is designed to yield image details. Experiments on multiple publicly available datasets show the superior performance of the proposed network.