 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLogicLens: Visual-Logical Co-Reasoning for Text-Centric Forgery Analysis
Dec 25, 2025Sophisticated text-centric forgeries, fueled by rapid AIGC advancements, pose a significant threat to societal security and information authenticity. Current methods for text-centric forgery analysis are often limited to coarse-grained visual analysis and lack the capacity for sophisticated reasoning. Moreover, they typically treat detection, grounding, and explanation as discrete sub-tasks, overlooking their intrinsic relationships for holistic performance enhancement. To address these challenges, we introduce LogicLens, a unified framework for Visual-Textual Co-reasoning that reformulates these objectives into a joint task. The deep reasoning of LogicLens is powered by our novel Cross-Cues-aware Chain of Thought (CCT) mechanism, which iteratively cross-validates visual cues against textual logic. To ensure robust alignment across all tasks, we further propose a weighted multi-task reward function for GRPO-based optimization. Complementing this framework, we first designed the PR$^2$ (Perceiver, Reasoner, Reviewer) pipeline, a hierarchical and iterative multi-agent system that generates high-quality, cognitively-aligned annotations. Then, we constructed RealText, a diverse dataset comprising 5,397 images with fine-grained annotations, including textual explanations, pixel-level segmentation, and authenticity labels for model training. Extensive experiments demonstrate the superiority of LogicLens across multiple benchmarks. In a zero-shot evaluation on T-IC13, it surpasses the specialized framework by 41.4% and GPT-4o by 23.4% in macro-average F1 score. Moreover, on the challenging dense-text T-SROIE dataset, it establishes a significant lead over other MLLM-based methods in mF1, CSS, and the macro-average F1. Our dataset, model, and code will be made publicly available.
A Survey on Deep Learning-based Spatio-temporal Action Detection
Aug 03, 2023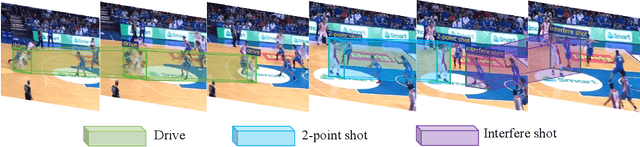
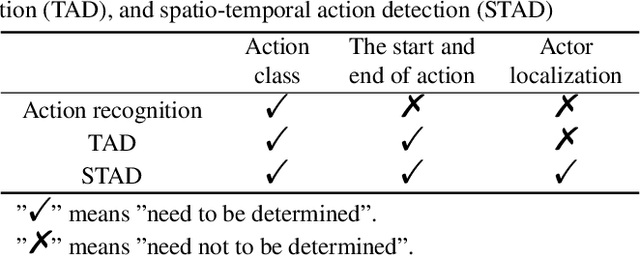
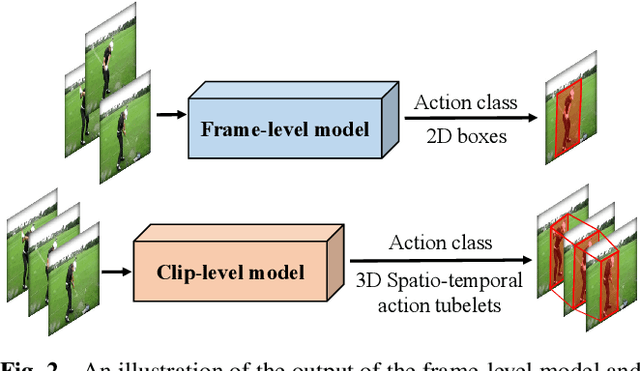

Spatio-temporal action detection (STAD) aims to classify the actions present in a video and localize them in space and time. It has become a particularly active area of research in computer vision because of its explosively emerging real-world applications, such as autonomous driving, visual surveillance, entertainment, etc. Many efforts have been devoted in recent years to building a robust and effective framework for STAD. This paper provides a comprehensive review of the state-of-the-art deep learning-based methods for STAD. Firstly, a taxonomy is developed to organize these methods. Next, the linking algorithms, which aim to associate the frame- or clip-level detection results together to form action tubes, are reviewed. Then, the commonly used benchmark datasets and evaluation metrics are introduced, and the performance of state-of-the-art models is compared. At last, this paper is concluded, and a set of potential research directions of STAD are discussed.